OpenAI Codex 云端智能体 vs Claude Code — 2026年5月对比
OpenAI Codex于2026年4月转型为云端智能体专用工作区。本文对比Codex与Claude Code的架构差异、基准测试、成本与工作流程适配性,提供2026年5月基准下的团队选型判断框架。
“我现在用的是Claude Code——要不要切换到Codex?”
过去两周,我听到这个问题至少三次。起因是4月16日OpenAI推出的Codex重大更新:后台计算机使用、Mac上的并行智能体、PR审查、内置浏览器,以及90多个插件——一次性全部上线。4月23日又集成了GPT-5.5。
先说清楚:我没有亲自使用过Codex。云端智能体需要ChatGPT Pro、Business或Enterprise订阅,而我目前的工作流程是围绕Claude Code构建的。因此本文是一篇Source Review——基于OpenAI官方更新日志、发布博客、morphllm.com的基准测试分析、DataCamp,以及多篇对比文章。没有亲自运行过的功能,我不会在文中声称已运行。
读这些对比文章时,有一点让我印象深刻:开发者的反应极为两极化。“切换到Codex后效率翻倍”和”代码质量比Claude Code差很多”出现在同一个Reddit帖子里。这种落差,与其说是对工具质量的不同判断,不如说是使用场景的差异——这正是本文后续要讨论的核心。
Codex 4月更新了什么
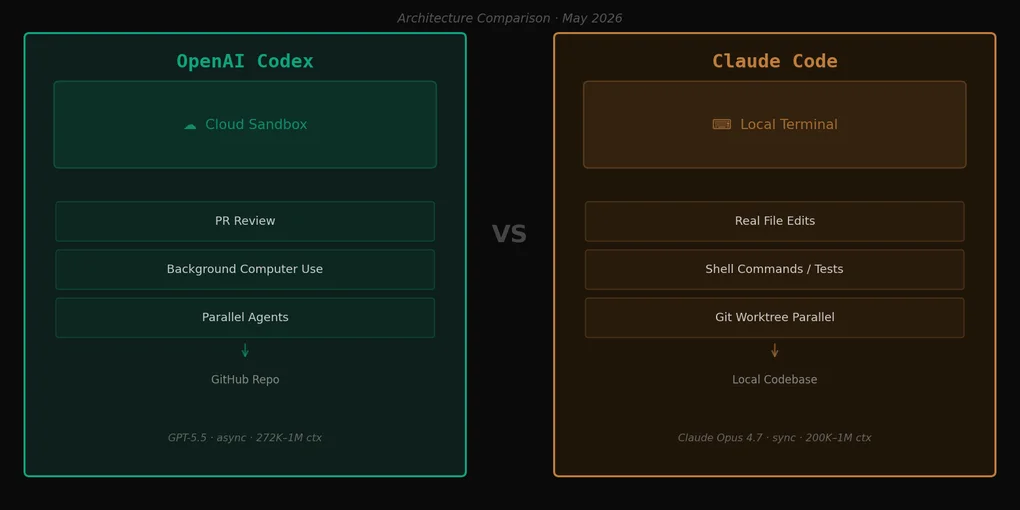
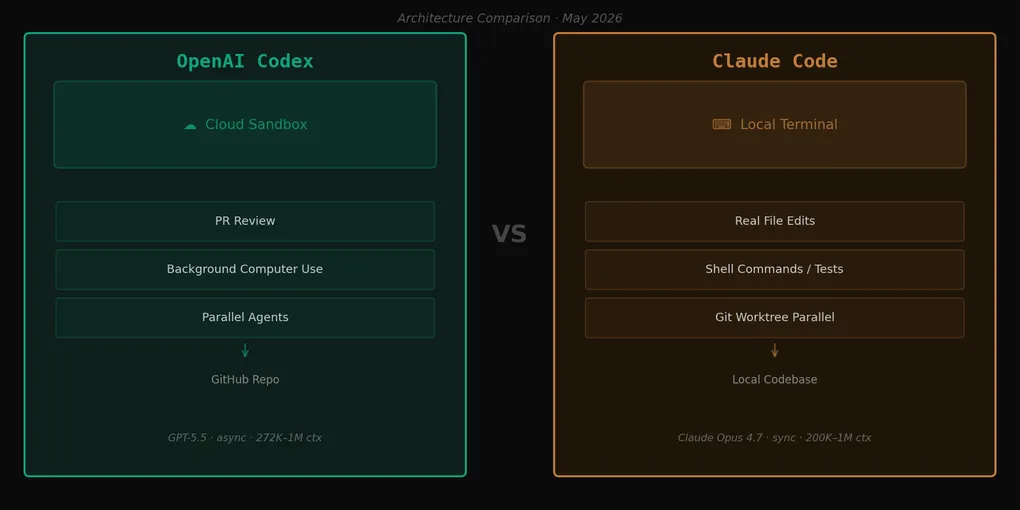
记得老版Codex的开发者可能会困惑。2021年的Codex是驱动早期GitHub Copilot的代码补全模型。OpenAI将这个名称沿用到了一款完全不同的产品上。今天的Codex是一个基于云端的编程智能体。
自2025年底,OpenAI将Codex重新定位为嵌入ChatGPT界面的云端编程智能体。基本流程:给它一个任务,它将连接的GitHub仓库拉入云端沙箱,异步执行,完成后发起PR。核心理念是”让智能体在你做其他事情的时候写代码”。
4月16日的更新大幅扩展了这一能力。根据官方更新日志、发布博客和releasebot.io的Codex更新追踪,主要新增内容可分为四类:
后台计算机使用。Codex现在可以作为原生智能体在Mac上运行,感知并操作其他应用——点击、输入、导航。多个智能体可以并行运行,不干扰用户自身的工作。OpenAI将其描述为适用于”没有暴露API的应用中进行前端迭代和测试”的场景。截至4月,该功能正在分批推出,从Pro用户开始。
PR审查与内置浏览器。Codex此前已可自动发起PR;现在还可以审查PR。“写PR→获取反馈→修改”的循环可以完全在Codex内部完成。内置浏览器让智能体在迭代过程中可视化验证前端输出——对UI工作很有价值。
90多个插件。此次更新新增了Slack、Jira、GitHub等大量外部集成,MCP服务器支持也得到改善。
GPT-5.5集成(4月23日)。功能更新一周后,GPT-5.5成为Codex的默认模型。OpenAI表示其在”多步骤任务、规划、工具使用和自我检查”方面有所提升。我的GPT-5.5发布分析对该模型本身有更深入的介绍。
