OpenAI Codex Cloud Agent vs Claude Code — May 2026 Comparison
OpenAI Codex became cloud-agent-only in April 2026. Architecture, benchmarks, cost, and workflow fit vs Claude Code — a clear May 2026 verdict for engineering teams.
“I’m on Claude Code right now — should I switch to Codex?”
I’ve heard that question three times in the past two weeks. It started after April 16, when OpenAI shipped a major Codex update: background computer use, parallel agents running on Mac, PR review, an in-app browser, and 90+ plugins — all at once. Then on April 23 they folded in GPT-5.5.
To be upfront: I haven’t used Codex myself. The cloud agent requires a ChatGPT Pro, Business, or Enterprise subscription, and my current workflow is built around Claude Code. So this is a Source Review — based on OpenAI’s official changelog, release blog posts, morphllm.com’s benchmark analysis, DataCamp, and several comparison articles. I won’t describe running something I didn’t run.
One thing that struck me while reading the comparison pieces: reactions to the two tools are polarized. “Switched to Codex and doubled my throughput” sits in the same Reddit thread as “code quality dropped off a cliff vs Claude Code.” That gap looks less like a disagreement about tool quality and more like a difference in use case — which is what the rest of this article is about.
What Changed in Codex’s April Update
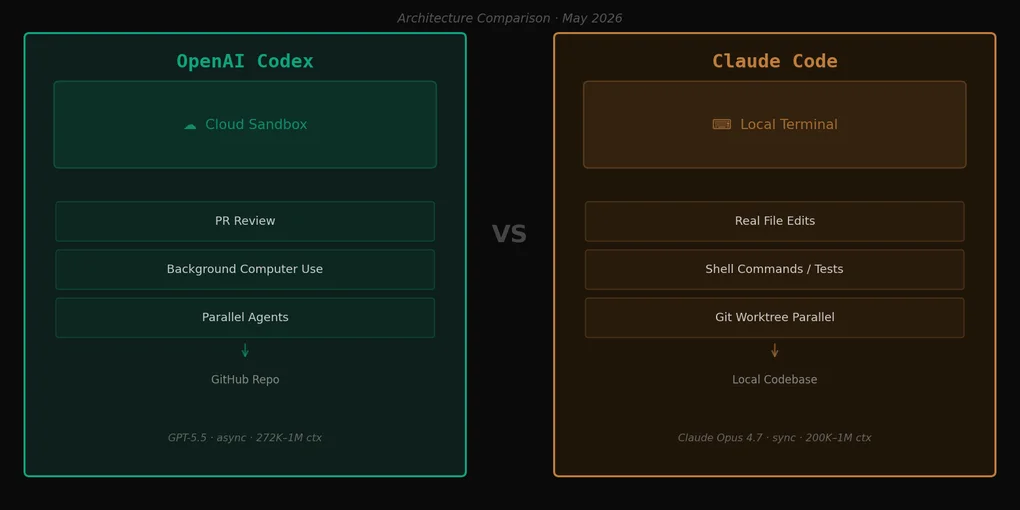
People who remember the old Codex may be confused. The 2021 Codex was the code-completion model that powered early GitHub Copilot. OpenAI reused the name for an entirely different product. Today’s Codex is a cloud-based coding agent.
Since late 2025, OpenAI has repositioned Codex as a cloud coding agent embedded in the ChatGPT interface. The basic flow: you give it a task, it pulls your connected GitHub repo into a cloud sandbox, works asynchronously, then opens a PR when it’s done. The model is “let the agent code while you do something else.”
The April 16 update expanded this significantly. Looking at the official changelog, release blog, and releasebot.io’s Codex update tracker, the major additions break into four areas:
Background computer use. Codex can now run as a native agent on your Mac, seeing and operating other applications — clicking, typing, navigating. Multiple agents can run in parallel without interfering with your own work. OpenAI describes this as useful for “frontend iteration and testing in apps that don’t expose an API.” It was rolling out in stages as of April, starting with Pro users.
PR review and in-app browser. Codex could already open PRs automatically; now it can review them too. The write-PR-get-feedback-revise cycle can happen entirely within Codex. The in-app browser lets agents verify frontend output visually as they iterate — useful for UI work.
