Node.js Built-in SQLite: A Practical Guide — No npm Install Required
Node.js 22.5.0 ships node:sqlite, an built-in SQLite module requiring zero npm installs. DatabaseSync, StatementSync, transactions, and user-defined functions — tested hands-on with real logs.
Stop typing npm install sqlite3. There’s a better way now.
Since Node.js 22.5.0, a built-in node:sqlite module ships with Node itself. No installation, no package.json entry, no native build step. Just require('node:sqlite') and go. As of v22.22.0, it runs with an experimental warning. Node.js v26 stabilized it fully.
I spent time testing every API surface. Here’s what I found.
Why node:sqlite Matters
Dropping external packages isn’t just convenience. better-sqlite3 and sqlite3 need native bindings compiled via node-gyp. That build fails constantly on CI runners and Alpine Linux containers. node:sqlite embeds SQLite directly into the Node.js binary — no native compilation, no platform-specific failures.
Honestly, the experimental label on Node.js 22 does give me pause for production use. I’d wait until Node.js v26 hits LTS before deploying this in a real server. But for internal tooling, scripts, prototypes, and build tools? It’s solid right now.
How It Compares to better-sqlite3
One line: similar philosophy, smaller API surface.
- Both are synchronous only (no async/await)
- No
db.transaction()wrapper — this is the biggest gap (details below) db.function()anddb.aggregate()exist- No
serialize()/deserialize()for in-memory DB buffers
Getting Started: Zero Install
# Node.js 22.5.0+ required
node --version # v22.22.0
node -e "const {DatabaseSync} = require('node:sqlite'); console.log('OK');"
# (node:...) ExperimentalWarning: SQLite is an experimental feature and might change at any time
# OKSuppress the warning with --no-warnings or NODE_NO_WARNINGS=1.
Two classes drive everything:
DatabaseSync— the database connectionStatementSync— a compiled prepared statement
const { DatabaseSync } = require('node:sqlite');
const memDb = new DatabaseSync(':memory:'); // in-memory
const fileDb = new DatabaseSync('./my-app.db'); // file-based, auto-createdFull API Surface
I queried the prototype chain directly:
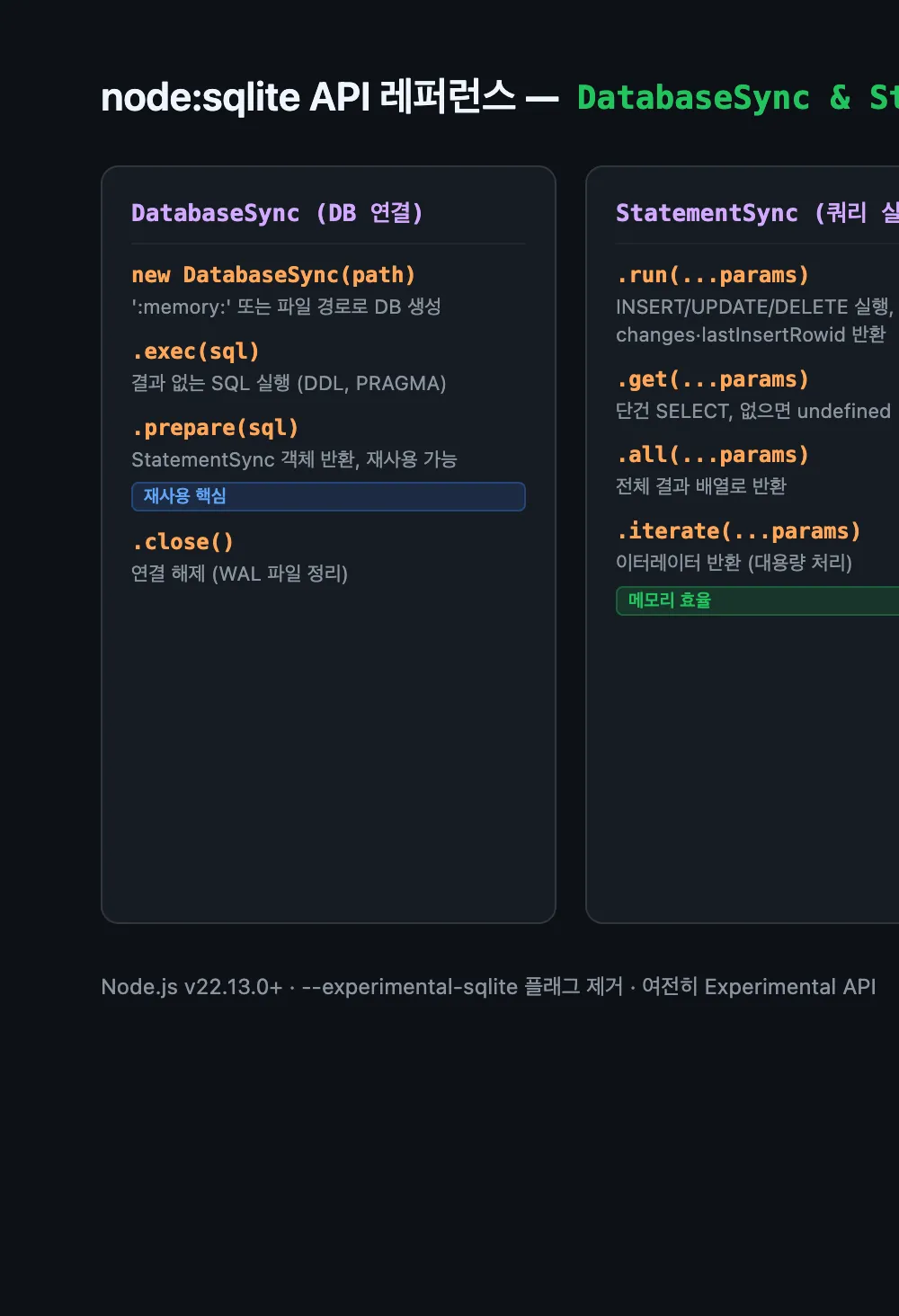
// DatabaseSync methods
// ['open', 'close', 'prepare', 'exec', 'function',
// 'location', 'aggregate', 'createSession',
// 'applyChangeset', 'enableLoadExtension', 'loadExtension']
// StatementSync methods
// ['iterate', 'all', 'get', 'run', 'columns',
// 'setAllowBareNamedParameters', 'setAllowUnknownNamedParameters',
// 'setReadBigInts', 'setReturnArrays']Familiar if you’ve used better-sqlite3. The gaps become visible only when you need them.
