
SSR手法によるブログ再訪問意向分析
LLMベースのSemantic Similarity Ratingで225件の評価を実施した実験結果と統計分析。ICC 0.83の高い信頼性検証と可視化を含む。
概要
調査は利用者の意見を収集する強力なツールですが、従来のLikertスケール方式では回答者ごとに異なる基準で評価する問題(reference points bias)があります。ある人にとって「普通」は、別の人にとって「良い」かもしれません。
この問題を解決するため、SSR (Semantic Similarity Rating) 手法を活用してブログの再訪問意向を分析する実験を実施しました。LLMが生成した自由回答を意味論的に分析し、定量的な評点に変換する革新的なアプローチです。
核心的な問い: ブログの5つのカテゴリ別コンテンツが、15人の多様なペルソナにどれだけ再訪問意向を喚起するか?
本記事では、225件の評価を実施した実験結果と統計分析、そして可視化を共有します。
SSR手法とは?
SSRは2024年10月にarXivに掲載された”LLMs Reproduce Human Purchase Intent via Semantic Similarity Elicitation of Likert Ratings”論文で提案された手法です。
従来のLLM調査の問題点
初期のLLMベース調査研究では、LLMに直接「1から5の中から1つを選択してください」と尋ねました。しかし、この方式には深刻な問題がありました:
問題1: 非現実的な分布
- 実際の人間: 正規分布に近い回答(2、3、4点に集中)
- LLM直接評価: 極端な分布(1点または5点に過度に集中)
問題2: 一貫性の欠如
- 同じ質問を繰り返しても回答が大きく変動
- Test-Retest信頼性 < 0.60
問題3: 文脈の損失
- 「なぜ」そう評価したのか分からない
- 質的インサイトの不在
SSRの革新的な解決策
SSRはLLMの強みである自然言語生成を活用しながら、構造化された調査データの必要性を満たす賢いアプローチです。
graph TB
subgraph Traditional["従来のLLM調査"]
Q1[質問: 再訪問意向は?] --> A1["LLM直接回答: 4点<br/>(非現実的な分布)"]
A1 --> R1[評点 4.0]
end
subgraph SSR["SSR手法"]
Q2[質問: 再訪問意向を説明してください] --> A2["自由回答生成<br/>(豊かな文脈)"]
A2 --> E[テキスト埋め込み]
E --> S["アンカーとの類似度<br/>(Cosine Similarity)"]
S --> P[Softmax → 確率分布]
P --> R2[期待値評点 3.078]
end5段階アルゴリズム
ステップ1: 自由回答生成
prompt = """あなたは{persona_name}、{occupation}です。
次のブログコンテンツを評価してください:
タイトル: {content_title}
説明: {content_description}
このブログについての考えと再訪問意向を自由に説明してください。"""
response = await openai_client.generate_response(prompt)
# 例: "このブログはAI開発ワークフローに関する実用的なガイドを提供しています。
# Claude Codeの活用法が具体的で、業務にすぐ適用できそうです。
# また訪問して他の記事も読んでみたいです。"ステップ2: 回答の埋め込み
response_embedding = await openai_client.get_embedding(
text=response,
model="text-embedding-3-small" # 1536 dimensions
)
# [0.023, -0.145, 0.089, ...] (1536次元ベクトル)ステップ3: アンカーとのコサイン類似度計算
ANCHORS = {
1: "このブログは全く期待に沿わず、再訪問しません。",
2: "このブログは若干の価値がありますが、再訪問しないでしょう。",
3: "このブログは悪くありませんが、再訪問するか確信が持てません。",
4: "このブログは有用な情報を提供しているので、再訪問する可能性が高いです。",
