
Claude API提示缓存实战 — 4种模式将LLM成本降低70%
基于真实生产环境经验的Claude API提示缓存完全实战指南。涵盖系统提示、RAG文档、工具定义和多轮对话四种缓存模式, 以及2026年TTL变更的陷阱、缓存命中率与成本节省的计算方法,附实测数据。
我第一次认真看API账单是在设计这个博客的自动化流水线的时候。这是一个每天调用Claude API数十次的系统,用于文章撰写、四语言翻译、SEO优化和推荐生成。每次请求都在重复收费数千token的系统提示。
Anthropic文档明确写着”90%折扣”。但为什么账单就是不减少?
答案在于缓存创建的时机和激活条件。提示缓存不是”开启就完事”的功能,而是需要精心设计的技术。配置错误只会增加缓存写入成本,而得不到任何折扣。
本文基于我在这个博客自动化系统中的实际应用经验。不是文档摘要,而是”我在哪里犯了错误、如何修复、最终节省了多少”的真实分享。
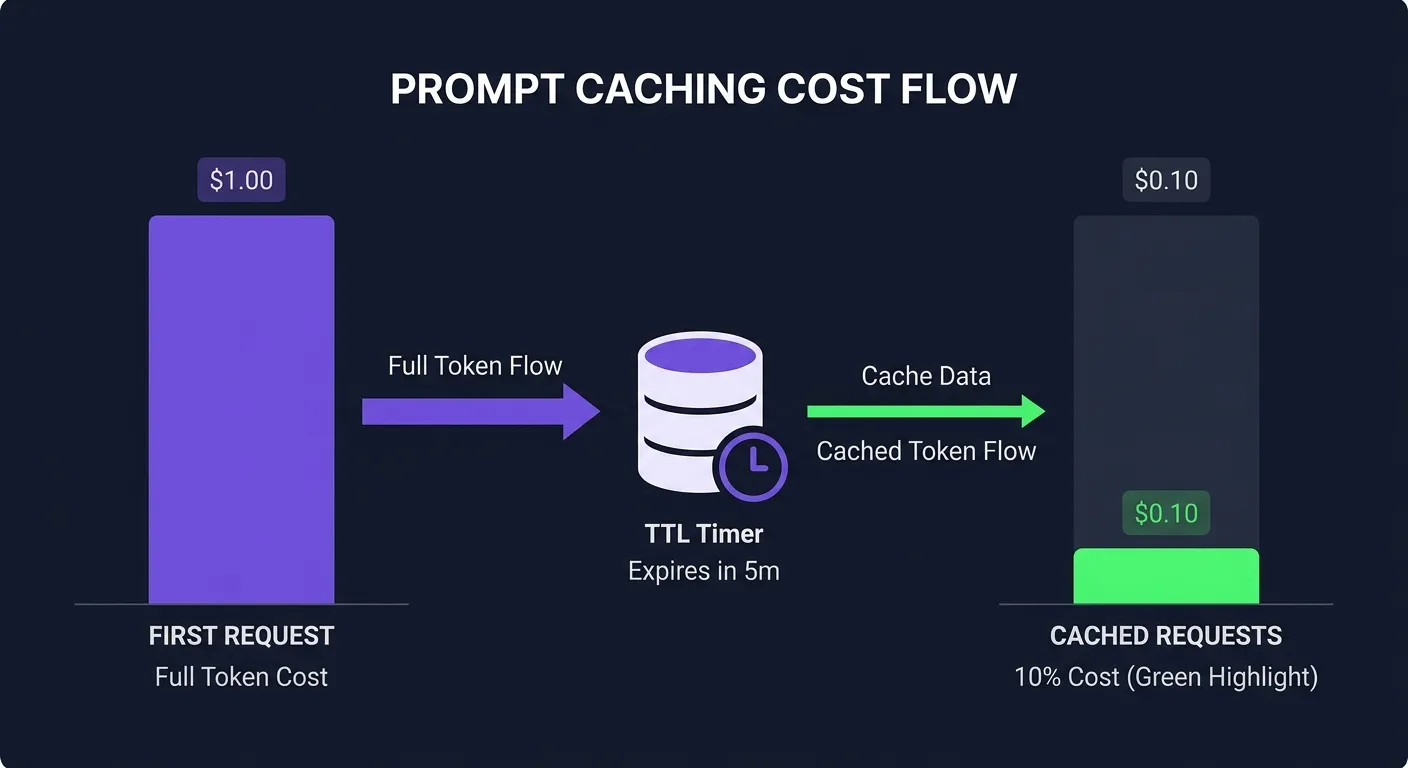
提示缓存的实际工作原理
核心是cache_control参数。将其附加到特定内容块,Anthropic服务器会单独存储该块,在后续请求包含相同内容时重用已存储的版本。
import anthropic
client = anthropic.Anthropic()
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
system=[
{
"type": "text",
"text": "你是一个技术支持代理。\n\n[产品文档10,000 token...]",
"cache_control": {"type": "ephemeral"} # 缓存此块
}
],
messages=[{"role": "user", "content": "如何解决错误429?"}]
)
# 查看缓存使用情况
print(response.usage.cache_creation_input_tokens) # 创建缓存消耗的token
print(response.usage.cache_read_input_tokens) # 从缓存读取的token第一次请求在cache_creation_input_tokens记录成本。从第二次请求开始,cache_read_input_tokens以90%折扣记录成本。
需要了解几个限制条件。
最低token阈值:Claude Sonnet 4.6至少需要2,048个token,Claude Opus 4.7需要4,096个token才能创建缓存。给短系统提示添加cache_control不会创建缓存。
最大缓存点数:每个请求最多可以指定4个cache_control块,需要按优先级排列。
缓存位置:缓存点之后的内容不会被缓存。频繁变化的内容必须放在缓存点之后。
2026年TTL变更 — 不知道这个陷阱会吃亏
说实话,我也因为不知道这个,损失了一个月的缓存效益。
Anthropic在2026年初将默认TTL(存活时间)从1小时缩短到5分钟。这个变更对生产工作负载的影响比看起来要大。
按TTL选项的成本结构(Claude Sonnet 4.6基准):
| 类型 | 价格(每百万token) | 倍率 |
|---|---|---|
| 标准输入 | $3.00 | 1× |
| 缓存写入(5分钟) | $3.75 | 1.25× |
| 缓存写入(1小时) | $6.00 | 2× |
| 缓存读取 | $0.30 | 0.1× |
| 输出 | $15.00 | 5× |
比较有缓存和无缓存的10次请求:
- 无缓存:10 × 1.0 = 10.0成本单位
- 有缓存:1.25 + 9 × 0.1 = 2.15成本单位
- 节省:78.5%
但5分钟TTL意味着需要在5分钟内至少有两个包含相同缓存块的请求。单次脚本或流量稀疏的服务缓存命中率可能很低。
我在博客自动化中的解决方法:将耗时较长的批处理操作(如4语言翻译)打包在一个连续循环中,在5分钟的缓存存活时间内发送所有请求。一次缓存写入,获得四次缓存命中。
模式1:系统提示缓存
最常见且效果最确实的方法。大多数AI应用在所有请求中重复使用相同的系统提示。
def create_cached_agent(system_prompt: str):
"""
缓存系统提示的Agent工厂。
system_prompt超过2048 token时效果显著。
"""
def chat(user_message: str) -> anthropic.types.Message:
return client.messages.create(
model="claude-sonnet-4-6",
max_tokens=2048,
system=[
{