方向很清晰。Codex正在从”帮你写代码”向”在你不在时持续工作的智能体工作区”演进。4月更新日志中明确使用了”full agent workspace”(完整智能体工作区)这一表述。
架构才是真正的差异所在
在比较功能之前,有必要承认:这两款工具解决的是根本不同的问题。把它们并排对比,好像可以互相替代,容易得出误导性结论。
Claude Code运行在你的本地终端。它读取你真实的文件,执行Shell命令,运行测试,操作git——一切都是同步的。发出指令立即得到响应,反馈回路紧凑且连续。
Codex是异步的。你将仓库上传到云端沙箱,发出任务,然后去做别的事。Codex完成后,PR自动出现。反馈回路慢,但你可以完全离开去做其他事情。
在争论哪个”更好”之前,先诚实地思考各自适合的场景。根本差异不是质量高低,而是工作流哲学的差异。将它们放在同一维度比较,有点像把同步API调用和基于队列的任务系统相比较。两者都有效,没有哪个普遍更好。
Claude Code更适合这些场景:需求在工作过程中不断调整——追查复杂bug、收窄架构方向、快速循环”试这个,不行换那个”。它在项目有本地专有依赖时也更合适:私有数据库、内部API、公司VPN后面的资源。Codex可以访问你的GitHub仓库,但无法访问只有本地机器才能看到的东西。这是一个值得提前规划的真实限制。
Codex更适合任务明确、边界清晰的工作:“把这个模块的测试覆盖率提升到80%”、“重构这个接口并发起PR”。在多开发者同时处理独立功能分支的团队环境中,它的优势更明显——为每个分支分配一个Codex智能体,并行运行。对于3〜10人的团队,这在PR交付时间上有实实在在的优势。
基准测试:数字说明了什么,又掩盖了什么
基准测试的情况比较复杂。两款工具都没有全面领先。
从我找到的公开数据来看:SWE-bench Verified,Claude Code 80.8%,Codex 55.4%,差距达25个百分点,相当显著。SWE-bench Pro几乎持平——Codex 56.8%,Claude Code 54.4%。Terminal-Bench 2.0则是Codex以77.3%对Claude Code的65.4%领先,终端密集的DevOps工作Codex更有优势。
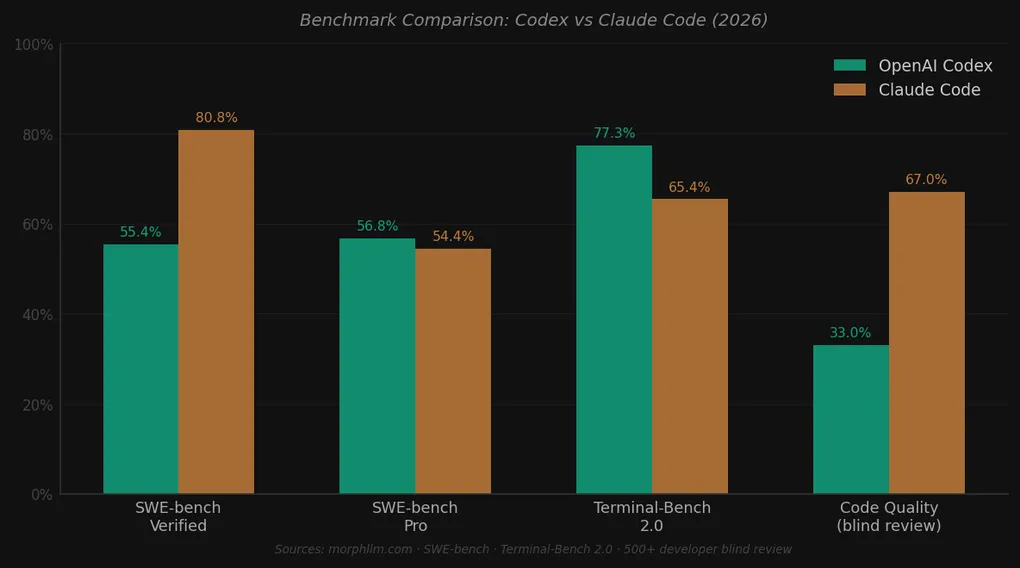
最有意思的数据点来自Reddit上500多名开发者的盲测。隐藏代码作者后,67%的人认为Claude Code的输出质量更高。但被问到日常工作中更倾向于用哪款工具时,65%的人选择了Codex。人们在日常工作中选择的,恰恰是他们评分更低的工具。
两种合理的解释。第一,工作流集成:Codex内嵌在ChatGPT里。对于已经在日常使用ChatGPT的团队来说,零上手成本很重要。Claude Code有与终端熟练度和本地环境配置相关的学习曲线。第二,任务规模:盲测通常比较小代码片段,而Codex的实际优势体现在更大任务的委托上,这在代码片段对比中看不出来。
