Anthropic SDK vs OpenAI SDK 开发者体验对比 — 类型安全性、错误处理与流式模式实测
在沙箱中同时安装anthropic 0.100.0和openai 2.36.0并深入比较。类型数量408 vs 230、错误类层级、流式实现、工具调用格式、SDK专有功能——全部从代码层面分析的实战比较指南。
pip install anthropic openai — 然后我把两个包放在一起拆解。anthropic 0.100.0,openai 2.36.0。版本号本身就说明了问题:Anthropic还停留在0.x,而OpenAI已经是2.x分支。数字本身没那么重要,重要的是它们所代表的设计哲学差异。
我在临时沙箱中运行了两个SDK,直接检查了类型层级、错误类、流式源代码和工具调用格式。以下是我的发现。
第一印象:版本号透露的信息
anthropic 0.100.0——第100个次要版本,却从未发布1.0。这要么是刻意的API稳定性谨慎,要么是营销选择。openai 2.36.0已经经历了一次major version bump。
两个SDK内部都基于httpx构建,都使用SSE(Server-Sent Events)进行流式传输。查看顶层客户端初始化参数可以发现哲学差异。
# anthropic.Anthropic() 专有参数
client = anthropic.Anthropic(
api_key=None,
auth_token=None,
credentials=None, # 企业级凭证对象
config=None, # 基于配置文件的设置
profile=None, # 命名配置文件
webhook_key=None,
_token_cache=NOT_GIVEN,
)
# openai.OpenAI() 专有参数
client = openai.OpenAI(
api_key=None,
admin_api_key=None,
workload_identity=None, # 基于IAM的认证
organization=None, # 组织ID
project=None, # 项目ID
webhook_secret=None,
websocket_base_url=None, # 用于Realtime API
_enforce_credentials=True,
)Anthropic侧重企业级凭证管理——通过配置文件和命名配置文件管理多账户。OpenAI专注于团队级计费和IAM认证,通过organization、project和workload_identity实现。
共同参数包括max_retries=2、timeout、default_headers、http_client——两者默认值完全相同。
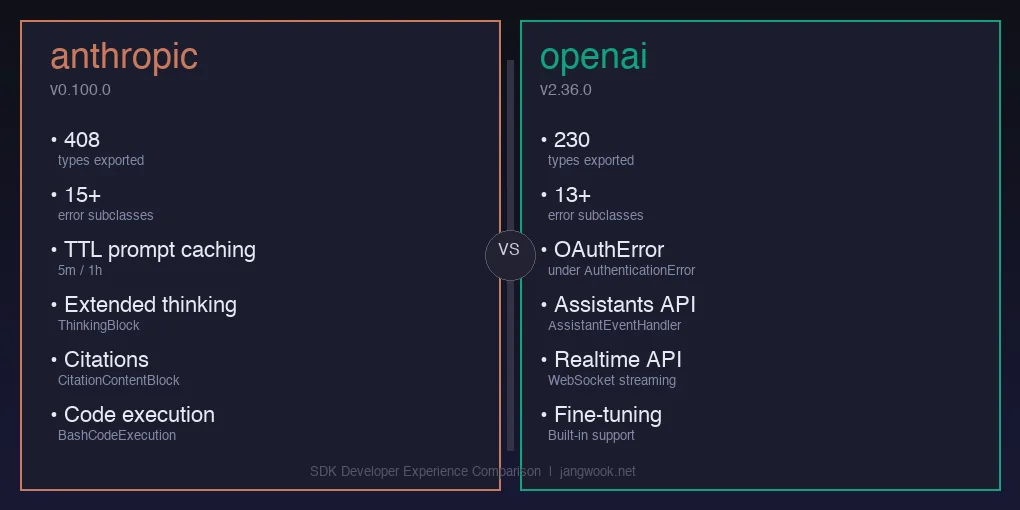
类型系统比较:408 vs 230
这是沙箱中最令人惊讶的数字。
anthropic.types 导出类型数: 408
openai.types 导出类型数: 230差距显著。Claude的API返回更丰富的响应结构——ToolUseBlock、ThinkingBlock、CitationContentBlockLocation、BashCodeExecutionOutputBlock都是有效的响应内容类型,每种都有对应的TypedDict param。OpenAI以ChatCompletion为核心,响应格式更简单统一。
Anthropic专有类型:
| 类型 | 功能 |
|---|---|
ThinkingBlock / ThinkingConfigParam | 扩展思考(Extended Thinking) |
CacheControlEphemeralParam | 提示词缓存(TTL: ‘5m’ / ‘1h’) |
CitationContentBlockLocation | AI响应引用位置追踪 |
BashCodeExecutionOutputBlock | 代码执行工具结果 |
MemoryTool20250818Param | 智能体内存工具 |
ServerToolCaller20260120Param | 服务端工具执行器 |
AnthropicBetaParam | Beta功能头部控制 |
OpenAI专有:
| 功能 | 说明 |
|---|---|
AssistantEventHandler | Assistants API事件流 |