90+ plugins. Slack, Jira, GitHub, and many more external integrations were added in this update. MCP server support also improved.
GPT-5.5 integration (April 23). GPT-5.5 became Codex’s default model a week after the feature update. OpenAI says it’s better at “multi-step tasks, planning, tool use, and checking its own work.” My GPT-5.5 release analysis covers the model itself in more depth.
The direction is clear. Codex is moving from “write code for you” to “an agent workspace where work continues while you’re away.” The April changelog uses the phrase “full agent workspace” explicitly.
Architecture Is the Real Difference
Before comparing features, it’s worth acknowledging that these two tools are solving fundamentally different problems. Putting them side by side as if they’re interchangeable can lead to misleading conclusions.
Claude Code runs in your local terminal. It reads your actual files, executes shell commands, runs your tests, and manipulates git — all synchronously. You issue a command and get an immediate response. The feedback loop is tight and continuous.
Codex is asynchronous. You upload a repo to a cloud sandbox, issue a task, and go do something else. When Codex finishes, a PR appears. The feedback loop is slow, but you can be completely elsewhere while it runs.
Before arguing which is “better,” it helps to be honest about when each model fits. The fundamental difference isn’t a quality gap — it’s a workflow philosophy gap. Comparing them on the same axis is a bit like comparing a synchronous API call to a queue-based job system. Both are valid. Neither is universally better.
Claude Code is the better fit when requirements shift during work — chasing a complex bug, narrowing an architecture, running “try this, if not then try that” cycles fast. It’s also better when your project has local-only dependencies: private databases, internal APIs, resources behind a corporate VPN. Codex can reach your GitHub repo but not anything that only your local machine can see. That’s a real constraint worth planning around.
Codex is a better fit for tasks that are well-defined and self-contained: “Bring this module’s test coverage up to 80%,” “Refactor this endpoint and open a PR.” It also becomes more compelling in team settings where multiple developers are working on separate feature branches simultaneously — assign a Codex agent to each branch, run them in parallel. That’s a genuine time-to-PR advantage for teams of 3–10.
Benchmarks: What the Numbers Say and Don’t Say
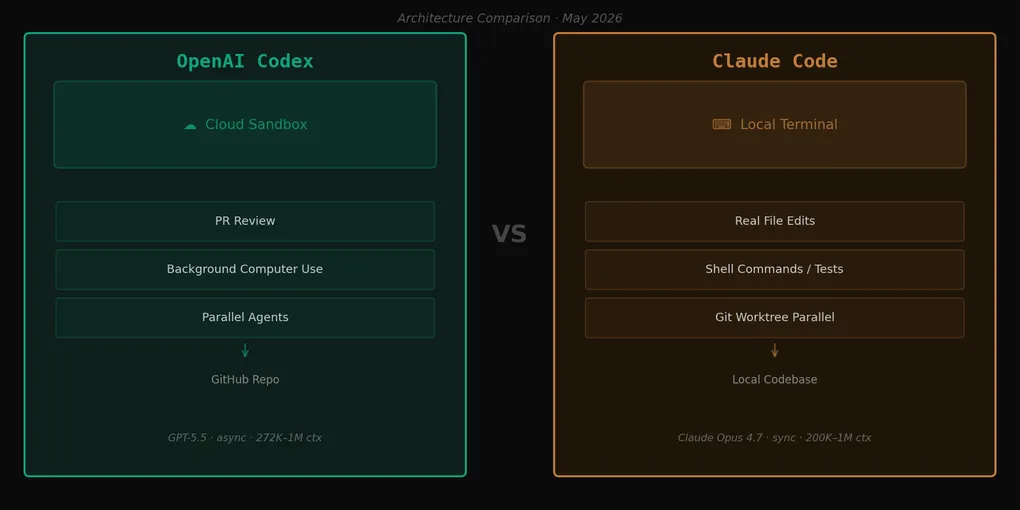
The benchmark picture is complicated. Neither tool dominates across the board.