不过,我无法仅凭”不同基准测量不同东西”来化解SWE-bench Verified上那25个百分点的差距。这个基准恰恰测量的是Codex声称最擅长的事情:以PR形式解决真实的GitHub Issue。对于这一差距,我没有找到OpenAI的官方回应。
值得注意的是:SWE-bench有多个变体(Lite、Verified、Pro),测试配置也各有不同。在更难的Pro级别差距收窄,说明对于中等难度的问题,差距是真实存在的;而对于最难的问题,差距会压缩。你的实际工作在这个难度分布中落在哪里,直接影响哪款工具更适合你。
成本:每Token更便宜,但算法更复杂
多项分析显示,Codex的输入token成本约为Claude Sonnet的一半,输出token成本约便宜1.67倍。morphllm.com声称,考虑token效率后,实际成本优势达到”8倍”。
我不会直接采信这个数字,原因如下。
比较条件没有标准化。Claude Code通过读取本地文件逐步构建上下文;Codex通过云端沙箱摄入整个GitHub仓库。在两套环境中完整复现相同任务很困难。“8倍”的说法背后有无法验证的方法论。
订阅成本必须算进去。Codex目前需要ChatGPT Pro(20美元/月)、Business或Enterprise订阅。Claude Code也需要同价位的Claude订阅,加上token费用。实际问题是:你的团队是否已经有ChatGPT Business订阅?如果有,Codex基本上是免费追加的。如果从零开始,两款工具的月起步费用大致相同。
异步工作还有隐性时间成本。当一个Codex PR回来有问题时,你要审查、请求修改、再等待。用Claude Code你可以在任务中途改变方向。这个”审查-修改-重试”的循环不会体现在token成本对比中。
此外,ChatGPT Business订阅的用途不止Codex一项——团队本来就可能在用ChatGPT进行文档写作、客户沟通、会议记录等。如果你的团队已经在付费使用ChatGPT Business,那Codex的边际成本确实接近零。反之,如果仅仅为了Codex而订阅ChatGPT Business,每月20美元+的起步费用就需要重新核算。
从Claude Code用户视角看这件事
我的主要工作——博客自动化、智能体流水线开发、脚本构建——依赖快速反馈循环和迭代优化。需求在会话中途会改变;我需要看到中间结果并调整方向。
让我心动的Codex场景是异步批量PR工作:“把所有10篇博文的frontmatter格式统一,我去开个会。“对于原子性强、不需要访问本地环境、能生成可审查PR的任务,异步模式是合理的。我用Git Worktree构建过Claude Code并行会话来处理并发任务,但我理解Codex的模式为什么对其他人更有吸引力。
不适合我当前设置的部分:这里已有的自动化基础设施(hooks、自定义命令、slash技能)需要针对Codex重新构建。这不是质量判断——只是切换成本对抗一个已经在运作的系统。
我也记得稳定性历史。五个月前,GPT-5.3 Codex上线因平台稳定性问题而暂停。而这次4月更新的范围要大得多。云端智能体服务的故障模式与本地CLI不同——服务宕机时,你就没法工作了。Claude Code在本地运行,没有网络也能继续编辑文件。这种韧性差异平时容易被忽视,直到截止日期前一晚服务挂了才会后悔。