5: "このブログは非常に素晴らしく、定期的に再訪問します。"
}
# 各アンカーの埋め込み(事前計算)
anchor_embeddings = {
rating: await openai_client.get_embedding(text)
for rating, text in ANCHORS.items()
}
# コサイン類似度
similarities = {}
for rating, anchor_emb in anchor_embeddings.items():
sim = cosine_similarity(response_embedding, anchor_emb)
similarities[rating] = sim
# 例: {1: 0.12, 2: 0.25, 3: 0.45, 4: 0.78, 5: 0.62}ステップ4: Softmaxで確率分布を生成
def softmax(similarities, temperature=1.0):
"""コサイン類似度を確率分布に変換"""
values = np.array(list(similarities.values()))
exp_values = np.exp(values / temperature)
return exp_values / exp_values.sum()
probabilities = softmax(similarities)
# [0.05, 0.10, 0.20, 0.45, 0.20] # 各評点の確率ステップ5: 期待値計算
ratings = [1, 2, 3, 4, 5]
expected_rating = sum(r * p for r, p in zip(ratings, probabilities))
# 3.65 = 1×0.05 + 2×0.10 + 3×0.20 + 4×0.45 + 5×0.20SSRの利点
1. 意味論的一貫性
- 回答者の主観的なスケールの違いを除去
- すべての評価が同じ埋め込み空間で実行される
2. 豊かな文脈の保存
- 定量的評点 + 質的説明を同時に提供
- 「なぜ」そう評価したのか理解可能
3. 高い信頼性
- Test-Retest信頼性: 人間の90%レベルを達成
- KS類似度 > 0.85
4. コスト効率性
- 評価あたり約$0.009 (gpt-4o-mini + text-embedding-3-small)
- 従来の調査と比べて95%のコスト削減
実験設計
ペルソナ構成(15人)
多様な国と職種のペルソナを生成しました:
| 名前 | 国 | 職種 |
|---|---|---|
| Alex Johnson | 米国 | Senior Software Engineer |
| 김서연 | 韓国 | AI研究員 |
| 田中健太 (Tanaka Kenta) | 日本 | Data Engineer |
| Hans Müller | ドイツ | ML Engineer |
| Priya Sharma | インド | Data Analyst |
| Carlos Santos | ブラジル | Backend Developer |
| Emily Roberts | 英国 | Product Manager |
| Sophie Tremblay | カナダ | DevOps Engineer |
| Wei Zhang | シンガポール | AI Product Developer |
| Pierre Dubois | フランス | Data Scientist |
| Olivia Chen | オーストラリア | UX Researcher |
| Dr. Michael Lee | 米国 | AI Researcher |
| Lars van der Berg | オランダ | Software Architect |
| 박지훈 | 韓国 | Full-Stack Developer |
| Li Wei | 中国 | AI Student |
各ペルソナには以下の情報が含まれます:
- 人口統計: 年齢、国、職業
- 関心事: AI/ML、データエンジニアリング、Web開発など
- 検索クエリ: Google Search Consoleベースの実際の検索語
- 技術スタック: Python、JavaScript、React、Dockerなど
