Same Article, 1.4x the Tokens in Korean: Measuring the Non-English Token Tax Across 285 of My Posts
I tokenized 285 of my posts across ko/ja/en/zh with three tokenizers. Korean ran 1.38x English tokens, Japanese 1.34x. The non-English token tax, measured.
I fed one English sentence in. “I refactored the agent loop to cut token usage.” Twelve tokens under OpenAI’s o200k_base. Then the same meaning in Korean: “토큰 사용량을 줄이려고 에이전트 루프를 다시 짰다.” Twenty tokens. Less than half the characters, but 1.7x the tokens.
I wanted to know whether that was a fluke of one sentence or a structural cost baked into my entire blog. I happened to have the perfect test bed. This blog ships every article in four versions: Korean, Japanese, English, Chinese. That means 285 pairs of semantically identical documents across four languages. A dataset where I can cleanly measure how many more tokens the same content costs when only the language changes, with no translation-quality argument in the way.
So I tokenized all 285 articles times four languages with three real tokenizers. Up front: the non-English token tax is real, it’s bigger than I expected, and switching models changes the rate.
Why I had to measure this myself
“Korean costs more tokens than English” is folklore in the community. But ask “how much more” and you get scattered answers. Some say 2x, some say 1.2x. Of course they differ. The text measured was different, the tokenizer was different, and whether code blocks were mixed in was different too.
What I needed wasn’t a floating number but the cost that lands when my blog runs through the models I actually use. Translation, summarization, embedding, RAG context injection: nearly every step of my automation pipeline is metered in tokens. If Korean costs 1.4x English, that’s a number printed straight onto my monthly bill.
I picked three tokenizers as targets. The modern OpenAI line, o200k_base (GPT-4o / GPT-5 generation); the older cl100k_base (GPT-4 / 3.5 generation); and the Claude tokenizer. All three are BPE family, but they learned vocabulary from different data, so they handle non-English differently. The models I reach for daily fall roughly into these three buckets.
How I measured it (frontmatter stripped, full body in)
No fancy tooling. tiktoken runs offline out of the box, and I loaded the Claude tokenizer from Hugging Face’s Xenova/claude-tokenizer. For each Markdown file I cut only the YAML frontmatter and tokenized the entire body (code blocks included). What actually goes into an LLM is the whole body, so I deliberately left it unclean.
import tiktoken
from transformers import AutoTokenizer
o200k = tiktoken.get_encoding('o200k_base') # GPT-4o / GPT-5 gen
cl100k = tiktoken.get_encoding('cl100k_base') # GPT-4 / 3.5 gen
claude = AutoTokenizer.from_pretrained('Xenova/claude-tokenizer')
def strip_frontmatter(text):
if text.startswith('---'):
end = text.find('\n---', 3)
if end != -1:
text = text[end + 4:]
return text.strip()
# only slugs present in all four languages (285 sets)
for lang in ['ko', 'ja', 'en', 'zh']:
body = strip_frontmatter(open(path(lang, slug)).read())
o200k_tokens = len(o200k.encode(body))
cl100k_tokens = len(cl100k.encode(body))
claude_tokens = len(claude.encode(body))I only counted the 285 articles that have the same filename in all four languages. That removes any sampling imbalance from articles that exist in English but not Korean. It’s a strict 1:1:1:1 comparison of the same article’s four versions.
What the numbers say
Totals across all 285 articles. Unit is tokens.
