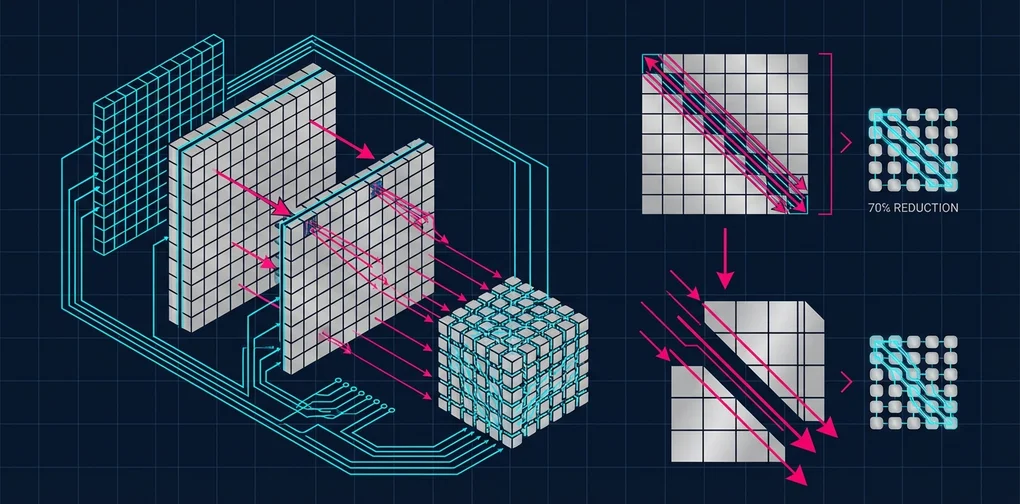
Heretic 1.2: 70% VRAM Reduction via Quantization and MPOA Explained
Heretic 1.2 is here with 4-bit quantization cutting VRAM usage by up to 70% and MPOA delivering higher-quality abliteration. A deep dive into the latest cost-saving techniques for local LLM operations.
Overview
When running local LLMs, VRAM shortage remains the biggest bottleneck. Abliteration (censorship removal) of large models typically requires loading the full model in full precision, consuming tens of gigabytes of VRAM.
In February 2026, Heretic 1.2 was released. Earning 268 points on Reddit r/LocalLLaMA, it received strong community recognition. This version introduces up to 70% VRAM reduction through 4-bit quantization and a new abliteration technique called Magnitude-Preserving Orthogonal Ablation (MPOA).
What Is Heretic
Heretic is a tool that automatically removes censorship (safety alignment) from transformer-based language models. Within three months of its initial release, the community has published over 1,300 models using Heretic.
Heretic’s core technology relies on two pillars:
- Directional Ablation: Removing specific directional vectors from the model to disable restrictions
- TPE-based Parameter Optimization: Using Optuna to co-minimize refusal count and KL divergence
graph TD
A[Original Model] --> B[Identify Restriction<br/>Direction Vectors]
B --> C[Directional Ablation]
C --> D[Optuna Parameter<br/>Optimization]
D --> E{Quality Check}
E -->|Low Refusal + Low KL| F[High-Quality<br/>Unrestricted Model]
E -->|Insufficient Quality| D70% VRAM Reduction: LoRA-Based Quantization Engine
The Previous Challenge
Traditional abliteration required loading the entire model in full precision (FP16/BF16) into VRAM. For a 70B parameter model, this means approximately 140GB of VRAM. Unlike hardware-level approaches such as NVFP4 quantization, Heretic addresses the same problem at the software layer.
The New Approach
Heretic 1.2 introduces a LoRA-based abliteration engine implemented by contributor accemlcc.
# Heretic configuration example
quantization: bnb_4bit # Enable 4-bit quantization
orthogonalize_direction: true # Enable MPOA
row_normalization: full # Row normalizationHere’s how this approach works:
- 4-bit Quantized Loading: Using bitsandbytes to load the model in 4-bit, reducing VRAM usage by up to 70%
- LoRA Adapter Optimization: PEFT-based optimization of abliteration parameters in the quantized state
- Full Precision Export: Re-loading the original model in system RAM and applying the optimized LoRA adapter
graph LR
A[Model<br/>FP16 140GB] -->|4-bit Quantize| B[Quantized Model<br/>4-bit ~35GB]
B -->|LoRA Optimization| C[LoRA Adapter<br/>Few MB]
D[Original Model<br/>System RAM] -->|Apply LoRA| E[Unrestricted Model<br/>FP16 Full Precision]
C --> EReal-World VRAM Comparison
| Model Size | Traditional | Heretic 1.2 (4-bit) | Reduction |
|---|---|---|---|
| 7B | ~14GB | ~4.2GB | 70% |
| 13B | ~26GB | ~7.8GB | 70% |
| 70B | ~140GB | ~42GB | 70% |
Consumer GPUs (RTX 4090, 24GB VRAM) can now process 13B-class models.