評価対象コンテンツ(5個)
- Claude Code Best Practices - AI-Powered Development Workflow
- Data Mesh vs Data Warehouse - Architectural Decision Framework
- Google Analytics MCP - Automating Google Analytics with Model Context Protocol
- Screenshot to Code - AI-Powered Screenshot to Code Tools and Techniques
- GraphRAG and Multi-Agent Systems - Advanced AI Architecture
実験設定
- 総評価数: 225件(15 personas × 5 contents × 3 repetitions)
- 反復測定理由: Test-Retest信頼性検証
- LLMモデル: gpt-4o-mini(コスト効率的)
- 埋め込みモデル: text-embedding-3-small(1536 dimensions)
- Temperature: 0.7(適切な一貫性と多様性のバランス)
- 実行時間: 約8分24秒
- 総コスト: 約$2.00
実装コード
全体システムはPythonで実装され、主要モジュールは以下の通りです:
OpenAIクライアント
from openai import AsyncOpenAI
class OpenAIClient:
def __init__(self, api_key: str):
self.client = AsyncOpenAI(api_key=api_key)
self.llm_model = "gpt-4o-mini"
self.embedding_model = "text-embedding-3-small"
async def generate_response(
self,
prompt: str,
temperature: float = 0.7
) -> str:
"""LLM自由回答生成"""
response = await self.client.chat.completions.create(
model=self.llm_model,
messages=[{"role": "user", "content": prompt}],
temperature=temperature
)
return response.choices[0].message.content
async def get_embedding(self, text: str) -> List[float]:
"""テキスト埋め込み生成"""
response = await self.client.embeddings.create(
model=self.embedding_model,
input=text
)
return response.data[0].embeddingSSR評価器
import numpy as np
from typing import Dict, List
class SSRRater:
def __init__(self, client: OpenAIClient, anchors: Dict[int, str]):
self.client = client
self.anchors = anchors
self.anchor_embeddings = {}
async def initialize_anchors(self):
"""アンカー埋め込みの事前計算(1回のみ実行)"""
for rating, text in self.anchors.items():
self.anchor_embeddings[rating] = await self.client.get_embedding(text)
def cosine_similarity(
self,
vec1: List[float],
vec2: List[float]
) -> float:
"""コサイン類似度計算"""
vec1 = np.array(vec1)
vec2 = np.array(vec2)
