LangGraph多智能体系统完全指南:从核心概念到生产部署
详细了解如何使用LangGraph在生产环境中构建可扩展的多智能体AI系统,涵盖核心概念、架构模式、实战代码示例和最佳实践,助力打造企业级AI应用
概述
随着AI智能体系统变得越来越复杂,仅靠单一智能体难以解决的问题也在不断增加。在这种情况下,多智能体系统(Multi-Agent Systems)提供了一个强大的范式,通过多个专业化智能体的协作来解决复杂任务。
LangGraph是由LangChain团队开发的生产级基于图的编排框架(Orchestration Framework),可以构建有状态的(stateful)多智能体AI系统。LinkedIn、Uber、Replit、Klarna、Elastic等企业已经在生产环境中使用LangGraph。
本文将从LangGraph的核心概念到实战代码示例、生产部署指南全面覆盖所有内容。
LangGraph的核心概念
基于图的架构
LangGraph最大的特点是基于图的架构(Graph-based Architecture)。与传统的线性链(Chain)方式不同,图提供了以下优势:
- 循环工作流(Cyclic Workflows): 智能体可以反复执行任务
- 条件分支(Conditional Branching): 根据情况选择不同的路径
- 并行执行(Parallel Execution): 多个智能体可以同时工作
graph TD
Start[开始] --> Supervisor[监督智能体]
Supervisor -->|研究任务| Researcher[研究智能体]
Supervisor -->|编码任务| Coder[编码智能体]
Supervisor -->|审查任务| Reviewer[审查智能体]
Researcher --> Supervisor
Coder --> Supervisor
Reviewer --> End[结束]状态管理系统
LangGraph提供了强大的状态管理系统(State Management System)。通过这个系统可以:
- 检查点(Checkpointing): 随时保存和恢复工作流
- 状态持久化(State Persistence): 将状态保存到数据库以支持长时间运行的任务
- Human-in-the-Loop: 在关键决策点获得人类的批准
节点和边
LangGraph的图由两个核心要素组成:
- 节点(Nodes): 表示智能体或任务
- 边(Edges): 定义工作流的流向
- 普通边(Normal Edges): 始终执行的固定路径
- 条件边(Conditional Edges): 根据状态动态选择下一个节点
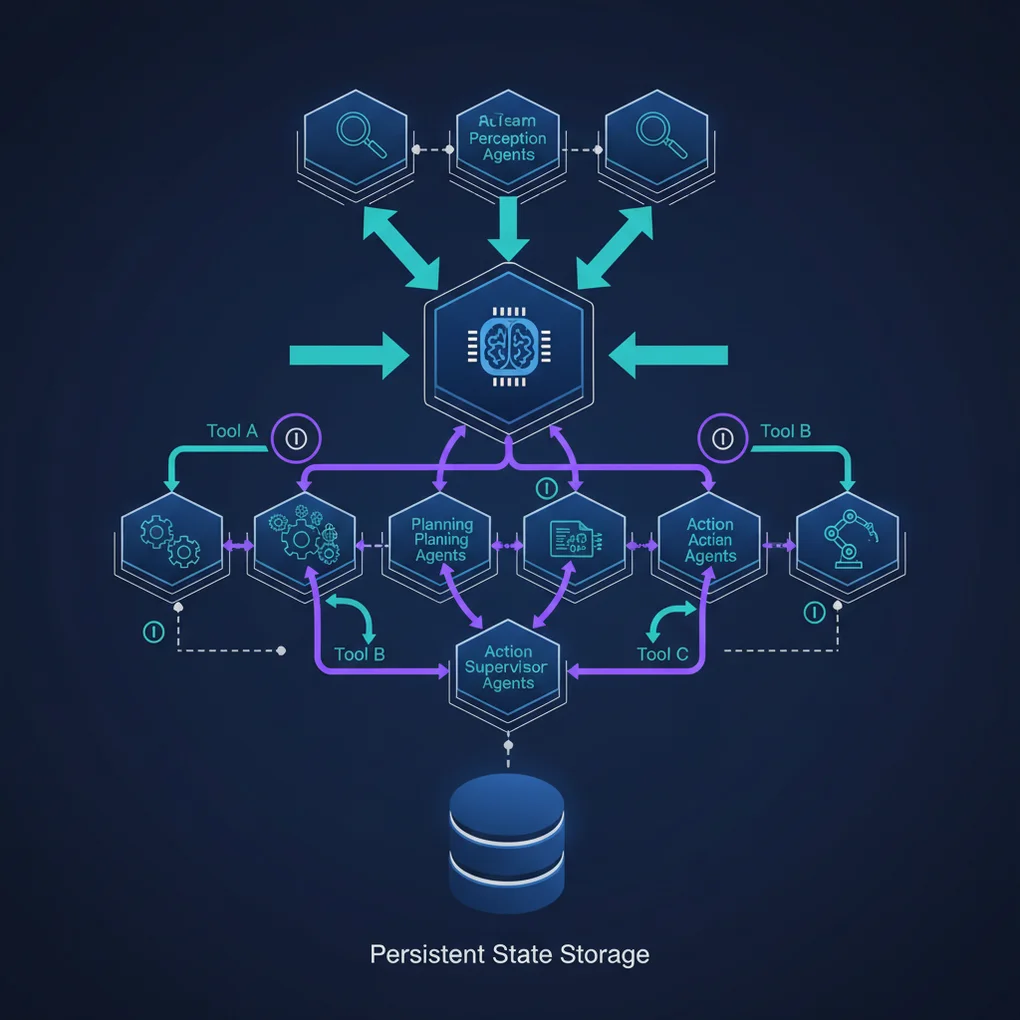
多智能体架构模式
1. 监督者模式
监督者模式(Supervisor Pattern)是由中央协调者智能体管理多个工作者智能体的结构。
graph TD
User[用户请求] --> Supervisor[监督者]
Supervisor -->|任务分配| Agent1[智能体1]
Supervisor -->|任务分配| Agent2[智能体2]
Supervisor -->|任务分配| Agent3[智能体3]
Agent1 -->|结果报告| Supervisor
Agent2 -->|结果报告| Supervisor
Agent3 -->|结果报告| Supervisor
Supervisor -->|最终响应| User优势:
- 明确的职责分离
- 易于管理任务优先级
- 错误处理和重试逻辑集中化
2. 层次化模式
层次化模式(Hierarchical Pattern)通过设置多层监督者来建模复杂的组织结构。
使用场景:
- 大规模软件开发项目
- 复杂的研究工作
- 多阶段决策过程
3. 网络模式
网络模式(Network Pattern)是智能体直接通信和协作的结构。无需中央协调者,采用点对点(P2P)方式运作。
4. 群集模式
群集模式(Swarm Pattern)是大量简单智能体协作解决复杂问题的模式。模仿自然界的群体智能。
实战代码示例
基础多智能体系统
以下是研究智能体和写作智能体协作的基础多智能体系统:
from typing import TypedDict, Annotated