| Language | o200k (modern) | cl100k (older) | Claude | Characters |
|---|---|---|---|---|
| English (en) | 908,938 | 915,128 | 1,003,948 | 3,859,685 |
| Chinese (zh) | 1,045,977 | 1,267,007 | 1,340,943 | 2,493,687 |
| Japanese (ja) | 1,217,284 | 1,502,403 | 1,579,075 | 2,584,255 |
| Korean (ko) | 1,256,718 | 1,668,007 | 1,882,800 | 3,076,489 |
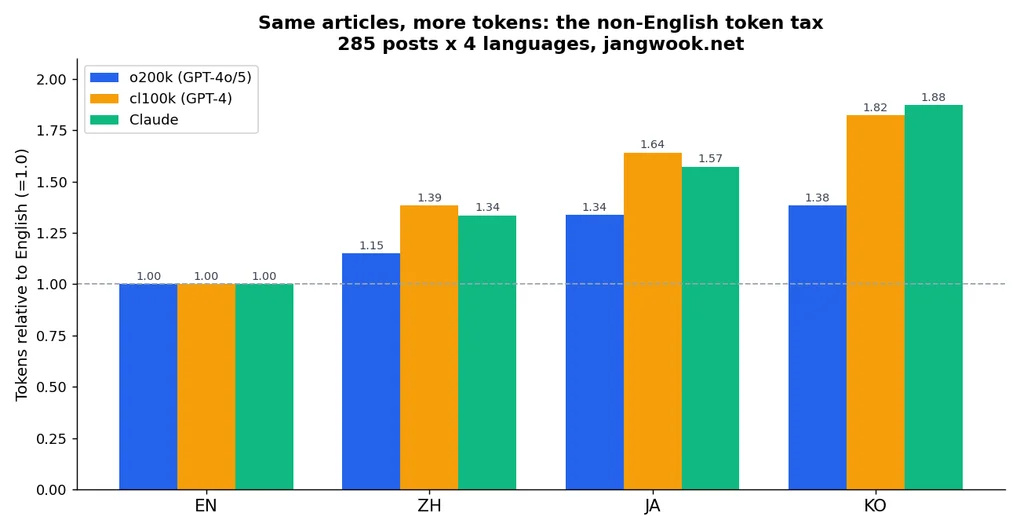
Set English to 1.0 and the tax snaps into focus.
| Language | o200k ratio | cl100k ratio | Claude ratio |
|---|---|---|---|
| English | 1.00 | 1.00 | 1.00 |
| Chinese | 1.15 | 1.39 | 1.34 |
| Japanese | 1.34 | 1.64 | 1.57 |
| Korean | 1.38 | 1.82 | 1.88 |
Even on the modern tokenizer (o200k), Korean is 1.38x English and Japanese 1.34x. On the older one (cl100k), Korean stretches to 1.82x. On the Claude tokenizer, Korean is the most expensive of the three at 1.88x.
The part I found striking is that character count and token count pull apart. The English versions are the longest by characters, at 3.86M. Korean is shorter at 3.08M. Yet Korean uses 38% more tokens. Fewer characters, more tokens. By tokens-per-character: English 0.235, Korean 0.408, Chinese 0.419, Japanese 0.471. English BPE crams common words into a single token each, but Hangul, kana, and Han characters weren’t learned that way, so they shatter into more tokens.
Why Korean eats more tokens: I cut “에이전트” apart
I wanted to see the cause with my own eyes, so I fed one word to the tokenizer and decoded how it splits.
w = "에이전트" # = agent
[o200k.decode([t]) for t in o200k.encode(w)]
# ['에', '이', '전', '트'] -> 4 tokensEnglish “agent” is one token. Korean “에이전트” splits into four tokens, one per syllable block. cl100k gave the same result. In English a word is roughly a token; in Korean a character (syllable block) is closer to a token. That 4:1 gap on a single word, accumulated across a whole article, becomes 1.4x.
One short sentence across all three tokenizers makes it even clearer. Every version means “I refactored the agent loop to cut token usage.”
| Language | Chars | o200k | cl100k | Claude |
|---|---|---|---|---|
| English | 47 | 12 | 12 | 12 |
| Chinese | 19 | 14 | 24 | 21 |
| Japanese | 30 | 22 | 28 | 27 |
| Korean | 28 | 20 | 31 | 32 |
English is 12 across all three. Once you go non-English, the tokenizers diverge. The same Korean sentence is 20 on o200k and 32 on Claude. A 1.6x swing decided by one model choice.
Japanese has its own texture. By tokens-per-character it’s the highest of the three at 0.471. Han characters, hiragana, and katakana mix in a single sentence, and katakana loanwords (“エージェント”) split syllable by syllable. Yet by full-document total, Korean uses more tokens than Japanese. Japanese packs heavy meaning into single Han characters so documents come out shorter, while Korean documents are simply longer, so even with better per-character efficiency than Japanese it overtakes on total volume. Efficiency and total don’t point the same way.