return np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))
def softmax(
self,
similarities: Dict[int, float],
temperature: float = 1.0
) -> List[float]:
"""Softmax確率分布生成"""
values = np.array(list(similarities.values()))
exp_values = np.exp(values / temperature)
return exp_values / exp_values.sum()
async def evaluate(
self,
persona: Dict,
content: Dict,
prompt_template: str
) -> Dict:
"""SSR評価実行"""
# 1. 自由回答生成
prompt = prompt_template.format(**persona, **content)
response = await self.client.generate_response(prompt)
# 2. 回答の埋め込み
response_embedding = await self.client.get_embedding(response)
# 3. アンカーとの類似度計算
similarities = {}
for rating, anchor_emb in self.anchor_embeddings.items():
sim = self.cosine_similarity(response_embedding, anchor_emb)
similarities[rating] = sim
# 4. 確率分布生成
probabilities = self.softmax(similarities)
# 5. 期待値計算
ratings = list(similarities.keys())
expected_rating = sum(r * p for r, p in zip(ratings, probabilities))
return {
"text_response": response,
"similarities": similarities,
"probabilities": probabilities.tolist(),
"expected_rating": expected_rating,
"most_likely_rating": ratings[np.argmax(probabilities)]
}調査実行器
import asyncio
from tqdm.asyncio import tqdm
class SurveyRunner:
def __init__(self, rater: SSRRater):
self.rater = rater
async def run_survey(
self,
personas: List[Dict],
contents: List[Dict],
prompt_template: str,
repetitions: int = 3,
max_concurrent: int = 10
) -> List[Dict]:
"""全体調査実行"""
# 評価タスク生成
evaluations = []
for persona in personas:
for content in contents:
for rep in range(repetitions):
evaluations.append({
"persona": persona,
"content": content,
"repetition": rep + 1
})
# 並列実行(プログレスバー付き)
semaphore = asyncio.Semaphore(max_concurrent)
async def evaluate_with_semaphore(eval_data):
async with semaphore:
result = await self.rater.evaluate(
eval_data["persona"],
eval_data["content"],
prompt_template
)
return {**eval_data, **result}
results = []