from langgraph.graph import StateGraph, END
from langchain_openai import ChatOpenAI
from langchain.agents import create_openai_functions_agent
from langchain.tools import Tool
# 状态定义
class AgentState(TypedDict):
messages: Annotated[list, "消息列表"]
next_agent: str
research_result: str
final_output: str
# LLM初始化
llm = ChatOpenAI(model="gpt-4", temperature=0)
# 研究智能体函数
def research_agent(state: AgentState) -> AgentState:
"""执行主题研究的智能体"""
messages = state["messages"]
user_query = messages[-1]["content"]
# 实际应用中这里会使用搜索工具
research_prompt = f"请详细调查以下主题: {user_query}"
research_result = llm.invoke(research_prompt).content
return {
**state,
"research_result": research_result,
"next_agent": "writer"
}
# 写作智能体函数
def writer_agent(state: AgentState) -> AgentState:
"""基于研究结果编写内容的智能体"""
research_result = state["research_result"]
writing_prompt = f"请基于以下研究结果编写博客文章:\n\n{research_result}"
final_output = llm.invoke(writing_prompt).content
return {
**state,
"final_output": final_output,
"next_agent": "end"
}
# 监督者函数(决定下一个智能体)
def supervisor(state: AgentState) -> str:
"""决定下一个执行的智能体"""
next_agent = state.get("next_agent", "researcher")
if next_agent == "end":
return END
return next_agent
# 图构建
workflow = StateGraph(AgentState)
# 添加节点
workflow.add_node("researcher", research_agent)
workflow.add_node("writer", writer_agent)
# 添加边
workflow.set_entry_point("researcher")
workflow.add_conditional_edges(
"researcher",
supervisor,
{
"writer": "writer",
END: END
}
)
workflow.add_conditional_edges(
"writer",
supervisor,
{
END: END
}
)
# 图编译
app = workflow.compile()
# 执行
result = app.invoke({
"messages": [{"role": "user", "content": "LangGraph的主要特征"}],
"next_agent": "researcher"
})
print(result["final_output"])层次化系统实现
更复杂的层次化多智能体系统示例:
from langgraph.graph import StateGraph, END
from typing import TypedDict, List
class HierarchicalState(TypedDict):