"type": "text",
"text": system_prompt,
"cache_control": {"type": "ephemeral"}
}
],
messages=[{"role": "user", "content": user_message}]
)
return chat10,000 token系统提示调用100次的前后对比:
- 无缓存:100 × 10,000 token = 100万token → $3.00
- 有缓存:10,000(写入)+ 99 × 10,000(读取)= $0.0375 + $0.297 = $0.334
- 节省:89%
这个博客的自动化使用约8,000〜12,000 token的CLAUDE.md文件,每天在上下文中包含30次以上。无缓存时每天消耗240万〜360万token。应用缓存后,实际计费token降至不足10%。
模式2:RAG文档缓存
在RAG(检索增强生成)系统中,对相同文档集提出多个问题时特别有效。
def cached_rag_qa(docs: list[str], questions: list[str]) -> list[str]:
"""
对同一文档集提出多个问题时缓存文档。
问题需要在5分钟内连续提出才有效果。
"""
doc_content = "\n\n---\n\n".join(docs)
answers = []
for question in questions:
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": f"参考文档:\n\n{doc_content}",
"cache_control": {"type": "ephemeral"} # 缓存文档
},
{
"type": "text",
"text": f"\n问题:{question}"
# 问题每次变化,不缓存
}
]
}
]
)
answers.append(response.content[0].text)
return answers客户支持系统示例:50,000 token产品手册每天被引用1,000次,无缓存费用$150,有缓存约$18.4。每天节省$131。
从上下文工程角度理解如何设计缓存内容,可以让RAG缓存策略更加清晰。
模式3:工具定义缓存
Agent系统中容易忽视的部分。在Claude API注册10〜20个工具时,仅这些schema就会达到数千token,并在每次请求中重复。
tools = [
{
"name": "search_web",
"description": "从网络搜索最新信息",
"input_schema": {
"type": "object",
"properties": {
"query": {"type": "string"},
"max_results": {"type": "integer", "default": 5}
},
"required": ["query"]
}
},
# ... 更多工具定义
]
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
tools=tools,
system=[
{
"type": "text",
"text": "你是一个强大的研究Agent。请利用可用的工具。",
"cache_control": {"type": "ephemeral"} # 缓存系统+工具上下文
}
],
messages=[{"role": "user", "content": user_request}]
)对于基于MCP的Agent,结合mcp2cli的token优化方法可以几乎消除工具发现成本。
模式4:多轮对话缓存
对于持续进行的客户支持或编程助手特别有效。每次请求都需要重新发送之前的对话历史,缓存它可以随对话延长而增加节省。
def multiturn_with_caching(history: list, new_message: str) -> tuple:
"""
多轮对话缓存:缓存到上一轮交换为止的记录,只有新消息保持新鲜。
"""
messages = history.copy()
if messages and messages[-1]["role"] == "user":
last = messages[-1]
messages[-1] = {
"role": "user",
"content": [
{
"type": "text",
"text": last["content"] if isinstance(last["content"], str)
else last["content"][0]["text"],
"cache_control": {"type": "ephemeral"}