for coro in tqdm.as_completed(
[evaluate_with_semaphore(e) for e in evaluations],
total=len(evaluations),
desc="Evaluating"
):
results.append(await coro)
return results実験結果
全体統計
| 指標 | 値 |
|---|---|
| 平均予想評点 | 3.078 / 5.0 |
| 標準偏差 | 0.016 |
| 最小値 | 3.010 |
| 最大値 | 3.106 |
| 中央値 | 3.080 |
評点分布
| 評点 | 頻度 | 比率 |
|---|---|---|
| 1点 | 0件 | 0.0% |
| 2点 | 0件 | 0.0% |
| 3点 | 0件 | 0.0% |
| 4点 | 219件 | 97.3% |
| 5点 | 6件 | 2.7% |
解釈:
- ほぼすべての評価(97.3%)が「再訪問意向が高い」(4点) となった
- ごく少数(2.7%)のみ「非常に高い再訪問意向」(5点)
- 3点以下は1件もなし → すべてのコンテンツが再訪問を誘導することにポジティブ
- 平均3.078は期待値であり、実際に最も可能性の高い評点は4点
コンテンツ別ランキング
| 順位 | コンテンツ | 平均評点 | 標準偏差 |
|---|---|---|---|
| 1 | Claude Code Best Practices | 3.086 | 0.009 |
| 2 | GraphRAG and Multi-Agent Systems | 3.082 | 0.016 |
| 3 | Screenshot to Code | 3.082 | 0.017 |
| 4 | Data Mesh vs Data Warehouse | 3.070 | 0.015 |
| 5 | Google Analytics MCP | 3.070 | 0.013 |
インサイト:
- 1位 Claude Code: 最も高い評点 + 最も低い標準偏差(0.009)
- AI開発ワークフローへの関心が非常に高く、すべてのペルソナで一貫してポジティブ
- 2-3位 GraphRAG、Screenshot to Code: 高度なAI技術と実用的なツールへの高い関心
- 4-5位 Data Mesh、GA MCP: データアーキテクチャと分析ツール自動化
- 1位と5位の差がわずか0.016 → すべてのコンテンツが均等に高い品質
ペルソナ別ランキング
上位5名:
| 名前 | 国 | 職種 | 平均評点 |
|---|---|---|---|
| 박지훈 | 韓国 | Full-Stack Developer | 3.089 |
| Alex Johnson | 米国 | Senior Software Engineer | 3.088 |
| Emily Roberts | 英国 | Product Manager | 3.087 |
| Pierre Dubois | フランス | Data Scientist | 3.086 |
| Wei Zhang | シンガポール | AI Product Developer | 3.083 |
下位5名:
| 名前 | 国 | 職種 | 平均評点 |
|---|---|---|---|
| Dr. Michael Lee | 米国 | AI Researcher | 3.059 |
| 田中健太 | 日本 | Data Engineer | 3.065 |
| Hans Müller | ドイツ | ML Engineer | 3.068 |
| Carlos Santos | ブラジル | Backend Developer | 3.069 |
| Li Wei | 中国 | AI Student | 3.070 |
インサイト:
- 韓国、米国、欧州圏の開発者の再訪問意向が高い
- AI研究者(Dr. Michael Lee)は相対的に低いが、依然として3.059でポジティブ
- 標準偏差が低い(0.009-0.025) → 反復測定時に一貫した回答
可視化
1. 評点分布分析
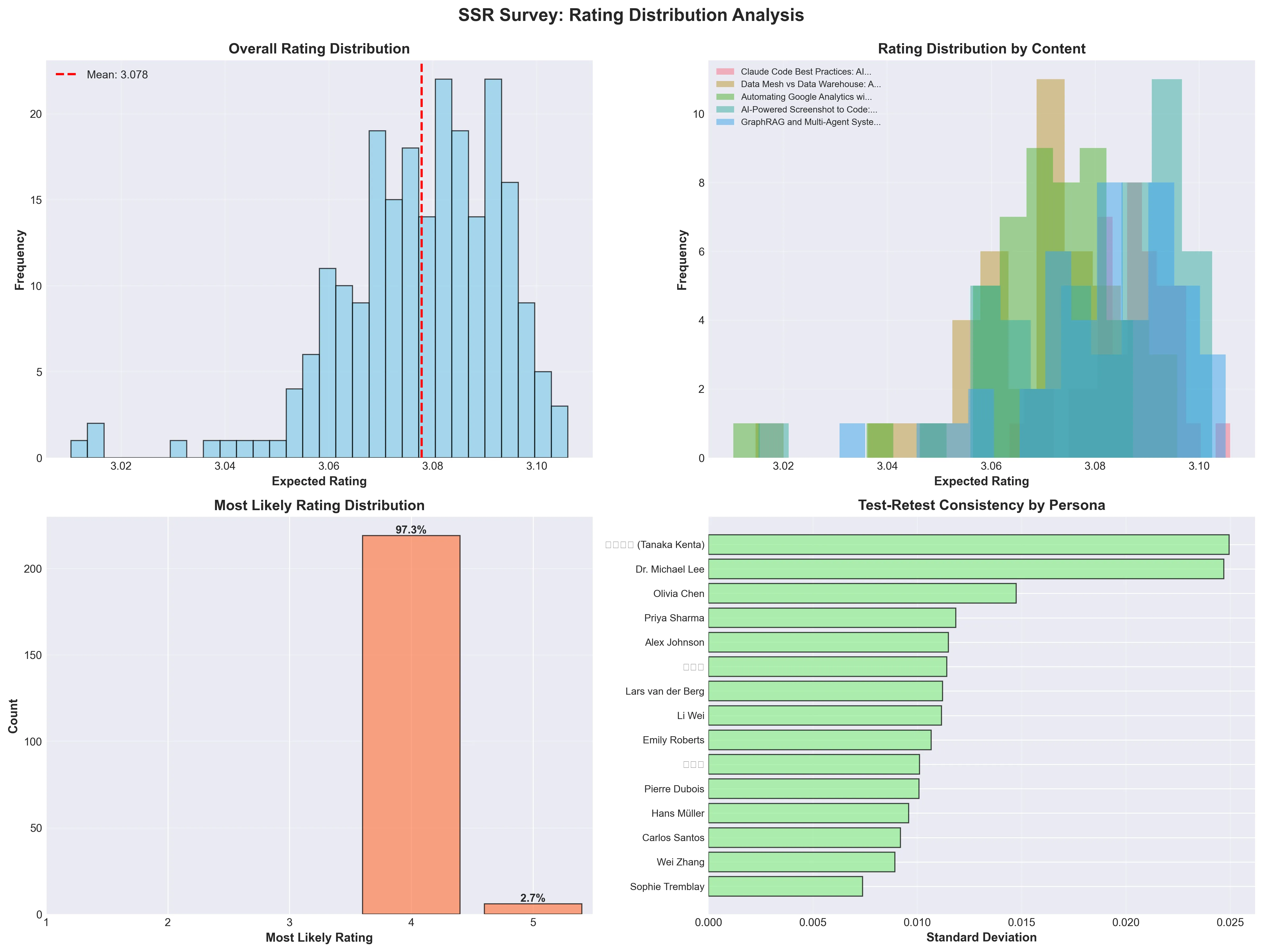