task: str
subtasks: List[str]
results: List[str]
final_result: str
# 管理者智能体(将任务分解为子任务)
def manager_agent(state: HierarchicalState) -> HierarchicalState:
"""将主任务分解为子任务"""
task = state["task"]
# 使用LLM进行任务分解
decompose_prompt = f"""
请将以下任务分解为3〜5个子任务:
{task}
每个子任务用一行描述。
"""
llm = ChatOpenAI(model="gpt-4")
response = llm.invoke(decompose_prompt).content
subtasks = [line.strip() for line in response.split('\n') if line.strip()]
return {
**state,
"subtasks": subtasks,
"results": []
}
# 工作者智能体(执行子任务)
def worker_agent(state: HierarchicalState) -> HierarchicalState:
"""按顺序处理子任务"""
subtasks = state["subtasks"]
results = []
llm = ChatOpenAI(model="gpt-4")
for subtask in subtasks:
# 执行每个子任务
result = llm.invoke(f"请执行以下任务: {subtask}").content
results.append(result)
return {
**state,
"results": results
}
# 整合智能体(整合结果)
def integrator_agent(state: HierarchicalState) -> HierarchicalState:
"""整合所有子任务结果"""
results = state["results"]
task = state["task"]
llm = ChatOpenAI(model="gpt-4")
integration_prompt = f"""
原始任务: {task}
子任务结果:
{chr(10).join(f"{i+1}. {r}" for i, r in enumerate(results))}
请整合这些结果并撰写最终答案。
"""
final_result = llm.invoke(integration_prompt).content
return {
**state,
"final_result": final_result
}
# 构建层次化工作流
hierarchical_workflow = StateGraph(HierarchicalState)
# 添加节点
hierarchical_workflow.add_node("manager", manager_agent)
hierarchical_workflow.add_node("worker", worker_agent)
hierarchical_workflow.add_node("integrator", integrator_agent)
# 顺序边
hierarchical_workflow.set_entry_point("manager")
hierarchical_workflow.add_edge("manager", "worker")
hierarchical_workflow.add_edge("worker", "integrator")
hierarchical_workflow.add_edge("integrator", END)
# 编译和执行
hierarchical_app = hierarchical_workflow.compile()
result = hierarchical_app.invoke({
"task": "为在线商城制定完整的营销战略"
})
print(result["final_result"])生产部署指南
必须考虑的事项