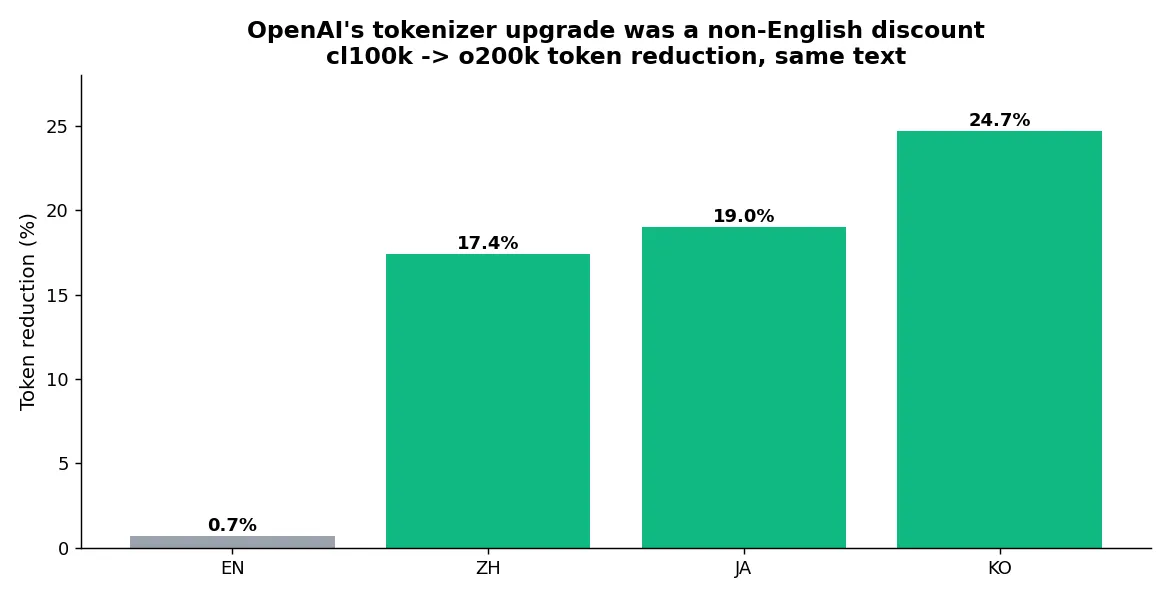
OpenAI’s tokenizer jump was really a non-English discount
This was the most unexpected find of the experiment. I computed how much each language’s token count dropped when the tokenizer moved from cl100k to o200k.
- English: down 0.7%
- Chinese: down 17.4%
- Japanese: down 19.0%
- Korean: down 24.7%
For English users, swapping tokenizers barely moves the count. 0.7% is noise. But Korean got a quarter cheaper on the same articles. What OpenAI actually did by growing the vocabulary for o200k was quietly hand non-English a discount. English was already near-optimal, so there was nothing left to squeeze.
This feeds a real decision. For a workload that runs a lot of CJK text, when you pick a model don’t just read benchmark scores; check the tokenizer generation too. Same price tag, but on non-English text the actual bill is decided by the tokenizer. My earlier measurement of how data formats move token cost taught the same lesson. A model’s price tag is only the start; the real cost is set by how the input turns into tokens.
The tax varies per article, so don’t trust the average
The totals are tidy, but split by article the variance is large. For each of the 285 articles I computed the Korean-to-English token ratio and took median and mean separately (o200k).
| Language | Per-article median | Per-article mean |
|---|---|---|
| Chinese | 1.10 | 1.14 |
| Japanese | 1.41 | 1.40 |
| Korean | 1.31 | 1.40 |
Korean has a median of 1.31 but a mean of 1.40. Mean above median means a handful of token-heavy articles drag the average up. Looking closer, those were articles dense in Korean prose with little English code or proper nouns. Tutorial articles full of code blocks sat near 1.1, because code is English anyway and tokenizes almost identically across all four versions.
A practical lesson: estimate one article’s cost from the corpus-average ratio and you’ll miss badly on prose-heavy, code-light pieces. For a single job where cost matters, tokenize that specific text.
So what shows up on my bill
This blog starts a new post from an English draft, renders it into three other languages, and embeds the whole corpus for related-post recommendations and search. Almost every step is token-metered.
