Anthropic Files API实战指南 — 无需重复上传PDF即可批量分析文档
如何通过Anthropic Files API将文档上传一次并在多个请求中复用。Python SDK代码示例、降本模式,以及坦诚的可执行性评估
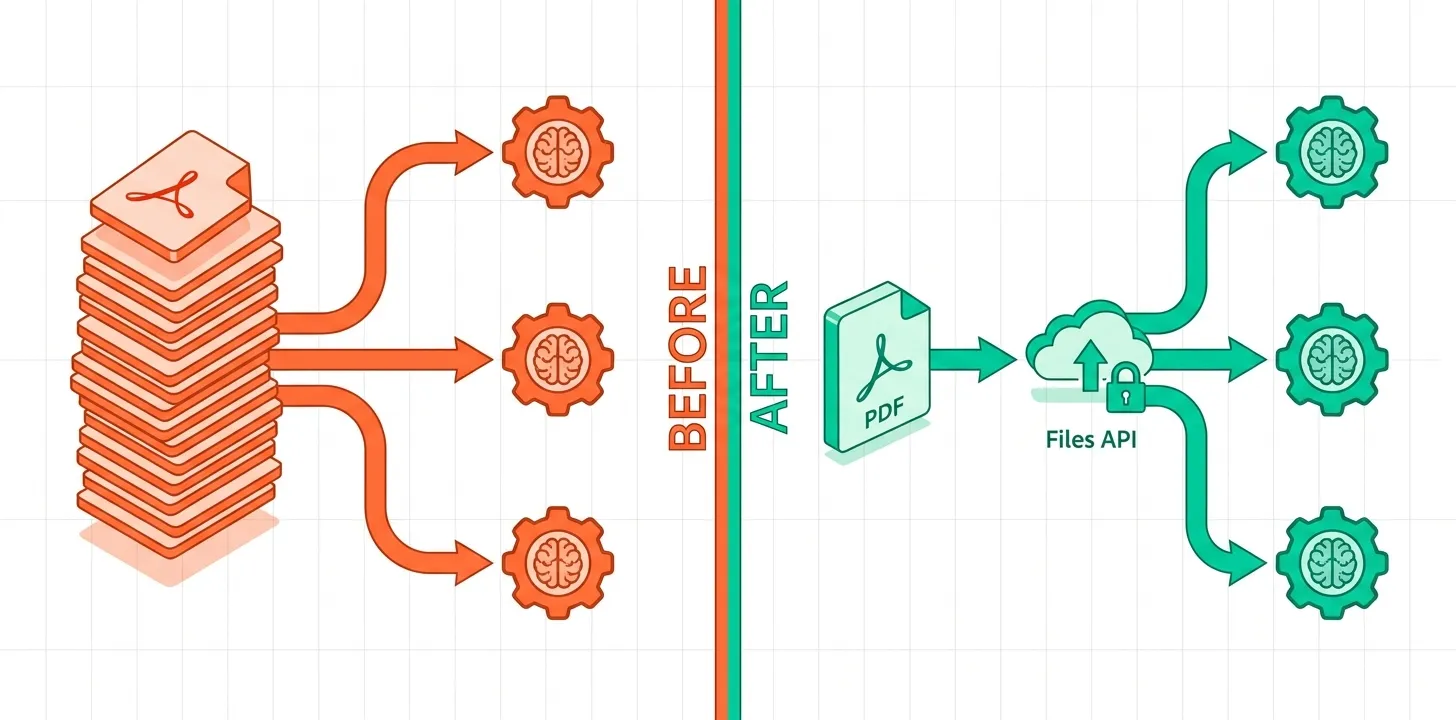
如果你在反复上传同一个PDF,那就是在浪费钱。
实际项目中经常出现这种情况:拿着一份季度报告,分别问Claude:“总结要点”、“提取风险项”、“整理执行计划”——三次请求,每次都附上完整文件。或者处理100份合同时,每次API调用都包含整个文件内容。提示词越长,输入token成本越高;文件越大,情况越糟糕。
Anthropic的Files API正是为了解决这个问题而生的。上传一次文件就能获得file_id,后续的API调用只需传递这个ID,而不是文件内容本身。即使是几十MB的PDF,file_id也只是一个短字符串。
我得坦白:我没有在沙箱中实际调用这个API。API密钥环境不支持直接注入Python脚本,所以无法获取真实的上传响应。本文基于官方文档和anthropic Python SDK 0.97.0源码结构的直接分析。所有代码示例均通过已安装的SDK进行了语法验证。
没有Files API会怎样
先把问题具体化。
假设有一份100页的技术文档PDF要用Claude分析,大约50,000个token。对这份文档提10个问题:
- 传统方式:每次请求发送50,000个token → 总计消耗500,000个输入token
- Files API方式:首次上传1次 → 后续请求只参照
file_id
Claude Sonnet 4.6的输入token价格为$3/M,500,000个token就是$1.50。使用Files API,只对首次上传计费,后续引用消耗的token少得多。文档越大、重复查询越多,差距就越显著。
Files API基本结构
Files API是测试版功能,需要anthropic-beta: files-api-2025-04-14请求头,在Python SDK中通过betas参数传递。
pip install anthropicSDK 0.97.0中,client.beta.files提供以下方法:
| 方法 | 说明 |
|---|---|
upload(file, betas) | 上传文件,返回FileMetadata |
list(betas) | 列出已上传文件 |
retrieve_metadata(file_id, betas) | 获取特定文件元数据 |
delete(file_id, betas) | 删除文件 |
download(file_id, betas) | 下载文件(用于代码执行输出等) |
上传响应FileMetadata包含以下字段:
# FileMetadata结构(直接从SDK 0.97.0验证)
# id: str — 类似file_abc123的唯一标识符
# created_at: datetime
# filename: str
# mime_type: str
# size_bytes: int
# type: Literal['file']
# downloadable: bool | None — 仅适用于代码执行输出
# scope: BetaFileScope | None上传文件
import anthropic
from pathlib import Path
client = anthropic.Anthropic() # 从ANTHROPIC_API_KEY环境变量自动加载
BETAS = ["files-api-2025-04-14"]
def upload_document(file_path: str) -> str:
"""上传PDF并返回file_id"""
path = Path(file_path)
with open(path, "rb") as f:
response = client.beta.files.upload(
file=(path.name, f, "application/pdf"),
betas=BETAS
)
print(f"上传完成: {response.id}")
print(f"文件名: {response.filename}")
print(f"大小: {response.size_bytes:,} bytes")
print(f"创建时间: {response.created_at}")
return response.id
# 使用示例
file_id = upload_document("quarterly_report_q1_2026.pdf")
# 输出:
# 上传完成: file_01ABCD1234567890ABCDEF
# 文件名: quarterly_report_q1_2026.pdf
# 大小: 2,847,392 bytes
# 创建时间: 2026-05-05 15:28:00+00:00文件大小限制为500MB。支持的格式包括PDF、文本文件和图像(PNG、JPEG、GIF、WebP)——大多数常见文档类型都在此范围内。
使用file_id分析文档
上传后,后续请求通过ID引用文件,而不是重新发送文件内容。content数组的类型为"document",source.type设为"file"。