Basic CRUD
const { DatabaseSync } = require('node:sqlite');
const db = new DatabaseSync(':memory:');
db.exec(`
CREATE TABLE products (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL,
price REAL,
stock INTEGER DEFAULT 0
)
`);
// Prepared statement with named params
const insert = db.prepare(
'INSERT INTO products (name, price, stock) VALUES (:name, :price, :stock)'
);
// run() — returns { lastInsertRowid, changes }
const result = insert.run({ name: 'AirPods Pro', price: 249.99, stock: 50 });
console.log(result); // { lastInsertRowid: 1, changes: 1 }
insert.run({ name: 'MacBook Pro', price: 2499.99, stock: 10 });
insert.run({ name: 'iPad Air', price: 749.99, stock: 25 });
// all() — array of row objects
const rows = db.prepare('SELECT * FROM products ORDER BY price DESC').all();
// [{ id: 2, name: 'MacBook Pro', ... }, ...]
// get() — single row (undefined if not found)
const cheapest = db.prepare(
'SELECT * FROM products ORDER BY price ASC LIMIT 1'
).get();
console.log(cheapest.name, cheapest.price); // AirPods Pro 249.99
// iterate() — memory-efficient row-by-row access
for (const row of db.prepare('SELECT * FROM products').iterate()) {
console.log(row.id, row.name);
}
db.close();Both positional (?) and named (:name) parameters work. Named params win on readability for anything with 3+ fields.
Transactions: The Critical Difference
This is where better-sqlite3 migrants get tripped up first.
// ❌ This doesn't exist in node:sqlite
const insertMany = db.transaction((items) => { ... });No db.transaction(). You manage BEGIN/COMMIT/ROLLBACK explicitly through exec().
const { DatabaseSync } = require('node:sqlite');
const db = new DatabaseSync(':memory:');
db.exec('CREATE TABLE log (id INTEGER PRIMARY KEY AUTOINCREMENT, msg TEXT)');
const insert = db.prepare('INSERT INTO log (msg) VALUES (?)');
function insertBatch(messages) {
db.exec('BEGIN');
try {
for (const msg of messages) {
insert.run(msg);
}
db.exec('COMMIT');
return true;
} catch (e) {
db.exec('ROLLBACK');
throw e;
}
}
insertBatch(['server started', 'request received', 'response sent']);
const count = db.prepare('SELECT COUNT(*) as cnt FROM log').get();
console.log('Total:', count.cnt); // Total: 3
db.close();For cleaner code, extract a helper:
function withTransaction(db, fn) {
db.exec('BEGIN');
try {
const result = fn();
db.exec('COMMIT');
return result;
} catch (e) {
db.exec('ROLLBACK');
throw e;
}
}
withTransaction(db, () => {
insert.run('event one');
insert.run('event two');
});It’s more verbose than better-sqlite3. That’s the honest tradeoff for getting a zero-install database.