MPOA: A New Technique for High-Quality Abliteration
What Is Magnitude-Preserving Orthogonal Ablation
MPOA is an abliteration technique developed by Jim Lai that minimizes quality degradation compared to conventional methods.
Traditional abliteration changes the magnitude (norm) of weights when removing restriction direction vectors, degrading model capabilities. MPOA solves this with:
- Orthogonal Projection: Projecting vectors onto a subspace orthogonal to the restriction direction
- Norm Preservation: Restoring the norm of projected vectors to their original magnitude
- Optuna Optimization: Using Optuna to optimize weight parameters and automate layer selection
Benchmark Comparison
From Heretic’s official example, comparing results on the gpt-oss-20b model:
| Model | UGI Score | W/10 | NatInt | Writing |
|---|---|---|---|---|
| Heretic Version (MPOA) | 39.05 | Win | Win | Win |
| Traditional Derestricted | 34.22 | — | — | — |
The Heretic version outperforms across all categories, achieving approximately 14% improvement in UGI score.
Configuration
# Enable MPOA
orthogonalize_direction: true
row_normalization: fullJust two lines of configuration to benefit from MPOA.
Other Notable Features
Vision Language Model (VLM) Support
Heretic 1.2 adds VLM support thanks to contributor anrp. Only the text decoder portion is abliterated while the image encoder remains intact.
Automatic Session Save and Resume
Even if a crash occurs during a long optimization run, Heretic automatically saves progress. Upon restart, it resumes from where it left off. You can also manually interrupt with Ctrl+C and resume later.
Practical Guide: Using Heretic 1.2
Prerequisites
- Python 3.10+
- CUDA-capable GPU (NVIDIA GPU required for 4-bit quantization)
- Sufficient system RAM (for full precision export)
Installation and Execution
# Install Heretic
pip install heretic
# Basic run (4-bit quantization + MPOA)
heretic --model meta-llama/Llama-3.1-8B-Instruct \
--quantization bnb_4bit \
--orthogonalize-direction true \
--row-normalization fullRecommended Hardware Configurations
graph TD
subgraph Consumer
A[RTX 4090<br/>24GB VRAM] -->|4-bit Quantize| B[Up to 13B Models]
end
subgraph Prosumer
C[RTX 5090<br/>32GB VRAM] -->|4-bit Quantize| D[Up to 20B Models]
end
subgraph Server
E[A100 80GB] -->|4-bit Quantize| F[Up to 70B Models]
endCommunity Response
The Reddit r/LocalLLaMA post earned 268 points, reflecting strong community approval. On HuggingFace, over 1,300 models created with Heretic have been published, representing more than a third of all abliterated models.
Key highlights from the community:
- Cost Efficiency: Large model processing now possible on consumer GPUs
- Quality Improvement: MPOA surpasses conventional techniques
- Ease of Use: Fully automated workflow
Conclusion
Heretic 1.2 simultaneously solves two major challenges in local LLM operations:
- Dramatic VRAM Reduction: 4-bit quantization makes previously expensive GPU-dependent processing feasible on consumer hardware
- Improved Abliteration Quality: MPOA removes restrictions while preserving model capabilities
As the democratization of local LLMs accelerates, tools like Heretic play a crucial role in building an environment where anyone can leverage high-quality models.
References
Was this helpful?
Your support helps me create better content. Buy me a coffee.
Related Articles
-
DeNA LLM Study Part 3: Model Training Methodologies - From Pre-training to RLHF/DPO
Covers similar topics in AI/ML with comparable difficulty.
-
Verbalized Sampling: A Training-Free Prompting Technique to Restore LLM Diversity
Covers similar topics in AI/ML with comparable difficulty.

-
MiniMax M2.5: The Performance Gap Between Open-Weight and Proprietary Models Hits an All-Time Low
Useful as prerequisite knowledge, covering AI/ML fundamentals.