Across the corpus, the 285 English versions are about 0.91M tokens on o200k. All four languages together are about 4.43M tokens. Versus running English-only, multilingual isn’t simply 4x; the non-English tax stacks on top. Look at just the three translations (ko+ja+zh) and it’s about 3.52M tokens, where estimating from three English copies (2.73M) would have undercounted by about 29%.
Here’s the mistake I kept making: eyeballing Korean cost from English token counts. That’s off by 28% even on a modern model, and nearly half on an older one. Quote in English, get billed in Korean, and the gap compounds every month.
Concretely: picture translating one new post from an English draft into Korean. The input is the English source (about 3,200 tokens) and the output is the Korean translation. The Korean output carries 1.38x the tokens for the same content. Output tokens usually cost more than input, so the non-English tax lands on the most expensive side. Push that into Japanese and Chinese and the tax applies three separate times. In my one-article-four-languages structure, non-English output tokens are a much bigger chunk of total publishing cost than English’s share. When I added Chinese and the article count quadrupled, the reason cost jumped by more than exactly 4x lives right here.
The fixes I’m making to shrink the tax. My recommendation pipeline resends the same context repeatedly, so I turned on prompt caching to keep the non-English tax from re-applying on every call. RAG chunks get cut by real token count, not character count. Invert the tokens-per-character figure and you get chunk size: with a 512-token embedding context, English fits about 2,170 characters but Korean hits the same limit at about 1,250. Cut Korean at the same “1,000 characters” as English and the chunk holds 1.7x the tokens, silently overrunning the context window or getting truncated. That’s exactly why I revisited chunk sizing in my Korean RAG embedding writeup.
Where this measurement doesn’t reach
Honest limits. First, token count is only one axis of cost. The same token has a different price per model, and input and output prices differ too. This post measured “how many tokens” only; “so how many dollars” you have to plug into your own model and plan.
Second, more tokens isn’t automatically a loss. CJK fits the same information into fewer characters. The proof is that the Korean versions have fewer characters than English yet carry the same meaning. Token efficiency and information density are separate stories.
Third, my corpus is a tech blog, so the bodies are heavy with English code, proper nouns, and technical terms. Pure everyday Korean prose could show a bigger multiplier. So this 1.38x is “my environment, technical-document baseline,” not a universal constant. If you want to dig deeper into tokenizer behavior, my post on BPE quantization and merging is an adjacent starting point.
Fourth, models keep changing. If the next tokenizer generation grows its CJK vocabulary, this gap narrows again. So the real conclusion here isn’t “Korean is 1.38x.” It’s “don’t estimate; run your own text through your own model’s tokenizer.” The code is all above. Wiring it to your own corpus takes about ten minutes.
Why this token-level sense of measuring and reproducing output matters runs through my experiment on output reproducibility with temperature and seed in the same spirit. Working with an LLM is, in the end, counting tokens. Knowing the counting unit differs by language before you start, versus finding out later, is the difference your monthly bill remembers.
References
- openai/tiktoken (GitHub) — OpenAI’s official fast BPE tokenizer. The
o200k_baseandcl100k_baseencodings I measured come straight from this library. - Anthropic — Token counting — official docs for counting tokens before a request, the right way to measure the Claude-side cost on your own text.
- Petrov et al., “Language Model Tokenizers Introduce Unfairness Between Languages” (arXiv:2305.15425) — NeurIPS 2023 paper showing the same text can cost up to 15x more tokens in some languages, the academic backbone for the tax measured here.
Frequently Asked Questions
Is the non-English token tax the same on every model?
Can I estimate Korean cost from English token counts?
What's the most practical way to cut the tax?
Was this helpful?
Your support helps me create better content. Buy me a coffee.
Related Articles
-
Stop Feeding Raw JSON to Your LLM — I Measured Token Cost Across 9 Data Formats
That post measured how data formats like JSON and CSV move token cost. If you saw here that language moves it, format is the other axis worth measuring together.

-
Does a Local LLM Ever Repeat Itself? Measuring Output Reproducibility with Temperature and Seed
A sibling experiment in the same local-LLM measurement series, testing output reproducibility across temperature and seed.

-
Testing Korean RAG Embeddings with sentence-transformers
If you plan to embed a Korean corpus for RAG, the token multiplier seen here flows straight into embedding-call cost and chunk sizing.