User-Defined Functions and Aggregates
You can call JavaScript functions from SQL. More useful than it sounds.
const { DatabaseSync } = require('node:sqlite');
const db = new DatabaseSync(':memory:');
db.exec('CREATE TABLE scores (player TEXT, score INTEGER)');
const ins = db.prepare('INSERT INTO scores VALUES (?, ?)');
ins.run('Alice', 1200);
ins.run('Bob', 850);
ins.run('Alice', 1050);
ins.run('Charlie', 950);
// Scalar function
db.function('double_score', (score) => score * 2);
const doubled = db.prepare(
'SELECT player, double_score(score) as ds FROM scores ORDER BY ds DESC'
).all();
console.log(doubled);
// [{ player: 'Alice', ds: 2400 }, { player: 'Alice', ds: 2100 }, ...]
// Custom aggregate
db.aggregate('weighted_avg', {
start: () => ({ sum: 0, count: 0 }),
step: (acc, val) => ({ sum: acc.sum + val, count: acc.count + 1 }),
result: (acc) => acc.count > 0 ? acc.sum / acc.count : 0,
});
const avg = db.prepare('SELECT weighted_avg(score) as avg FROM scores').get();
console.log('Average:', avg.avg); // Average: 1012.5
db.close();Date formatting, hashing, JSON parsing — anything you’d normally handle in application code can be pushed into the query. When building a Hono API server, this approach cuts down on post-query data transformation.
StatementSync Advanced Options
setAllowBareNamedParameters
Named parameters normally require colon prefixes in the object key. This lets you pass plain { key: val } instead.
const stmt = db.prepare('INSERT INTO kv VALUES (:key, :value)');
stmt.setAllowBareNamedParameters(true);
stmt.run({ key: 'hello', value: 'world' }); // No { ':key': 'hello' } neededsetAllowUnknownNamedParameters
Ignore extra object keys that don’t map to query parameters. Useful when passing a large object with only some fields relevant to the query.
const stmt = db.prepare('SELECT * FROM kv WHERE key = :key');
stmt.setAllowUnknownNamedParameters(true);
const row = stmt.get({ key: 'hello', irrelevant: 'ignored' });setReadBigInts
JavaScript Number loses precision for integers above Number.MAX_SAFE_INTEGER (2^53 - 1). Enable this to get BigInt instead.
db.exec('CREATE TABLE big (val INTEGER)');
db.exec('INSERT INTO big VALUES (9007199254740993)');
const stmt = db.prepare('SELECT val FROM big');
stmt.setReadBigInts(true);
const row = stmt.get();
console.log(row.val, typeof row.val); // 9007199254740993n bigintsetReturnArrays
Return arrays instead of objects. Minor performance gain for bulk processing where column names don’t matter.
const stmt = db.prepare('SELECT id, name FROM products');
stmt.setReturnArrays(true);
console.log(stmt.all()); // [[1, 'AirPods Pro'], [2, 'MacBook Pro'], ...]columns()
Get column metadata from a statement:
const stmt = db.prepare('SELECT id, player, score FROM scores WHERE player = ?');
const cols = stmt.columns();
console.log(cols.map(c => c.name)); // ['id', 'player', 'score']Real Example: CLI Task Manager
Here’s a working CLI tool built entirely on node:sqlite — no external packages:
// task-manager.js
const { DatabaseSync } = require('node:sqlite');
const path = require('path');
const db = new DatabaseSync(path.join(__dirname, 'tasks.db'));
db.exec(`
CREATE TABLE IF NOT EXISTS tasks (
id INTEGER PRIMARY KEY AUTOINCREMENT,
title TEXT NOT NULL,
done INTEGER DEFAULT 0,
created_at INTEGER NOT NULL
)
`);
const stmtAdd = db.prepare('INSERT INTO tasks (title, created_at) VALUES (?, ?)');
const stmtDone = db.prepare('UPDATE tasks SET done = 1 WHERE id = ?');
const stmtList = db.prepare('SELECT * FROM tasks ORDER BY created_at DESC');
const stmtDel = db.prepare('DELETE FROM tasks WHERE id = ?');
const add = (title) => stmtAdd.run(title, Date.now()).lastInsertRowid;
const complete = (id) => stmtDone.run(id).changes;
const list = () => stmtList.all();
const remove = (id) => stmtDel.run(id).changes;
// Demo
const id1 = add('Write node:sqlite test');
const id2 = add('Draft the blog post');
const id3 = add('Run build validation');
complete(id1);
list().forEach(t => console.log(`[${t.done ? '✓' : ' '}] #${t.id} ${t.title}`));
remove(id3);
console.log('\nAfter delete:', list().length, 'tasks remain');
db.close();Output:
[ ] #3 Run build validation
[ ] #2 Draft the blog post
[✓] #1 Write node:sqlite test
After delete: 2 tasks remainNo node-gyp. No native addon. No dependency at all. Just Node.js.