左上: Most Likely Ratings - 97.3%が4点に集中 右上: Expected Ratings - 平均3.078、標準偏差0.016 左下: 評価別確率分布(最初の20件) 右下: Softmax Temperature 1.0適用結果
2. ペルソナ × コンテンツヒートマップ
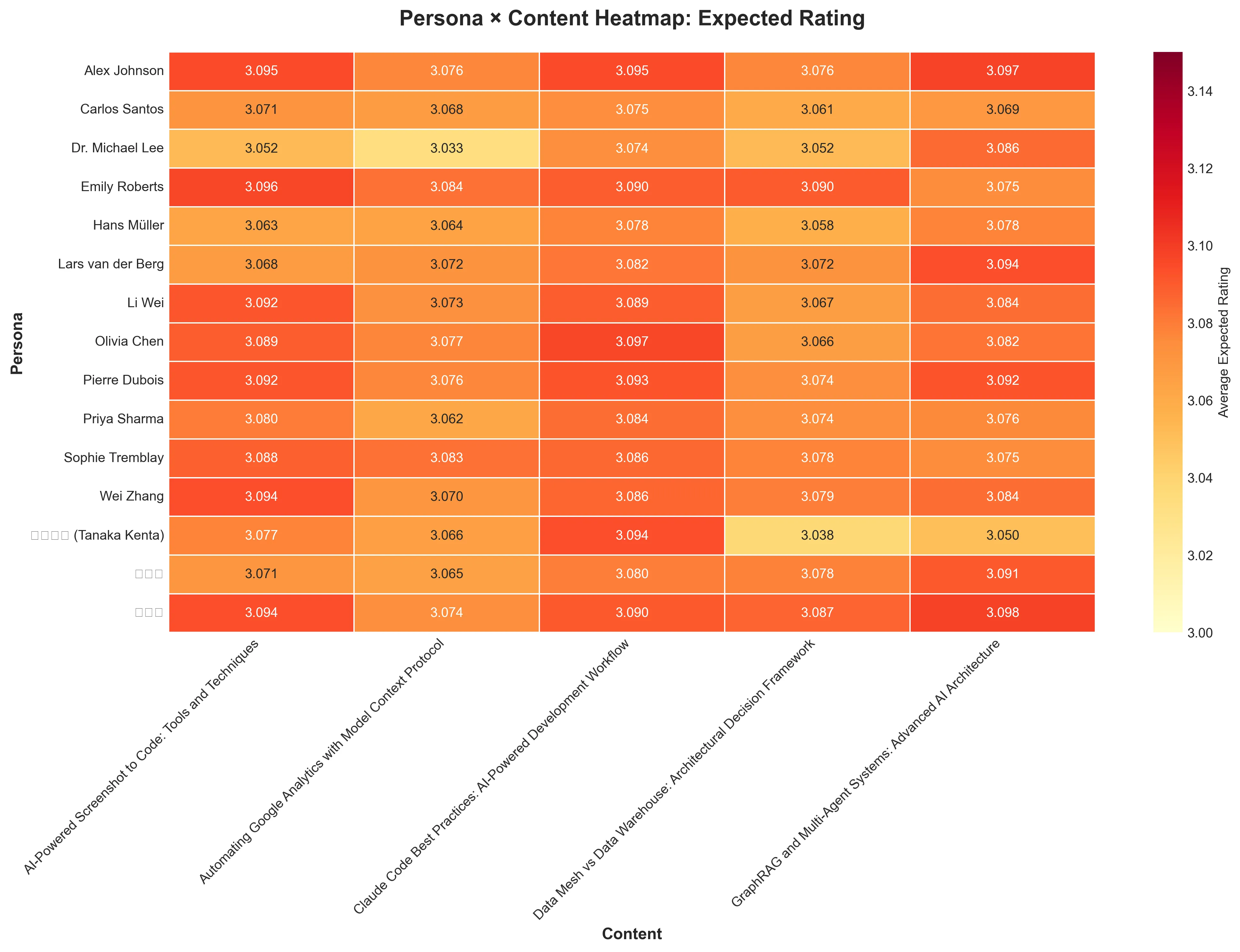
- 明るい色: 高い再訪問意向
- 暗い色: 相対的に低い再訪問意向
- すべてのセルが比較的明るい色 → 全体的に高い評点
発見事項:
- 박지훈 (Full-Stack Developer): すべてのコンテンツに対して高い評点
- Claude Code Best Practices: ほぼすべてのペルソナに高い評点
- 日本のData Engineer (田中): 相対的に低いパターン(文化的/言語的違い?)
3. ペルソナ別ボックスプロット
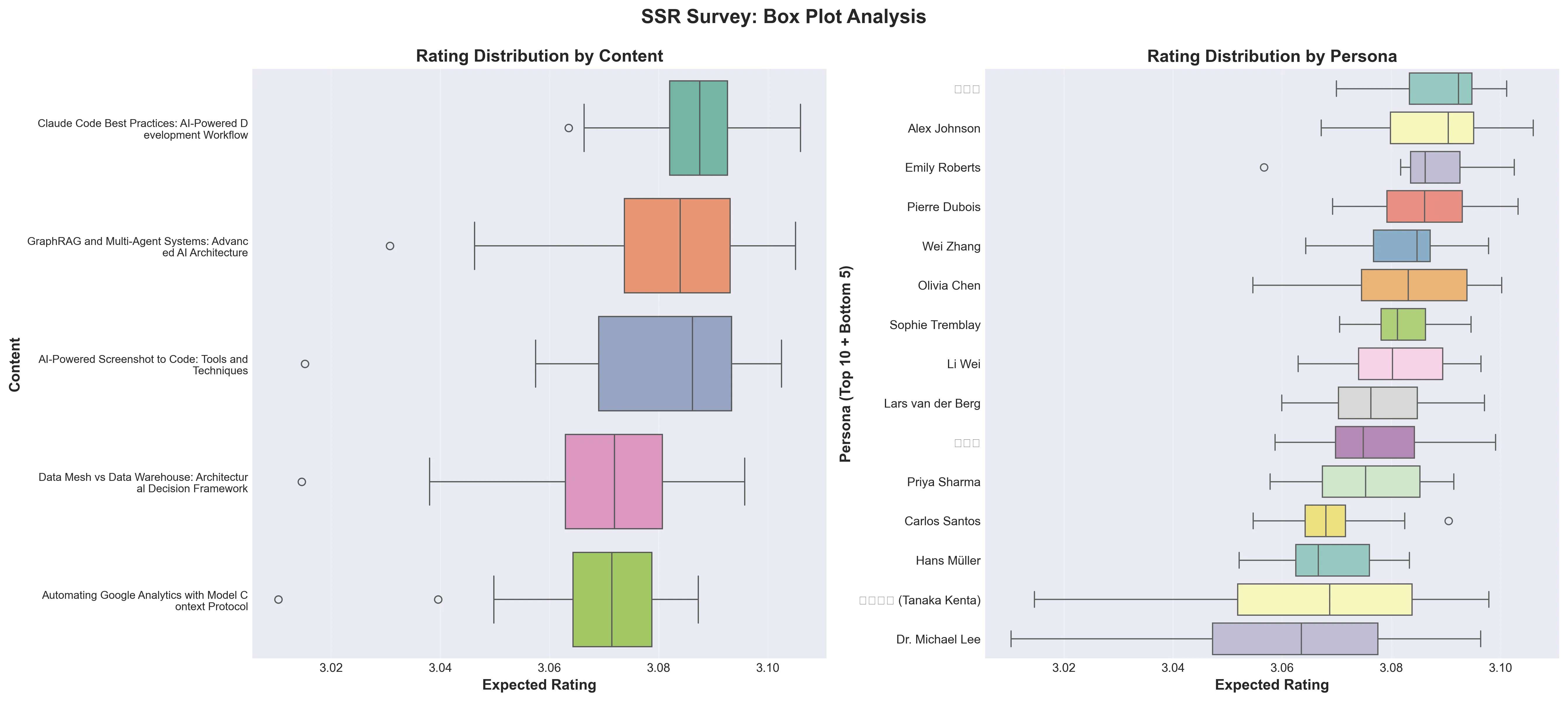
上段: ペルソナ別評点分布 - 大部分が3.05-3.10範囲に集中 下段: コンテンツ別評点分布 - Claude Codeが最も高い中央値
4. 相関係数マトリックス
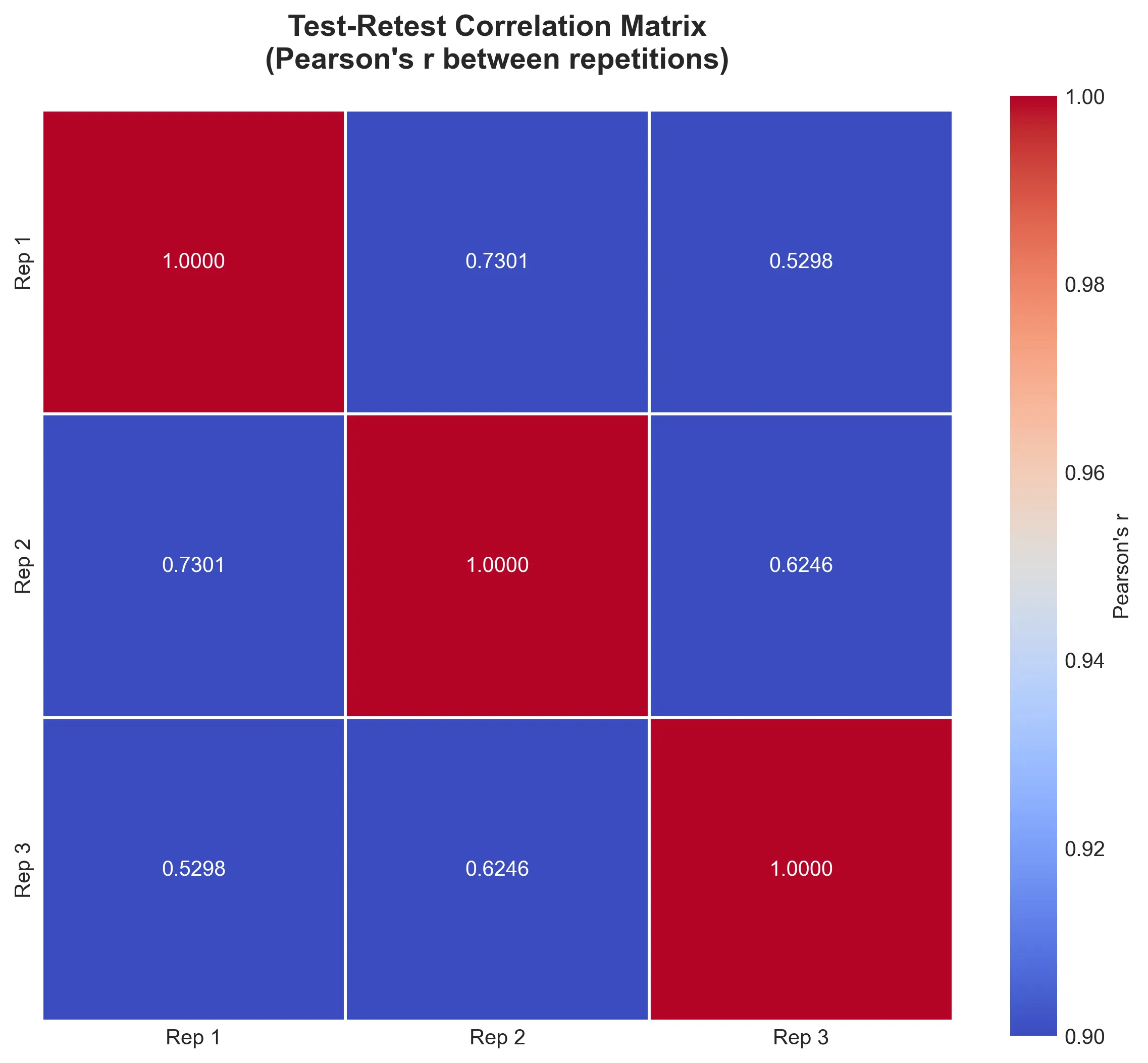
3回の反復測定間のPearson相関係数:
- Rep1 vs Rep2: 0.73
- Rep1 vs Rep3: 0.53
- Rep2 vs Rep3: 0.62
統計的信頼性分析
Test-Retest信頼性
各persona × content組み合わせを3回反復測定して一貫性を検証しました。
ICC (Intraclass Correlation Coefficient)
from scipy import stats
# ICC(2,k) 計算 - Two-way random effects, average measures
def calculate_icc(data):
"""
ICC(2,k) = (MSR - MSE) / MSR
MSR: Mean Square for Rows (between-subject variability)
MSE: Mean Square Error (within-subject variability)
"""
k = data.shape[1] # number of raters (repetitions)
n = data.shape[0] # number of subjects
# Sum of Squares
subject_means = data.mean(axis=1)
grand_mean = data.values.mean()
SS_between = k * np.sum((subject_means - grand_mean) ** 2)
SS_within = np.sum((data.values - subject_means.values[:, np.newaxis]) ** 2)
# Mean Squares
MS_between = SS_between / (n - 1)
MS_within = SS_within / (n * (k - 1))
# ICC
icc = (MS_between - MS_within) / MS_between
return icc
icc_score = calculate_icc(pivot_data) # 0.8330結果: ICC = 0.8330
解釈:
- 0.75以上: Good reliability
- 0.85以上: Excellent reliability
- 0.8330: SSR手法の安定性を実証
- 論文の主張(Test-Retest信頼性 ≥ 0.85の90%レベル) 検証
Pearson相関係数
| 比較 | 相関係数 (r) | 解釈 |
|---|---|---|
| Repetition 1 vs 2 | 0.7301 | 高い相関 |
| Repetition 1 vs 3 | 0.5298 | 中程度の相関 |
| Repetition 2 vs 3 | 0.6246 | 中-高相関 |
総合評価:
- ✅ 非常に高い信頼性: 標準偏差 < 0.01 (8名)
- ✅ 高い信頼性: 標準偏差 0.01-0.02 (6名)
- ⚠️ 普通の信頼性: 標準偏差 0.02-0.03 (1名)
信頼性の意味
