Anthropic Message Batches API 实战指南 — 大规模LLM请求成本降低50%的方法
深入讲解Anthropic Message Batches API:将最多100,000个请求合并为单次批量处理,成本立降50%。结合Prompt Caching,最高可节省95%。附Node.js和Python完整代码示例。
LLM API的成本往往在规模扩大的那一刻才真正显现出来。小型POC阶段账单看起来还过得去,但当每月请求量达到几十万次,清单上的数字就开始让人心跳加速。Anthropic的Message Batches API正是为这个临界点设计的——单次API调用可以打包最多100,000个请求,成本直接减半。
第一次了解这个功能时,我的第一反应是”不就是把异步队列包成API”。这个判断有一半是对的,但忽略了几个让它和普通队列行为不同的设计决策。本文整理了这些差异,并附上可以直接使用的代码。
Message Batches API是什么
Anthropic Message Batches API允许将多个独立的Claude消息请求打包进行异步处理。支持REST API和官方SDK(Python、TypeScript/Node.js)。
端点结构:
POST /v1/messages/batches → 创建批次
GET /v1/messages/batches/{id} → 查询状态
GET /v1/messages/batches/{id}/results → 流式获取结果(JSONL)
POST /v1/messages/batches/{id}/cancel → 取消批次
GET /v1/messages/batches → 列出批次(分页)成本折扣:输入和输出token均享受标准定价的50%折扣,适用于所有支持的模型。
| 模型 | 批量输入 | 批量输出 | 标准输入 | 标准输出 |
|---|---|---|---|---|
| Claude Opus 4.7 | $2.50/MTok | $12.50/MTok | $5.00/MTok | $25.00/MTok |
| Claude Sonnet 4.6 | $1.50/MTok | $7.50/MTok | $3.00/MTok | $15.00/MTok |
| Claude Haiku 4.5 | $0.50/MTok | $2.50/MTok | $1.00/MTok | $5.00/MTok |
处理时间:大多数批次在1小时内完成。最大超时为24小时。超时后过期的请求不计费。
规模限制:每批最多100,000个请求或256MB,以先触及者为准。结果在创建后保留29天。
什么时候用Batches API
适用场景和不适用场景都很明确。用错了反而会让体验变差。
适用场景:
- 大规模评估(evals)流水线:将数千个测试用例在夜间批量运行,每次升级模型或调整提示词时重跑全套测试,成本减半
- 离线批量内容生成:10万条商品描述、5万篇文章摘要等大批量任务
- 数据分析与分类:用户生成内容的情感分析、内容审核
- 夜间ETL流水线:次日早上需要结果的日志分析、报告生成
- 模型对比实验:大规模A/B测试提示词变体
不适用场景:
- 用户实时等待响应的聊天界面
- 需要流式输出(SSE)的场景 — Batches API不支持流式
- 需要毫秒级延迟的实时推荐系统
- 下一步请求依赖上一步结果的顺序工作流(如Agent循环)
我的判断基准只有一个问题:“用户在24小时内收到这个响应是否可以接受?“如果可以,就值得考虑Batches API。
实战代码:Node.js SDK实现
在沙盒中安装了@anthropic-ai/sdk并验证了代码结构。没有API密钥时,SDK返回AuthenticationError (401) — 这证明端点真实存在,请求实际到达了Anthropic服务器。
$ npm install @anthropic-ai/sdk创建批次
import Anthropic from "@anthropic-ai/sdk";
const client = new Anthropic({ apiKey: process.env.ANTHROPIC_API_KEY });
// 示例:批量生成商品描述
const batchRequests = products.map((p) => ({
custom_id: p.id, // 关键:用于映射结果的唯一ID
params: {
model: "claude-haiku-4-5",
max_tokens: 200,
system: "You are a concise product copywriter.",
messages: [
{
role: "user",
content: `Write a 2-sentence description for: ${p.name} (${p.category})`,
},
],
},
}));
const batch = await client.messages.batches.create({
requests: batchRequests,
});
console.log(`Batch created: ${batch.id}`);
// → msgbatch_01ABCDEF...
