
Qwen 3.5在Vending-Bench 2中破产 — 基准测试偏重的陷阱
在标准基准测试中名列前茅的Qwen 3.5,在自动售货机经营模拟Vending-Bench 2中破产。探讨基准测试偏重带来的AI评估盲区。
概述
阿里巴巴开发的大语言模型Qwen 3.5 Plus在MMLU、HumanEval、MATH等标准基准测试中始终位居前列。然而,在Andon Labs开发的非标准基准测试Vending-Bench 2中,该模型却得到了令人震惊的”破产”结果。这一发现在Reddit r/LocalLLaMA上获得了595+的点赞,引发了对AI评估方式的广泛讨论。
什么是Vending-Bench 2
Vending-Bench 2是Andon Labs开发的自动售货机经营模拟基准测试。它让AI模型运营虚拟自动售货机业务约365天,综合测量财务管理、决策制定和战略规划能力。
与传统基准测试不同,它测量以下实践能力:
- 长期战略思维:一年内的连续商业决策
- 财务风险管理:在盈利和可持续性之间保持平衡
- 适应力:应对变化的模拟环境
- 应用推理能力:不仅是知识,更是知识的应用
震惊的结果:Qwen 3.5垫底破产
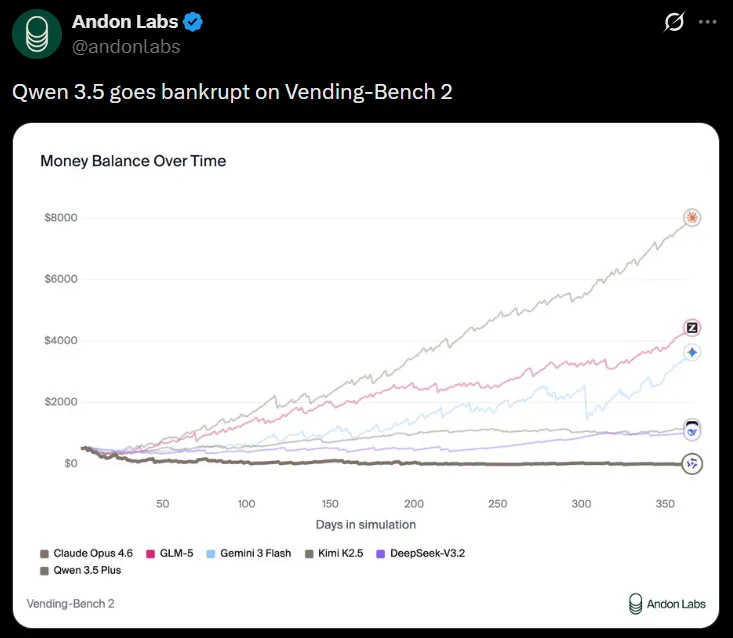
上图展示了各模型365天模拟的结果:
| 排名 | 模型 | 最终余额(估计) |
|---|---|---|
| 第1名 | GLM-5 | 约$8,000+ |
| 第2名 | Gemini 3 Flash | 约$4,000~$4,500 |
| 第3名 | Kimi K2.5 | 约$3,500~$4,000 |
| 第4名 | Claude Opus 4.6 | 约$2,000~$2,500 |
| 第5名 | DeepSeek-V3.2 | 约$200~$500 |
| 第6名 | Qwen 3.5 Plus | 约$0(破产) |
在标准基准测试中名列前茅的Qwen 3.5 Plus,以所有模型中最后一名、余额为零的结果收场。
为什么会出现这种差异
标准基准测试的局限性
graph TD
A[标准基准测试] --> B[知识测试<br/>MMLU, ARC]
A --> C[编程<br/>HumanEval, MBPP]
A --> D[数学<br/>MATH, GSM8K]
A --> E[推理<br/>BBH, HellaSwag]
F[Vending-Bench 2] --> G[长期战略]
F --> H[财务管理]
F --> I[风险判断]
F --> J[适应力]
style A fill:#e8f5e9
style F fill:#fff3e0标准基准测试擅长测量静态知识和单一任务,但无法衡量:
- 多步骤决策的一致性
- 不确定性下的判断力
- 考虑长期结果的战略思维
- 权衡取舍的评估与选择
基准测试优化问题
在AI模型开发中,提高标准基准测试分数已成为关键指标,这导致了”基准测试黑客”现象:
- 过拟合风险:专门针对类似基准测试的模式进行学习
- 泛化能力下降:牺牲了应对意外任务的能力
- 表面性能与实际性能的差距:数字好看但实际不好用
社区反应
Reddit r/LocalLLaMA的讨论中出现了以下观点:
- “活跃参数数 ≠ 智能”:模型规模不能决定能力
- 架构的重要性:MoE(混合专家)路由效率显著影响结果
- 训练数据质量:不仅是数量,质量和多样性同样重要
GLM-5以超过$8,000的利润位居榜首也值得关注。在标准基准测试中排名低于Qwen 3.5的模型,在实际任务中可能表现出压倒性优势。
AI评估的未来方向
多维评估的必要性
graph LR
A[AI评估的未来] --> B[标准基准测试<br/>知识与推理]
A --> C[实践基准测试<br/>Vending-Bench等]
A --> D[领域特化评估<br/>医疗·法律·金融]
A --> E[人类评估<br/>Chatbot Arena等]
B --> F[综合<br/>模型评估]
C --> F
D --> F
E --> F这次结果清楚表明,不应仅凭单一基准测试来判断模型优劣:
- 多维评估:从知识、推理、实践、创造力等多个维度评估
- 真实世界模拟:推广Vending-Bench等实践基准测试
- 领域特化评估:针对使用目的的专业测试
- 持续监测:在各种条件下持续评估,而非一次性测试
结论
Qwen 3.5 Plus在Vending-Bench 2中的破产,象征性地揭示了基准测试偏重AI评估的危险性。标准基准测试中的顶尖模型在实际场景中可能垫底,这一事实提醒我们在选择AI模型时需要看透数字背后的真实能力。
衡量AI的真正能力,不仅需要标准化测试,更需要反映现实世界复杂性的多样化基准测试。
参考资料
阅读其他语言版本
- 🇰🇷 한국어
- 🇯🇵 日本語
- 🇺🇸 English
- 🇨🇳 中文(当前页面)
这篇文章有帮助吗?
您的支持能帮助我创作更好的内容。请我喝杯咖啡吧!☕