| Realtime API | 基于WebSocket的双向实时流 |
| Fine-tuning模块 | fine_tuning模块内置 |
OAuthError | AuthenticationError的子类型 |
类型更多不代表更好——BashCodeExecutionToolResultBlockParam和BashCodeExecutionToolResultErrorParam作为独立类型提供了精确的自动补全,但也增加了学习成本。OpenAI更简单的结构让入门更快。
工具调用格式:input_schema vs function.parameters
两个SDK最显著的API设计差异在这里。
# Anthropic 工具定义
anthropic_tool = {
"name": "get_weather",
"description": "获取当前天气",
"input_schema": { # JSON Schema直接作为根
"type": "object",
"properties": {
"location": {"type": "string"}
},
"required": ["location"]
}
}
# OpenAI 工具定义
openai_tool = {
"type": "function", # 额外的包装层
"function": {
"name": "get_weather",
"description": "获取当前天气",
"parameters": { # 嵌套在function内部
"type": "object",
"properties": {
"location": {"type": "string"}
},
"required": ["location"]
}
}
}返回工具结果时格式也不同:
# Anthropic: 工具结果作为user消息中的content块
messages.append({
"role": "user",
"content": [
{
"type": "tool_result",
"tool_use_id": "toolu_01A...",
"content": "15°C 晴天"
}
]
})
# OpenAI: 工具结果作为独立的tool角色消息
messages.append({
"role": "tool",
"tool_call_id": "call_abc123",
"content": "15°C 晴天"
})Anthropic将所有内容统一为content块数组,OpenAI使用专用的tool角色。如果你在构建需要同时处理两者的多模型路由,这个格式差异是大部分适配器复杂度的来源。
错误处理架构:共同点与关键差异
我在沙箱中直接打印了两个SDK的错误层级。
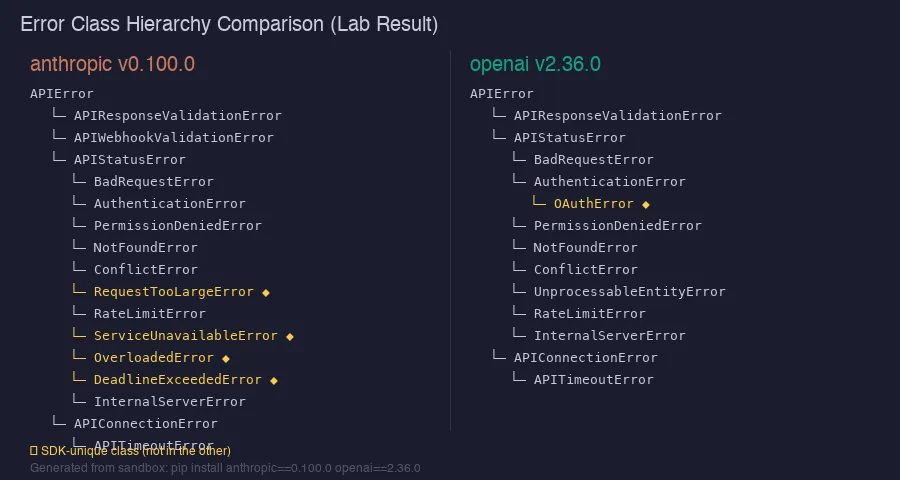
# Anthropic错误层级 (0.100.0)
APIError
├─ APIStatusError
│ ├─ RequestTooLargeError ← Anthropic专有
│ ├─ ServiceUnavailableError ← Anthropic专有
│ ├─ OverloadedError ← Anthropic专有 (HTTP 529)
│ └─ DeadlineExceededError ← Anthropic专有
└─ APIConnectionError
└─ APITimeoutError
# OpenAI错误层级 (2.36.0)
APIError
├─ APIStatusError
│ ├─ AuthenticationError
│ │ └─ OAuthError ← OpenAI专有
│ └─ (其他标准错误)
└─ APIConnectionError
└─ APITimeoutErrorAnthropic专有错误在生产中很重要。OverloadedError是HTTP 529——Claude服务器流量过载。将其与RateLimitError分开捕获可以应用不同的退避策略。DeadlineExceededError与APITimeoutError不同——是处理时间问题,不是连接超时,修复方式不同。
from anthropic import OverloadedError, RateLimitError, DeadlineExceededError
import time
def safe_call(client, **kwargs):
try:
return client.messages.create(**kwargs)
except OverloadedError:
# 服务器过载 — 更长的退避
time.sleep(10)
return client.messages.create(**kwargs)
except RateLimitError as e:
wait = int(e.response.headers.get('retry-after', 60))
time.sleep(wait)
return client.messages.create(**kwargs)
except DeadlineExceededError:
# 处理时间超过 — 分拆为更小的请求
raise两个SDK默认max_retries=2,都会在429和5xx错误时自动重试。
流式模式:核心相同,表面不同
我从源文件中读取了两个流式实现。Stream.__iter__的实现几乎完全相同。
# anthropic._streaming.Stream(实际源码)
class Stream(Generic[_T], metaclass=_SyncStreamMeta):
def __iter__(self) -> Iterator[_T]:
for item in self._iterator:
yield item
def _iter_events(self) -> Iterator[ServerSentEvent]:
yield from self._decoder.iter_bytes(self.response.iter_bytes())
# openai._streaming.Stream(几乎相同)
class Stream(Generic[_T]): # 无元类
def __iter__(self) -> Iterator[_T]:
for item in self._iterator:
yield item
def _iter_events(self) -> Iterator[ServerSentEvent]:
yield from self._decoder.iter_bytes(self.response.iter_bytes())使用接口差异更明显:
# Anthropic流式
with client.messages.stream(
model="claude-opus-4-7",
max_tokens=1024,
messages=[{"role": "user", "content": "你好"}]
) as stream:
for text in stream.text_stream: # 直接提取文本
print(text, end="", flush=True)
# OpenAI流式
with client.chat.completions.stream(
model="gpt-5",
messages=[{"role": "user", "content": "你好"}]
) as stream:
for chunk in stream:
delta = chunk.choices[0].delta
if delta.content: # 需要更深层的路径访问
print(delta.content, end="", flush=True)Anthropic的stream.text_stream对于纯文本输出更简洁。使用Vercel AI SDK构建Claude流式代理的指南在类似模式上构建,适合进一步阅读。
Anthropic专有功能:提示词缓存、扩展思考、引用
提示词缓存
CacheControlEphemeralParam有ttl字段——'5m'或'1h'。这是我没想到的发现。以前只有ephemeral缓存一种选项,现在可以指定过期时间。
client.messages.create(
model="claude-opus-4-7",
system=[
{
"type": "text",
"text": "非常长的系统文档...(数万token)",
"cache_control": {"type": "ephemeral", "ttl": "1h"}
}
],
messages=[{"role": "user", "content": "请总结"}]
)Claude API提示词缓存实战指南涵盖了在生产中应用此功能的四种模式,可降低70%成本。
扩展思考(Extended Thinking)