2026年5月的判断
在Cursor 3 vs Claude Code vs Windsurf对比中,我得出了类似结论:问题不是哪款工具更好,而是它适合哪种工作流。Codex和Claude Code有足够多的架构重叠,看起来可以互换,但实际上各自针对不同的开发模式做了优化。
Codex的4月更新是真实的进步。向完整异步智能体工作区演进的方向清晰,GPT-5.5带来了切实的模型改进,90多个插件让它在更多技术栈中更实用。对于已经使用ChatGPT Business、想委托明确范围异步任务的团队,现在是认真评估的好时机。
话虽如此,SWE-bench Verified上25个百分点的差距需要一个解释。云端沙箱调试透明度低是一个悬而未决的问题。实际成本计算也比”每token便宜2倍”的标题更复杂。
我的建议:如果你在用Claude Code且运转良好,不要把Codex当作替代品。把它视为某个特定插槽的候选——异步功能委托、批量PR生成、独立分支工作——在那里先试验一下。如果你从零开始、没有现有Claude Code投入,选择几乎完全取决于你的团队是否已经有ChatGPT基础设施。
AI编程工具市场每半年就会洗牌一次。写这篇文章时,Google I/O 2026(5月19〜20日)还有十天,届时发布的内容将为这场对比增加新的数据点。最持久的选型标准不是”今天哪个基准更高”,而是”我的开发工作流实际瓶颈在哪里”。
Codex我没有亲自用过。如果拿到访问权限,我会写一篇实操文章。Source Review和第一手体验不是一回事。这篇对比能说明的是:两款工具都没错——只是针对不同的工作方式做了优化。
本文为Source Review,基于OpenAI官方更新日志(developers.openai.com/codex/changelog)、发布博客(openai.com/index/introducing-upgrades-to-codex/)、morphllm.com基准分析及DataCamp对比文章撰写。未直接执行Codex云端智能体;文中不声明对未实际运行的功能有直接体验。
阅读其他语言版本
- 🇰🇷 한국어
- 🇯🇵 日本語
- 🇺🇸 English
- 🇨🇳 中文(当前页面)
这篇文章有帮助吗?
您的支持能帮助我创作更好的内容。请我喝杯咖啡吧。
相关文章
-
Cursor 3 vs Claude Code vs Windsurf: 2026年AI编程工具选择指南
如果你正在考虑AI编程工具的选择,同时阅读Cursor 3、Claude Code和Windsurf的三方对比,会让Codex的定位更加清晰。

-
GPT-5.5发布 — OpenAI转向Agent Runtime,与Claude的实战对比
Codex在4月集成了GPT-5.5。了解模型本身的特性有助于更全面地理解这篇工具对比。

-
Claude Code 并行会话运行指南 — 使用 Git Worktree 同时处理多项任务
如果你想在Claude Code中实现类似Codex的并行工作,Git Worktree指南提供了直接的答案。