在生产环境中部署LangGraph时需要考虑以下事项:
- 状态持久化
- 使用PostgreSQL、Redis等配置检查点器(Checkpointer)
- 为长时间运行的任务保存状态
from langgraph.checkpoint.postgres import PostgresSaver
# PostgreSQL检查点器设置
checkpointer = PostgresSaver.from_conn_string(
"postgresql://user:pass@localhost/dbname"
)
app = workflow.compile(checkpointer=checkpointer)-
错误处理和重试
- 在每个节点添加try-except块
- 指数退避(exponential backoff)重试逻辑
-
监控和日志
- 使用LangSmith进行追踪
- 收集每个智能体的性能指标
-
成本管理
- 优化LLM调用次数
- 使用缓存策略
最佳实践
-
定义清晰的状态模式
- 使用TypedDict确保类型安全
- 仅包含必要字段
-
设计小单元智能体
- 应用单一职责原则
- 构建可重用的智能体
-
利用条件路由
- 根据情况动态调整工作流
- 避免不必要的智能体执行
-
集成Human-in-the-Loop
- 在重要决策时添加人类批准
- 增强质量控制
与其他框架的比较
LangGraph vs CrewAI
| 特性 | LangGraph | CrewAI |
|---|---|---|
| 控制级别 | 高(可精细控制) | 中等(抽象级别高) |
| 学习曲线 | 陡峭 | 平缓 |
| 灵活性 | 非常高 | 中等 |
| 生产功能 | 完整(检查点、状态管理) | 基础 |
| 使用场景 | 复杂的自定义工作流 | 快速原型开发 |
应该选择LangGraph的情况:
- 需要精细控制的生产系统
- 需要复杂状态管理的场景
- 需要循环工作流的情况
应该选择CrewAI的情况:
- 快速原型开发为目标
- 简单的多智能体系统
- 缩短开发时间很重要的情况
LangGraph vs AutoGen
| 特性 | LangGraph | AutoGen |
|---|---|---|
| 架构 | 基于图 | 基于对话 |
| 结构化 | 显式工作流 | 自主对话 |
| 可预测性 | 高 | 低 |
| 调试 | 容易 | 困难 |
| 执行控制 | 完全控制 | 有限 |
应该选择LangGraph的情况:
- 可预测的工作流很重要
- 需要明确的职责分离
- 生产稳定性很重要
应该选择AutoGen的情况:
- 创造性和自主的智能体交互
- 探索性问题解决
- 灵活的对话模式
实际使用案例
LinkedIn - 招聘公告自动化
LinkedIn使用LangGraph构建了招聘公告撰写和优化系统:
- 研究智能体: 分析行业趋势和类似职位
- 写作智能体: 撰写招聘公告草稿
- SEO智能体: 搜索优化
- 审查智能体: 合规性和质量检查
Uber - 客户支持自动化
Uber实现了层次化多智能体系统来处理复杂的客户咨询:
- 分类智能体: 识别咨询类型
- 专业智能体: 按领域处理支付、出行、账户等
- 升级智能体: 将复杂案例连接到人工客服
Replit - 代码生成和调试
Replit利用LangGraph开发了基于AI的编码助手:
- 规划智能体: 分解编码任务
- 编码智能体: 实际编写代码
- 测试智能体: 运行自动测试
- 调试智能体: 修复错误
结论
LangGraph是构建生产级多智能体系统的强大而灵活的框架。通过基于图的架构、强大的状态管理和多样的架构模式,可以有效实现复杂的AI工作流。
应该使用LangGraph的情况:
- 需要复杂的多步骤工作流
- 状态持久化和检查点很重要
- 需要多个专业化智能体的协作
- 需要在生产环境中稳定运行
随着2025年10月即将发布的v1.0和LangGraph Platform GA,将添加更强大的功能,建议现在就开始学习和实验LangGraph。
参考资料
阅读其他语言版本
- 🇰🇷 한국어
- 🇯🇵 日本語
- 🇺🇸 English
- 🇨🇳 中文(当前页面)
这篇文章有帮助吗?
您的支持能帮助我创作更好的内容。请我喝杯咖啡吧!☕