ThinkingConfigParam和ThinkingBlock让Claude将推理链以结构化输出的形式展示。OpenAI没有等效功能。
response = client.messages.create(
model="claude-opus-4-7",
thinking={"type": "enabled", "budget_tokens": 10000},
messages=[{"role": "user", "content": "复杂数学问题"}]
)
for block in response.content:
if block.type == "thinking":
print("推理过程:", block.thinking) # 结构化,有类型
elif block.type == "text":
print("最终答案:", block.text)引用系统(Citations)
CitationContentBlockLocation追踪Claude从哪个文档片段获取信息。对于需要在回答旁展示来源归属的RAG系统非常有用。
OpenAI专有功能:Assistants API、Realtime、微调
Assistants API — AssistantEventHandler支持结合文件搜索、代码解释器和自定义函数的有状态智能体。Anthropic没有SDK层面的等效抽象。
Realtime API — websocket_base_url参数的存在就是为此。SDK直接支持基于WebSocket的双向流。适合语音智能体和实时交互体验。
微调(Fine-tuning) — OpenAI的fine_tuning模块允许从SDK内直接管理调优任务。Anthropic的微调是独立的企业合同路径,没有公开SDK接口。
选择哪个SDK
| Anthropic SDK 0.100.0 | OpenAI SDK 2.36.0 | |
|---|---|---|
| 导出类型数 | 408 | 230 |
| 错误类数量 | 16个(含529) | 13个 |
| 默认最大重试 | 2 | 2 |
| 流式核心 | httpx + SSE | httpx + SSE |
| 提示词缓存 | ✓ SDK级别 | ✗ |
| 扩展思考 | ✓ | ✗ |
| Realtime API | ✗ | ✓ |
| Assistants API | ✗ | ✓ |
| 微调内置 | ✗ | ✓ |
| 引用系统 | ✓ | ✗ |
| 工具结果格式 | content块 | tool角色消息 |
选择Anthropic SDK的场景: 长上下文文档处理(提示词缓存降成本)、需要推理透明度(扩展思考)、文档QA中的引用追踪、类型安全优先的团队。
选择OpenAI SDK的场景: 语音界面或实时交互(Realtime API)、Assistants API的文件搜索+代码解释器组合、组织/项目级计费分离、管理微调后的自定义模型。
两者都用? 在前面放一个抽象层。PydanticAI在智能体层面处理多提供商路由,让你避免在整个代码库中传播工具格式差异。
这次比较真正揭示的内容
SDK不只是HTTP API的包装器。它是一份设计文档,展示了公司认为开发者会用模型做什么。
Anthropic的408个类型告诉你:我们预期你会关心缓存token、追踪引用、内省推理链。OpenAI的Realtime API和Assistants告诉你:我们预期你会构建实时面向用户的体验和有状态的对话系统。
SDK选择应该跟随模型选择,而不是领先于它。选哪个SDK,先看你选了哪个模型,再看你真正需要哪些功能。
阅读其他语言版本
- 🇰🇷 한국어
- 🇯🇵 日本語
- 🇺🇸 English
- 🇨🇳 中文(当前页面)
这篇文章有帮助吗?
您的支持能帮助我创作更好的内容。请我喝杯咖啡吧。
相关文章
-
Claude API提示缓存实战 — 4种模式将LLM成本降低70%
如果本文介绍的Anthropic SDK专有CacheControlEphemeral类型让你感兴趣,这篇文章详细讲解了如何在生产环境中降低70%成本。

-
用Vercel AI SDK构建Claude流式代理
在了解了流式模式比较之后,如果想用Vercel AI SDK构建真实的Claude流式代理,这个教程是自然的下一步。

-
LLM API定价对比2026 — GPT-5 vs Claude vs Gemini vs DeepSeek实际成本计算
确定了SDK选择标准之后,这篇关于实际计费结构和每token成本比较的文章将帮助你做出最终决定。