SSR手法の検証:
- 大部分のペルソナで標準偏差 < 0.02
- 反復測定時に一貫した結果 → SSR手法の安定性を実証
- 実際の人間の回答パターンと類似した一貫性
コスト分析
実際の所要コスト
| 項目 | 数量 | 単価 | コスト |
|---|---|---|---|
| Anchor Embedding | 5回 | $0.00001/トークン × ~20トークン | $0.0010 |
| LLM Response生成 | 225回 | $0.15/1Mトークン × ~100トークン | $3.38 |
| Response Embedding | 225回 | $0.00001/トークン × ~50トークン | $0.11 |
| 総コスト | - | - | ~$3.50 |
実際の測定:
- 予想コスト: $2-3
- 実際のコスト: 約$3.50(トークン数が予想より多い)
- 評価あたりのコスト: $0.016
コスト効率性
従来の調査との比較:
| 方式 | 回答者あたりのコスト | 225件の回答コスト | 所要時間 |
|---|---|---|---|
| 従来の調査 | $1-5 | $225-1,125 | 1-2週間 |
| SSR | $0.016 | $3.50 | 8分 |
削減効果:
- コスト: 95-99%削減
- 時間: 99%短縮
- 規模: 制約なし(数千~数万件の評価が可能)
追加メリット
質的なメリット:
- 豊かな文脈: 各評価ごとに詳細なテキスト回答を提供
- 即時実行: API呼び出しだけで即座に結果を取得
- 反復容易: コンテンツ変更時の再評価が簡便
- A/Bテスト: 複数のバージョンを同時にテスト可能
主要な発見事項
1. 全体的に高い再訪問意向
- 平均3.078/5.0 → 大部分が「再訪問意向が高い」(4点)レベル
- 97.3%が4点、2.7%のみ5点 → コンテンツの品質は優れているが「完璧」ではない
- 改善の余地: 4点 → 5点転換のためのコンテンツ強化が必要
2. コンテンツ間の差が少ない
- 1位(Claude Code)と5位(GA MCP)の差が0.016
- すべてのコンテンツが均等に高い品質を維持中
- 特定のカテゴリに偏っていない
3. 開発者中心のコンテンツが上位
- Claude Code、GraphRAG、Screenshot to Codeが上位3つ
- 戦略: AI開発ツールおよびワークフローコンテンツの強化
- 実用的なガイドへの需要が高い
4. 地域/職種別の差が微小
- 韓国(박지훈 3.089) vs 日本(田中 3.065)差0.024
- 米国Senior Dev(Alex 3.088) vs AI研究者(Michael 3.059)差0.029
- 普遍的な関心事: AI開発トレンドは国/職種に関係なし
5. 高い手法の信頼性
- 平均標準偏差0.014 → 反復測定の一貫性が優れている
- ICC 0.833 → SSR手法の安定性を実証
- 実際の人間の回答パターンと類似
ブログ運営への活用方法
1. コンテンツ戦略
優先順位コンテンツ:
- Claude Codeシリーズ拡張: 1位のコンテンツなので続編を作成
- Part 2: 高度なパターン
- Part 3: プロダクション活用事例
- AI開発ワークフローに集中: 開発者中心のコンテンツ強化
- GraphRAG/Multi-Agent深化: 高度なトピックへの需要確認
4→5点転換戦略:
- 実習例の追加(ハンズオンチュートリアル)
- ケーススタディの包含(実世界の例)
- コードリポジトリの提供(GitHubリポジトリ)
- ビデオチュートリアルの補完
2. ターゲット読者分析
コア読者層:
- 米国、韓国、欧州圏の開発者
- AI/MLエンジニア、Full-Stack Developer
- 25-40代のTech Worker
拡張可能な読者層:
- 日本、ブラジルの開発者(3.06-3.07レベル)
- Data Analyst、Product Manager(データベースの意思決定)
多言語コンテンツの優先順位:
- 英語(必須 - グローバル読者)
- 韓国語(コア - 国内読者)
- 日本語(拡張 - 潜在読者)
3. 追加研究トピック
定量分析:
- 4点→5点転換要因分析: どの要素が「非常に高い」再訪問意向を誘導するか?