From the public data I found: SWE-bench Verified puts Claude Code at 80.8%, Codex at 55.4%. That 25-point gap is significant. SWE-bench Pro is nearly a tie — Codex 56.8%, Claude Code 54.4%. Terminal-Bench 2.0 goes to Codex at 77.3% vs Claude Code’s 65.4%. Terminal-heavy DevOps work favors Codex.
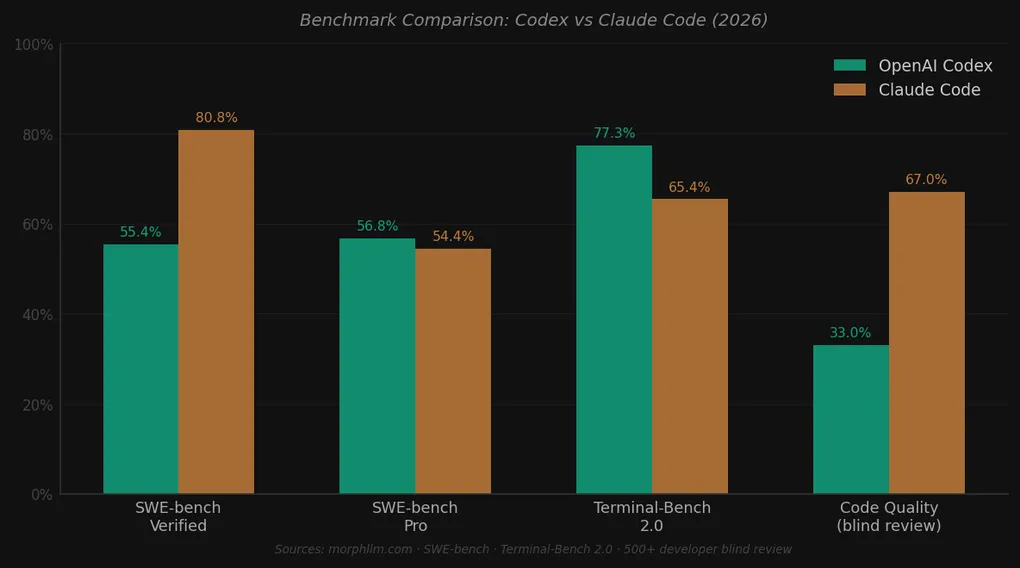
The most interesting data point is a 500+ developer blind review on Reddit. When code authorship was hidden, 67% rated Claude Code’s output higher quality. But asked which tool they’d prefer for daily work, 65% chose Codex. People are choosing the tool they rate as lower quality for day-to-day use.
Two plausible explanations. First, workflow integration: Codex lives inside ChatGPT. For teams already using ChatGPT daily, zero onboarding friction matters. Claude Code has a learning curve tied to terminal fluency and local environment setup. Second, task size: blind code reviews typically compare small snippets. Codex’s practical advantage plays out in larger task delegation, which doesn’t show in snippet comparisons.
Still, I can’t dismiss the 25-point gap on SWE-bench Verified by pointing to “different benchmarks measure different things.” This particular benchmark measures exactly what Codex claims to be good at: resolving real GitHub issues as PRs. There’s no official OpenAI response to this gap that I’ve found.
Worth noting: SWE-bench comes in multiple variants (Lite, Verified, Pro), and test configurations vary. The narrowing gap at the harder Pro level suggests that for easier-to-medium issues, the gap is real; for the hardest ones, it compresses. Where your actual work falls in that difficulty distribution matters.
Cost: Cheaper Per Token, But the Math Is Complicated
Multiple analyses put Codex at roughly 2x cheaper on input tokens and 1.67x cheaper on output tokens vs Claude Sonnet. morphllm.com claims that with token efficiency factored in, the effective cost advantage reaches “8x.”
I don’t take that number at face value for a few reasons.
The comparison conditions aren’t standardized. Claude Code works by reading local files and building context incrementally. Codex ingests a GitHub repo via cloud sandbox. Reproducing identical tasks in both environments is hard. The 8x figure has an unverifiable methodology.