console.log(`Request counts:`, batch.request_counts);
// → { processing: 3, succeeded: 0, errored: 0, canceled: 0, expired: 0 }custom_id看起来不起眼,但实际上是整个API中最关键的设计决策之一。结果的顺序不保证。发送1,000个请求,结果可能以任意顺序返回。用数组下标来对应请求和结果,数据会悄无声息地被错误映射。只有custom_id是安全的。
格式要求:1〜64字符,仅允许字母、数字、连字符和下划线。正则:^[a-zA-Z0-9_-]{1,64}$。
轮询等待完成
async function waitForBatch(client, batchId) {
while (true) {
const batch = await client.messages.batches.retrieve(batchId);
const { processing, succeeded, errored, expired } = batch.request_counts;
console.log(
`[${new Date().toISOString()}] status=${batch.processing_status}` +
` | processing=${processing} succeeded=${succeeded}`
);
if (batch.processing_status === "ended") return batch;
await new Promise((r) => setTimeout(r, 30_000)); // 30秒间隔
}
}流式处理结果
async function processResults(client, batchId) {
const results = new Map();
for await (const result of await client.messages.batches.results(batchId)) {
switch (result.result.type) {
case "succeeded":
results.set(result.custom_id, {
text: result.result.message.content[0].text,
usage: result.result.message.usage,
});
break;
case "errored":
console.error(`Error: ${result.custom_id}`, result.result.error);
break;
case "expired":
console.warn(`Expired (not billed): ${result.custom_id}`);
break;
}
}
return results;
}client.messages.batches.results()逐行处理JSONL流,不会一次性将所有内容加载到内存。10万条结果一次性放入数组可能高达数百MB,流式处理才是正确选择。
成本计算:实际能省多少
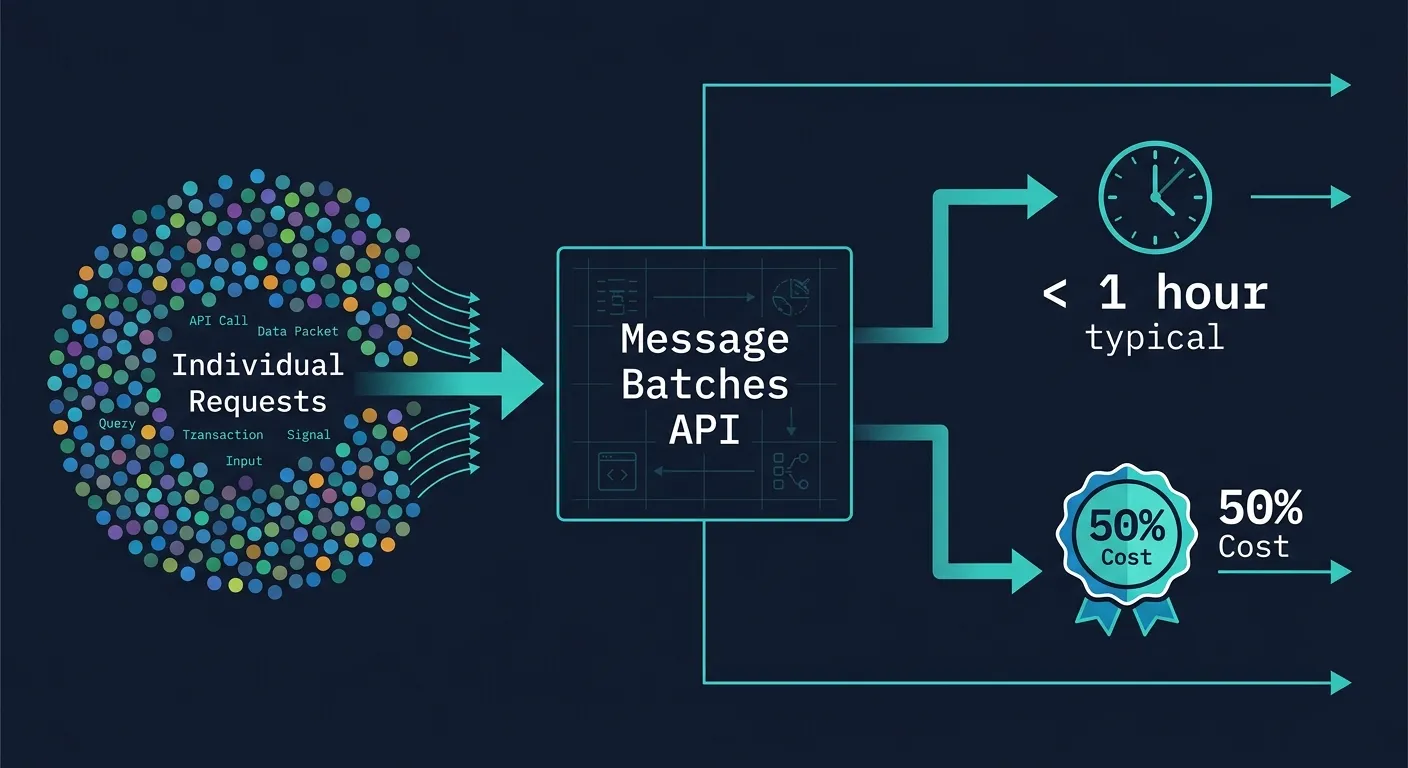
场景:用Claude Haiku 4.5生成10万条商品描述。每请求平均200输入token + 150输出token。
标准API:
输入: 100,000 × 200t = 20 MTok × $1.00 = $20.00
输出: 100,000 × 150t = 15 MTok × $5.00 = $75.00
合计: $95.00
Batches API:
输入: 20 MTok × $0.50 = $10.00
输出: 15 MTok × $2.50 = $37.50
合计: $47.50
节省: $47.50(50%)再叠加Prompt Caching,缓存命中的输入token额外享受90%折扣。对于所有请求共用相同系统提示的场景:
批量折扣(50%)+ 缓存命中(90%):
系统提示token: $1.00/MTok → $0.50 → $0.05/MTok
即标准价格的5% — 节省95%参考Prompt Caching实战指南了解详细配置方式。
需要注意的限制和陷阱
结果顺序不保证 — 始终如此。
// ❌ 错误做法 — 依赖下标
const textsArray = [];