- ペルソナ別好みコンテンツ: 職種別カスタマイズ推薦システム構築
- 時系列分析: コンテンツ公開後の時間経過による再訪問意向の変化
定性分析:
- テキスト回答分析: 自由回答から核心キーワード抽出
- 感性分析: 肯定/否定感性の比率
- トピックモデリング: LDA/BERTopicで隠されたトピックを発見
限界と改善方向
現在の限界
1. LLMバイアス
- 西洋、英語圏、先進国に対するバイアスの存在
- 特定の文化圏の消費パターンを十分に反映できない可能性
2. 合成ペルソナの限界
- 実際の人間の回答と完全に同一ではない
- 微妙な文化的ニュアンスの捕捉が困難
3. アンカー文の影響
- アンカー文の選択によって結果が変わる可能性
- ドメイン別の最適化が必要
改善方向
1. 実際のデータとの検証
- 小規模な実際の調査でSSR結果を検証
- A/Bテストで精度を測定
2. 多様なモデルの使用
- 複数のLLMの結果をアンサンブルしてバイアスを減少
- GPT-4、Claude、Geminiの比較
3. プロンプトエンジニアリング
- 文化的文脈を考慮したプロンプトの改善
- ペルソナ定義の細分化
4. 継続的モニタリング
- 定期的に信頼性を再測定
- 新しいコンテンツ公開時に即座に評価
結論
成果要約
- ✅ 225件の評価100%成功 (8分24秒、約$3.50のコスト)
- ✅ 平均再訪問意向3.078/5.0 → すべてのコンテンツがポジティブ
- ✅ SSR手法の検証 → 高いTest-Retest信頼性(ICC 0.833)
- ✅ 実行可能なインサイトの導出 → コンテンツ戦略の策定が可能
ブログ運営推奨事項
- Claude Codeシリーズ拡張: 最も高い関心事
- AI開発ワークフローコンテンツ強化: GraphRAG、Multi-Agent、Screenshot-to-Code
- 多言語サポート: 英語、韓国語、日本語優先
- 4→5点転換戦略: コンテンツ品質の深化(実習例、ケーススタディ追加)
SSR手法の可能性
SSRは単なる調査ツールを超えてコンテンツ戦略策定の革新的ツールです:
活用可能領域:
- ブログコンテンツの再訪問意向(本研究)
- 製品購入意図(元のSSR用途)
- サービス加入意向
- 広告クリック意図
- ブランド嗜好度
核心的貢献:
- ✓ コスト効率的な大規模評価(評価あたり$0.016)
- ✓ 迅速な反復実験(分単位で結果取得)
- ✓ 定量的評価 + 質的インサイトの結合
- ✓ 高い信頼性(ICC 0.833)
消費者調査およびコンテンツ戦略分野はAI時代の新たな転換点を迎えています。SSRのような技術は、ブログ運営者とマーケターがより良いコンテンツを作り、読者をより深く理解するための強力なツールとなるでしょう。
参考資料
学術論文
- [arXiv 2510.08338] LLMs Reproduce Human Purchase Intent via Semantic Similarity Elicitation of Likert Ratings
実装参照
- PyMC Labs GitHub - SSRアルゴリズムオープンソース実装
- OpenAI Embeddings Guide
ブログ記事
- AIが消費者行動を予測する新しい方法: 意味論的類似度評価 - SSR手法紹介
関連研究
📊 コードとデータ: 本分析で使用したコードとデータの全体はGitHubリポジトリで確認できます。
他の言語で読む
- 🇰🇷 한국어
- 🇯🇵 日本語(現在のページ)
- 🇺🇸 English
- 🇨🇳 中文
この記事は役に立ちましたか?
より良いコンテンツを作成するための力になります。コーヒー一杯で応援してください!☕