Subscription cost has to be counted. Codex requires ChatGPT Pro ($20/mo), Business, or Enterprise today. Claude Code requires a Claude subscription in the same price range, plus token costs. The practical question is whether your team already has ChatGPT Business subscriptions. If yes, Codex is essentially free to add. If starting fresh, both tools enter at roughly the same monthly cost floor.
There are also hidden time costs in async work. When a Codex PR comes back wrong, you review it, request revisions, and wait again. With Claude Code you redirect mid-task. That review-revise-retry cycle isn’t captured in token cost comparisons.
How This Looks From a Claude Code User’s Perspective
My main work — blog automation, agent pipeline development, script building — relies on quick feedback loops and iterative refinement. Requirements shift mid-session; I need to see partial results and change direction.
The Codex scenario that tempts me is async batch PR work: “Fix the frontmatter format across all 10 blog posts, I’ll be in a meeting.” For tasks that are atomic, don’t need local environment access, and produce reviewable PRs, the async model makes sense. I’ve built parallel Claude Code sessions using Git Worktree that handle concurrency differently, but I can see how Codex’s model would appeal to others.
What doesn’t fit my setup: the existing automation infrastructure here (hooks, custom commands, slash skills) would need to be rebuilt for Codex. That’s not a quality judgment — it’s just switching costs against an already-working system.
I also keep the stability history in mind. Five months ago, the GPT-5.3 Codex rollout was paused due to platform reliability issues. This April update is significantly larger in scope. Cloud agent services fail differently than local CLIs — when the service is down, you can’t work. Claude Code running locally keeps editing files even without internet. That resilience difference is easy to dismiss until the service goes down the night before a deadline.
My Take at May 2026
In the Cursor 3 vs Claude Code vs Windsurf comparison, I reached a similar conclusion: the question isn’t which tool is better, but which workflow it fits. Codex and Claude Code have enough architectural overlap to appear comparable but are optimized for different development patterns.
Codex’s April update is real progress. The direction toward a full async agent workspace is clear, GPT-5.5 brings genuine model improvements, and the 90+ plugins make it more practical across diverse tech stacks. For teams already on ChatGPT Business wanting to delegate well-scoped async tasks, this is the right time to evaluate it seriously.
That said, the 25-point SWE-bench Verified gap needs an explanation. The cloud sandbox’s debugging opacity is an open question. And the actual cost calculation is more complex than the “2x cheaper per token” headline suggests.
My recommendation: if you’re using Claude Code and it’s working, don’t treat Codex as a replacement. Treat it as a candidate for a specific slot — async feature delegation, batch PR generation, independent branch work — and test it there. If you’re starting fresh without existing Claude Code investment, the choice depends almost entirely on whether your team already has ChatGPT infrastructure in place.
The AI coding tool market shifts every six months. As I write this, Google I/O 2026 (May 19–20) is ten days away, and whatever gets announced there will add another data point to this comparison. The most durable selection criterion isn’t “which benchmark wins today” but “where is my development workflow actually bottlenecked.”
Codex directly? I’ll write a hands-on post if I get access. Source Review and first-hand experience aren’t the same thing. What this comparison does show is that neither tool is wrong — they’re just optimized for different ways of working.
This article is a Source Review based on OpenAI’s official changelog (developers.openai.com/codex/changelog), release blog (openai.com/index/introducing-upgrades-to-codex/), morphllm.com benchmark analysis, and DataCamp comparison articles. The Codex cloud agent was not directly executed; no claims are made about running features that were not run.
Was this helpful?
Your support helps me create better content. Buy me a coffee.
Related Articles
-
Cursor 3 vs Claude Code vs Windsurf: Best AI Tool in 2026
If you're weighing AI coding tools, the three-way comparison of Cursor 3, Claude Code, and Windsurf gives Codex's positioning clearer context.

-
GPT-5.5 Released — OpenAI Bets on the Agent Runtime, and How It Compares to Claude
Codex integrated GPT-5.5 in April. Understanding the model itself complements this tool comparison.

-
Running Claude Code in Parallel — Git Worktree Guide for Simultaneous Tasks
If you want to replicate Codex-style parallel work in Claude Code, the Git Worktree guide gives a direct answer.