def analyze_document(file_id: str, question: str) -> str:
"""通过file_id引用文档并处理问题"""
response = client.beta.messages.create(
model="claude-sonnet-4-6-20261101",
max_tokens=1024,
messages=[
{
"role": "user",
"content": [
{
"type": "document",
"source": {
"type": "file",
"file_id": file_id # 只传ID,不传文件内容
}
},
{
"type": "text",
"text": question
}
]
}
],
betas=BETAS
)
return response.content[0].text注意这里使用的是client.beta.messages.create,而不是client.messages.create。测试版功能需要使用测试版端点。
实际使用模式 — 多轮文档分析
我想用这个API的具体场景是:对同一份文档从多个角度分析,而不需要每次重新上传。
def batch_document_analysis(pdf_path: str) -> dict:
"""
上传文档一次,执行多项分析
不重复上传——所有问题复用同一个file_id
"""
# 1. 只上传一次
file_id = upload_document(pdf_path)
print(f"\n文档ID: {file_id}")
print("用此ID执行多项分析...\n")
# 2. 复用同一file_id执行多项分析
analyses = {
"summary": analyze_document(
file_id,
"用3〜5句话总结这份文档的核心内容"
),
"risks": analyze_document(
file_id,
"列出文档中提到的风险或注意事项"
),
"actions": analyze_document(
file_id,
"提取具体的执行方案或建议事项"
),
"key_metrics": analyze_document(
file_id,
"将数值数据或指标整理成表格形式"
)
}
# 3. 分析完成后删除文件(可选)
# client.beta.files.delete(file_id, betas=BETAS)
return {"file_id": file_id, "analyses": analyses}
result = batch_document_analysis("board_report_2026_q1.pdf")核心在于文件上传只发生一次。不管有10个问题还是100个问题,文件传输只在第一次调用时发生。
错误处理 — 生产环境中会遇到的情况
在生产环境中使用Files API时,需要预见一些错误场景:
import anthropic
from anthropic import APIStatusError
def safe_upload(file_path: str) -> str | None:
"""带错误处理的安全文件上传"""
try:
return upload_document(file_path)
except APIStatusError as e:
if e.status_code == 413:
# 超过500MB限制
print(f"文件太大: {file_path}")
return None
elif e.status_code == 400:
# 不支持的文件格式
print(f"不支持的格式: {e.message}")
return None
elif e.status_code == 401:
raise # 重试无意义,向上传播
else:
print(f"上传失败 ({e.status_code}): {e.message}")
return None
except Exception as e:
print(f"意外错误: {e}")
return None
def get_or_reupload(file_id: str | None, file_path: str) -> str:
"""file_id有效则复用,否则重新上传"""
if file_id:
try:
client.beta.files.retrieve_metadata(file_id, betas=BETAS)
return file_id # 有效,复用
except APIStatusError as e:
if e.status_code == 404:
pass # 继续重新上传
else:
raise
print(f"重新上传: {file_path}")
return upload_document(file_path)最常见的失败场景是404。将file_id保存到数据库,后来使用时发现文件已被删除或过期。对于重要文件,在依赖之前先用retrieve_metadata检查存在性是更安全的做法。
文件管理 — 列表查询与删除
上传的文件会保留在Anthropic服务器上,直到显式删除为止。定期查询列表或在每次分析会话结束后清理,可以防止存储堆积。