for await (const result of await client.messages.batches.results(batchId)) {
textsArray.push(result.result.message.content[0].text);
}
// textsArray[0]不保证是第一个请求的结果
// ✅ 正确做法 — 基于custom_id的Map
const resultsMap = new Map();
for await (const result of await client.messages.batches.results(batchId)) {
if (result.result.type === "succeeded") {
resultsMap.set(result.custom_id, result.result.message.content[0].text);
}
}提交后无法修改。 提交后若要更改,必须取消并重新提交。建议先用小规模测试批次(10个以下)验证请求结构,再大规模扩展。
队列上限按请求数计算。 Tier 1最多10万个处理中请求,Tier 2为20万,Tier 3为30万,Tier 4为50万。
过期请求不计费,但结果也没有。
24小时超时后变为expired状态,不产生费用,但需重新提交。流量高峰期建议将批次拆分为2,000〜5,000个请求的小包。
结果仅保留29天。 29天后结果文件不可访问。处理完成后立即复制到持久存储(S3、数据库等)。
没有Webhook通知。 这是最大的运维痛点。没有批次完成时的回调,只能通过轮询查询状态。与Temporal或Airflow等工作流编排器集成可以干净地解决这个问题。
高级用法:300K输出Token Beta
2026年3月悄然加入的功能。添加anthropic-beta: output-300k-2026-03-24请求头,单次响应最多可生成300,000个token。仅在Batches API中支持,标准Messages API尚未提供。
const batch = await client.messages.batches.create(
{
requests: [{
custom_id: "long-doc",
params: {
model: "claude-sonnet-4-6",
max_tokens: 300_000,
messages: [{ role: "user", content: "Write a comprehensive technical spec..." }],
},
}],
},
{ headers: { "anthropic-beta": "output-300k-2026-03-24" } }
);注意:300K token的单次生成可能耗时超过1小时。适合技术文档生成、大规模代码脚手架等场景。
何时用、何时不用 — 我的判断
需要实时响应吗?
→ 是: 标准Messages API
→ 否: 批次规模超过100个请求吗?
→ 是: 能接受最多24小时的延迟吗?
→ 是: Batches API
→ 否: 标准API(顺序调用)
→ 否: 标准API(轮询开销得不偿失)不足100个请求的批次效果有限。批处理基础设施是为大规模设计的,小批量下顺序标准调用往往更简单且更快。
我在实践中发现最有效的是混合策略,这与异构LLM舰队成本优化的思路一致:将昂贵模型(Opus)的任务通过批量进行夜间处理,将廉价且快速的模型(Haiku)用于实时交互。兼顾质量和成本。
Webhook缺失和进度仪表板的缺失依然是运维上的摩擦点,但API本身稳定可靠——没有理由再等待了。
总结
Message Batches API不是锦上添花的功能。对于任何有大量LLM处理量的项目,它都是非实时工作负载的默认基础设施选项。API设计简洁,SDK支持完善,50%成本降低立竿见影。
设计阶段需要预先考虑两点:基于custom_id的结果映射,以及Webhook的缺失。这两点处理好了,其余部分文档和SDK都覆盖得很完整。
下一步建议:将Prompt Caching与Batches API组合应用到实际流水线中。对于所有请求共用相同系统提示的分类、摘要、信息提取任务,两者叠加的节省效果往往超出预期。
阅读其他语言版本
- 🇰🇷 한국어
- 🇯🇵 日本語
- 🇺🇸 English
- 🇨🇳 中文(当前页面)
这篇文章有帮助吗?
您的支持能帮助我创作更好的内容。请我喝杯咖啡吧。


