Karpathy「AI学習コストは年40%下落」— デフレーションが業界構造を変える
AIモデルの学習コストが毎年40%ずつ下落しているというKarpathyの分析。ハードウェア進化、アルゴリズム効率化、データパイプライン最適化など構造的要因と業界への影響を解説します。
概要
Andrej Karpathyが自身のnanochatプロジェクトを通じて驚くべき事実を公開しました。2019年にOpenAIがGPT-2(1.5Bパラメータ)を学習させるのに約$43,000かかりましたが、2026年現在、同じ性能を達成するのにわずか$73で十分だということです。これは約600倍のコスト削減であり、年間約40%ずつコストが下落するデフレーション傾向を示しています。
本記事では、Karpathyの分析をもとにAI学習コスト下落の構造的要因と業界への影響を解説します。
GPT-2学習コストの変遷
2019年:$43,000
- ハードウェア:32台のTPU v3チップ(256 TPU v3コア)
- 学習時間:約1週間(~168時間)
- クラウドコスト:TPU v3時間あたり$8 × 32 × 168 = $43,000
2026年:$73
- ハードウェア:8×H100 GPU単一ノード
- 学習時間:約3時間
- クラウドコスト:時間あたり~$24 × 3 = $73
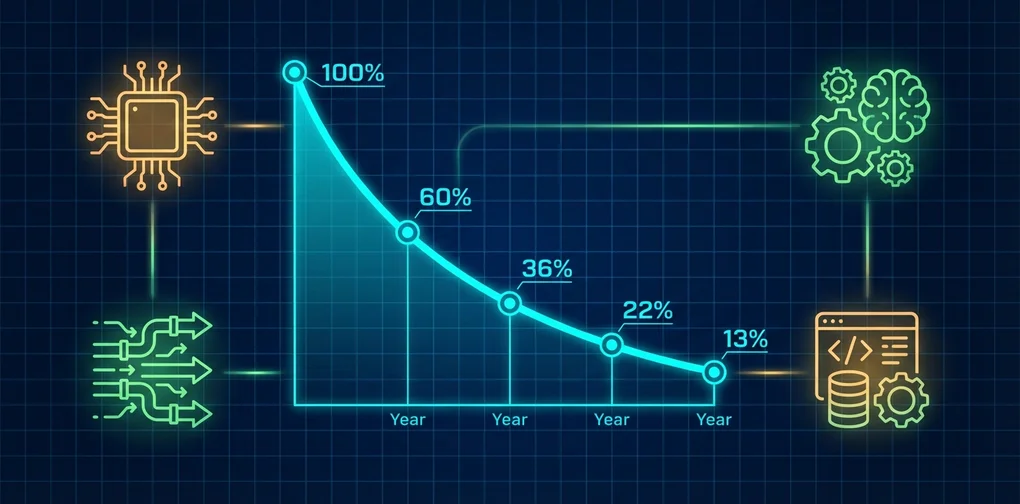
コスト推移(GPT-2同等性能達成基準)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
2019年: $43,000 ████████████████████████████████
2020年: $17,200 █████████████
2021年: $6,880 █████
2022年: $2,752 ███
2023年: $1,101 ██
2024年: $440 █
2025年: $176 ▏
2026年: $73 ▏
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━コスト下落の4つの構造的要因
Karpathyは、コスト下落が単一要因ではなく4つの軸の同時改善によるものだと分析しています。
1. ハードウェアの進化(Hardware)
TPU v3からH100への移行は、単なる世代交代を超えた根本的な演算効率の向上を意味します。
- FP8演算サポート:学習精度を下げつつ品質を維持
- HBM3メモリ:帯域幅3TB/sでメモリボトルネックを解消
- NVLink 4.0:GPU間通信速度900GB/sでマルチGPU効率を最大化
2. ソフトウェア最適化(Software)
ソフトウェアスタックの改善が、同一ハードウェアでも劇的な性能向上をもたらします。
- Flash Attention 3:約9%のトークン/秒改善。ネイティブテンソルレイアウトで学習と推論を統合
- torch.compile:JITコンパイルでPythonオーバーヘッドを除去
- Sliding Window Attention:SSSLパターン(短いウィンドウ3回+長いウィンドウ1回)で品質低下なく計算量を削減
3. アルゴリズムの革新(Algorithms)
オプティマイザとアーキテクチャの革新が学習効率を根本的に改善します。
- Muonオプティマイザ:Polar Express直交化、NorMuon分散削減、cautious weight decay適用
- Per-layer residual scalars:
x = λ_resid * x + λ_x0 * x0で全モデルサイズにおいて0.003-0.01 bpb改善 - Value Embeddings:交互レイヤーに適用し、ほぼゼロFLOPsで~150Mパラメータの追加容量を確保
- ReLU²活性化関数:GELUと比較してスパースかつ低コスト
4. データパイプラインの最適化(Data)
高品質なデータキュレーションと効率的なデータローディングが学習効率を高めます。
- FineWeb-edu:教育用高品質ウェブデータでデータ効率を最大化
- BOS-aligned dataloader:全シーケンスがBOSトークンで開始し、midtrainingが不要に
- BestFit-Cropパッキング:100%活用率、ナイーブクロップ比で無駄を約35%削減
効果がなかった試み
Karpathyは効果がなかった技法も透明に公開し、コミュニティに貴重なインサイトを提供しています。
| 技法 | 結果 |
|---|---|
| Multi-token prediction(MTP) | メモリ+13GB、改善なし |
| FP8 for lm_head | 動作するがメモリ+2GB、速度1%向上のみ |
| Half-truncated RoPE | 改善なし |
| Skip connections / backout | 改善なし、メモリ+2GB |
| Bigram embeddings(Engram-lite) | 効果ありだが複雑度対比で利点不足 |
業界構造への影響
参入障壁の崩壊
年40%のコスト下落は、AI学習の民主化を加速します。かつては大手テック企業のみ可能だった規模の学習が、今やスタートアップや個人研究者にもアクセス可能になっています。
競争軸の転換
コストがもはや差別化要素にならなくなるにつれ、競争の軸が転換します:
- データ品質:いかに良いデータを確保するか
- ファインチューニングのノウハウ:ドメイン特化の最適化能力
- 推論効率:学習よりサービング(推論)コストが核心に
オープンソースエコシステムの強化
$100以下でGPT-2級モデルを学習できるということは、オープンソースコミュニティの実験とイノベーションが大幅に加速することを意味します。nanochat自体が約1,000行のコードで構成されており、教育的価値も大きいです。
ムーアの法則を超える下落率
年40%の下落は、ムーアの法則(約2年で2倍、年~29%下落)より速い速度です。これはハードウェアだけでなく、ソフトウェア・アルゴリズム・データの同時改善が生み出す複合効果です。
結論
Karpathyのnanochatプロジェクトは、単なるベンチマーク記録更新を超えて、AI学習コストの構造的デフレーションを実証的に示す事例です。ハードウェア、ソフトウェア、アルゴリズム、データ — この4つの軸の同時改善が年40%という驚くべき下落率を生み出しており、このトレンドはAI業界の競争構造を根本的に変化させています。
重要なのは、Karpathy自身が「これは過小評価であり、さらなる改善が十分に可能だ」と述べている点です。デフレーションはまだ終わっていません。
参考資料
他の言語で読む
- 🇰🇷 한국어
- 🇯🇵 日本語(現在のページ)
- 🇺🇸 English
- 🇨🇳 中文
この記事は役に立ちましたか?
より良いコンテンツを作成するための力になります。コーヒー一杯で応援してください!☕