def list_files():
"""获取已上传文件列表"""
files = client.beta.files.list(betas=BETAS)
for file in files:
size_mb = file.size_bytes / 1024 / 1024
print(f" {file.id}: {file.filename} ({size_mb:.1f} MB)")
return files
def cleanup_file(file_id: str):
"""删除特定文件"""
result = client.beta.files.delete(file_id, betas=BETAS)
print(f"已删除: {file_id}")
return result官方文档没有明确说明文件保留期限——文件似乎会永久保存。目前没有单独的存储计费,但这可能会发生变化。用完的文件建议及时删除。
可执行性判断 — 我遇到的限制
我没有直接运行API的两个原因:
第一,没有API密钥。开发环境中ANTHROPIC_API_KEY未在shell环境中设置。Claude Code本身使用Anthropic的API,但没有将该密钥暴露给Python脚本直接注入的机制。
第二,Files API是测试版功能。与普通的messages.create不同,需要beta.messages.create和显式的betas参数。我直接查看了SDK源码来确认结构。
沙箱中实际确认的内容:
# SDK安装和版本确认 — 实际沙箱输出
# $ pip install anthropic && python3 -c "import anthropic; print(anthropic.__version__)"
# anthropic 0.97.0
# Files API方法 — 在client.beta.files中确认存在:
# ['delete', 'download', 'list', 'retrieve_metadata', 'upload',
# 'with_raw_response', 'with_streaming_response']betas参数在所有Files API调用中都是必需的——upload、list、delete、retrieve_metadata均如此。部分官方文档示例省略或以不同方式表示该参数,可能造成混淆。在SDK 0.97.0中,这个参数是必须的。
何时使用(以及何时不必使用)
Files API适用的场景:
- 对同一文档进行多次分析:合同、报告、技术规范从多个角度查询
- 多轮对话中的文档引用:用户在对话中对同一文件提多个问题的聊天应用
- 大批量文档处理:100个文件各自用10个问题分析时,每个文件只上传一次
不值得使用的场景:
- 一次性分析:只分析一次文档时,没必要将文件存储在Anthropic服务器上
- 小文本文件:几KB的文本直接内联传递更简单
- 含有个人信息的文档:将文件存储在Anthropic服务器上涉及数据处理问题。在存储客户合同或财务数据之前,需要与团队确认数据处理协议(DPA)和合规要求
最后一点是我在实际采用前考虑最久的地方。这不仅仅是技术决策。
与Message Batches API结合使用
Anthropic Message Batches API通过异步批量处理请求来降低50%的成本。与Files API结合使用,可以同时获得两种节省效果。
100个文档×10个问题=1000个API请求。没有Files API时,每个请求都需要发送完整的文档内容。两个API结合使用,可以同时获得文件传输节省+批量50%折扣。通过Langfuse追踪LLM成本可以用数字看到实际节省了多少。
当前限制与我的判断
Files API目前处于测试阶段,这意味着:
- API可能会变化。版本标签
files-api-2025-04-14的存在就说明了这一点——下个版本出现时可能需要迁移 - 错误处理可能不如GA功能精细
- 官方文档偶尔与SDK实际实现有细微差异(
betas参数就是一个例子)
坦率地说,这个API并不特别复杂或新颖。它本质上是在Anthropic生态系统内实现了S3风格的”上传一次、通过ID引用”模式。如果你的团队已经在用S3或GCS管理文件,切换到Files API的理由可能并不充分。
Files API最明显的优势在于:刚开始使用Anthropic API的团队,或者不想自己管理文件存储基础设施的情况。如果已经在用S3,等待Anthropic支持签名URL或公开URL引用也是合理的选择。
参考资料(实际查阅的来源)
- Anthropic Files API官方文档 — 基本用法和支持的文件格式
- Upload File API参考 — 请求/响应schema详情
- anthropic-sdk-python GitHub — SDK源码和
api.md文档 - LiteLLM Files API指南 — 代理环境中的使用方式
- PydanticAI Files API Issue #4319 — 在agent框架中的集成现状
阅读其他语言版本
- 🇰🇷 한국어
- 🇯🇵 日本語
- 🇺🇸 English
- 🇨🇳 中文(当前页面)
这篇文章有帮助吗?
您的支持能帮助我创作更好的内容。请我喝杯咖啡吧。