WAL Mode and Performance
For anything beyond a quick script, enable WAL mode:
const db = new DatabaseSync('./app.db');
db.exec('PRAGMA journal_mode=WAL'); // concurrent reads + faster writes
db.exec('PRAGMA synchronous=NORMAL'); // slight performance gain
db.exec('PRAGMA cache_size=-64000'); // 64MB cache (default is ~2MB)
db.exec('PRAGMA temp_store=MEMORY'); // temp tables in memory
const mode = db.prepare('PRAGMA journal_mode').get();
console.log(mode.journal_mode); // walAs I covered in the Deno 2 vs Bun comparison, SQLite with WAL mode handles most internal tooling workloads well. You don’t always need Postgres.
Error Handling
SQLite errors come as standard Error objects with an errcode property:
try {
db.exec('INVALID SQL @@@@');
} catch (e) {
console.log(e.constructor.name); // Error
console.log(e.errcode); // 1 (SQLITE_ERROR)
console.log(e.message); // near "INVALID": syntax error
}
try {
db.exec("INSERT INTO t VALUES (1, 'b')"); // UNIQUE constraint
} catch (e) {
console.log(e.errcode); // 19 (SQLITE_CONSTRAINT)
}Full error codes: sqlite.org/rescode.html.
Current Limitations and My Take
What’s missing:
- Still experimental in Node.js 22 — API could change between minor versions
- Synchronous only — no async path, event loop can block under heavy I/O
- No
db.transaction()wrapper — more boilerplate for transactional code - No
serialize()/deserialize()— can’t dump an in-memory DB to a Buffer - Extension loading (
loadExtension) exists but is platform-dependent
My honest assessment:
Don’t ship this to a production HTTP server yet. Wait for Node.js v26 LTS and the experimental flag to drop. But for internal scripts, CLI tools, build pipelines, caches, and prototypes — it’s ready right now. If you’ve ever lost an hour to a better-sqlite3 build failure in CI, this module is immediately worth switching to.
If you build shell automation scripts like with Bun Shell or internal developer tooling and want to minimize dependencies, node:sqlite is a practical choice today.
Wrapping Up
After testing every method in node:sqlite, my conclusion: more complete than I expected. DatabaseSync, StatementSync, user-defined functions, aggregates, WAL mode, BigInt support — most of what internal tooling needs is here.
The missing db.transaction() wrapper is the most noticeable gap. But a one-time withTransaction() helper fixes it. It’s not a dealbreaker.
What I see here is a signal: Node.js is steadily pulling capabilities in-house. fetch, WebCrypto, test runner, now sqlite. At some point I’ll start wondering when postgresql makes the list — which is probably too much to ask, but a developer can dream.
Was this helpful?
Your support helps me create better content. Buy me a coffee.
Related Articles
-
Deno 2 vs Bun 1.3 — Node.js Runtime Alternatives Compared in 2026: TypeScript, Speed, and Security
Seeing how Deno and Bun approach built-in database support puts Node.js built-in SQLite in broader ecosystem context.

-
Hono.js + TypeScript Edge REST API — Cloudflare Workers Deployment Guide
Combining Hono APIs with node:sqlite lets you spin up zero-external-dependency microservices instantly.
-
Building Automation Scripts with Bun Shell — From Setup to Real-World Patterns
Understanding the built-in module philosophy behind node:sqlite helps when comparing how Bun Shell approaches its own automation primitives.
