TurboQuant:KV Cache 3位量化与零精度损失
Google发布TurboQuant:PolarQuant+QJL双技术组合实现KV cache内存节省6倍、attention加速8倍,但精度真的零损失吗?
昨天(3月25日),Google Research博客发布了一篇文章,瞬间在半导体业界引发震动。这项名为TurboQuant的KV cache压缩技术,声称内存节省6倍、attention计算加速8倍,且精度损失为零。说实话,第一眼看到时,我的第一反应是”又是一篇基准测试cherry-picking”。
然而读完论文后,发现其数学推导出乎意料地严谨,TechCrunch甚至发文将其比作《硅谷》剧中的Pied Piper。论文预计在ICLR 2026发表,学术层面的同行评审也即将到来。今天就来拆解这项技术究竟如何运作,以及它对LLM推理成本意味着什么。
KV Cache为何是瓶颈
LLM推理中最大的内存瓶颈并非模型权重本身,而是KV cache。Transformer的attention机制需要存储所有历史token的Key和Value向量,上下文越长,这个缓存就线性增长。
具体数字来看:
- Llama 3.1 405B模型,128K上下文长度下,仅KV cache就占用数十GB
- 在H100 80GB VRAM中加载模型本体之后,留给KV cache的空间所剩无几
- 想通过增大batch size提升吞吐量,却受限于内存不足
此前也有大量用量化来解决这一问题的尝试,INT8、INT4量化是典型方案,但降到3位以下时精度明显下滑,这是难以逾越的限制。
TurboQuant的两个核心思路
TurboQuant将两项独立技术组合在一起。
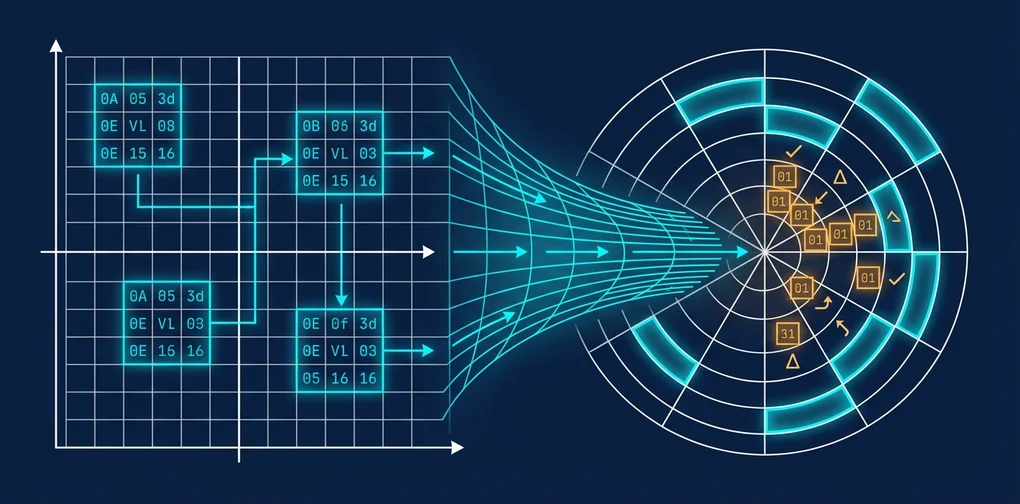
1. PolarQuant — 极坐标变换消除归一化
传统量化先对向量做归一化,再进行标量量化。问题在于归一化过程中必须单独存储范数(norm),这个环节会累积误差。
PolarQuant翻转了这一思路。它将向量从直角坐标(Cartesian)转换为极坐标(Polar)。在极坐标中,方向(角度)与幅度(半径)天然分离,归一化步骤本身就变得多余。只需对角度分量做均匀量化,误差便大幅降低。
我认为这个切入点相当聪明。它没有寻求”更好的量化算法”,而是通过”换一套坐标系来让问题本身变简单”——这种解题思路值得借鉴。
2. QJL — 1位符号校正消除偏差
量化的第二个敌人是偏差(bias)。对量化后的向量做内积运算时,会产生系统性误差,若忽略不计,attention score就会出现偏移。
QJL(Quantized Johnson-Lindenstrauss)借用JL变换这一降维技术,以1位符号校正的方式消除量化偏差。据称额外内存开销极小,计算overhead几乎可以忽略不计。
# 概念性伪代码 — 实际实现请参阅论文
def turboquant_attention(Q, K, V):
# 1. 将Key/Value转换为极坐标后进行3位量化
K_polar = to_polar(K)
K_quant = uniform_quantize(K_polar.angles, bits=3)
# 2. 生成QJL 1位符号校正
sign_correction = qjl_sign_bits(K, Q)
# 3. 计算经校正的attention score
scores = corrected_dot_product(Q, K_quant, sign_correction)
return softmax(scores) @ quantize(V, bits=3)用数字看性能
| 指标 | FP16(基线) | TurboQuant(3位) | 改善幅度 |
|---|---|---|---|
| KV Cache内存 | 基线 | 1/6 | 节省6倍 |
| Attention计算速度 | 基线 | 8倍 | H100基准 |
| 精度(perplexity) | 基线 | 相同 | 无损失 |
| 模型重新训练 | - | 无需 | drop-in |
尤其值得关注的是”无需重新训练”这一点。这意味着可以直接插入现有模型使用,已部署的生产系统同样可以立即应用。
坦率的疑问
当然,我也有几点存疑,逐一来看。
第一,“零精度损失”是否在所有任务上都成立,目前尚不明确。 论文展示的perplexity指标确实如此,但在长文本生成或复杂推理任务上是否能保持同等质量,仍需独立验证。还要看ICLR审稿人会要求补充哪些实验。
第二,实际生产环境中的实现复杂度尚不透明。 实时执行极坐标变换和QJL符号校正,大概率需要自定义CUDA kernel,而这能否直接集成到vLLM或TensorRT-LLM等框架中,是另一个问题。
第三,市场对内存半导体行业的解读明显过度。 TurboQuant消息发布后,据报道内存半导体股价略有下滑,但说实话,这是过度反应。KV cache内存节省若想真正减少HBM需求,前提是所有推理框架都采用这一技术,而那至少需要1到2年时间。
为何值得关注
尽管提出了批评,我仍然认为这项研究的方向本身具有重要价值。
LLM推理成本的相当大一部分来自GPU内存。模型本体已经通过各类量化方案(GPTQ、AWQ、GGUF等)得到压缩,而KV cache相对来说一直是难以触碰的部分。TurboQuant所揭示的,是”无需扩展硬件规模,也能高效处理长上下文的路径”。
我个人最期待的应用场景是本地LLM。在24GB VRAM的消费级GPU上运行128K上下文,目前几乎是不可能的事,但如果KV cache能压缩6倍,整个局面将截然不同。如果llama.cpp生态系统能实现这项技术,那将会非常有趣。
参考资料
阅读其他语言版本
- 🇰🇷 한국어
- 🇯🇵 日本語
- 🇺🇸 English
- 🇨🇳 中文(当前页面)
这篇文章有帮助吗?
您的支持能帮助我创作更好的内容。请我喝杯咖啡吧。