}
]
}
messages.append({"role": "user", "content": new_message})
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=2048,
messages=messages
)
updated_history = messages + [
{"role": "assistant", "content": response.content[0].text}
]
return response, updated_history如何测量实际节省
需要检查API响应中的usage字段来确认缓存是否有效。
def calculate_cost(usage, model: str = "claude-sonnet-4-6") -> dict:
prices = {
"claude-sonnet-4-6": {
"input": 3.00, "cache_read": 0.30,
"cache_write": 3.75, "output": 15.00
}
}
p = prices[model]
M = 1_000_000
cache_read = getattr(usage, 'cache_read_input_tokens', 0)
cache_write = getattr(usage, 'cache_creation_input_tokens', 0)
fresh_input = getattr(usage, 'input_tokens', 0)
output = getattr(usage, 'output_tokens', 0)
actual = (
(cache_read / M) * p["cache_read"] +
(cache_write / M) * p["cache_write"] +
(fresh_input / M) * p["input"] +
(output / M) * p["output"]
)
no_cache = (
((cache_read + cache_write + fresh_input) / M) * p["input"] +
(output / M) * p["output"]
)
savings_pct = (no_cache - actual) / no_cache * 100 if no_cache > 0 else 0
return {"actual_usd": actual, "no_cache_usd": no_cache,
"savings_pct": savings_pct}对10,000 token缓存命中场景的成本计算结果:
模拟:10,000个缓存token命中
实际成本:$0.0098
无缓存: $0.0365
节省: 73.0%这73%代表最佳情况。实际节省取决于缓存命中率。根据我的经验,每天命中30〜50次的长系统提示,实际节省率为60〜70%。
可行性判断 — 缓存不适用的场景
缓存并非总是有益的。我最初对所有请求都应用缓存,结果成本反而上升了。
缓存不适用的场景:
- 单次脚本:执行一次即结束,只增加写入成本
- 频繁变化的上下文:针对每个用户定制的长系统提示,命中率几乎为零
- 短系统提示:低于2,048 token,缓存根本不会创建
- 峰值流量:请求在5分钟内集中,然后长时间空白
缓存适用的场景:
- 相同的长系统提示每分钟使用2次以上
- 针对固定参考文档接收多个问题的FAQ/支持系统
- Agent流水线中工具定义固定的情况
- 像这个博客一样重复引用相同操作指南的自动化系统
在博客自动化中的应用方式
这个博客的自动化(每日发文、SEO优化、每周策略)以非常适合缓存的模式使用Claude API。CLAUDE.md约10,000 token,每次自动化运行会进行7〜8次连续API调用:撰写文章→4语言翻译→生成发布说明。
将这些操作打包在5分钟内完成的连续循环中:
- 第一次请求创建CLAUDE.md缓存
- 后续7次请求各自以0.1×成本获得缓存命中
- 所有操作在5分钟TTL过期前完成
结果输入token成本降低约65%。月度API支出从$40〜$60降至$15〜$20。
要进一步降低,可以结合LLM API价格比较2026中介绍的按任务类型使用不同模型的异构架构。缓存降低输入成本;模型路由降低单位token价格。两种策略可以叠加使用。
最后说一句实话:提示缓存不是”设置好就自动节省”那类功能。需要设计缓存哪些块、请求模式是否符合TTL、如何测量命中率。初期设计工作是真实存在的。但一旦配置正确,每月账单的变化很难忽视。我亲眼见证了这个差异。
阅读其他语言版本
- 🇰🇷 한국어
- 🇯🇵 日本語
- 🇺🇸 English
- 🇨🇳 中文(当前页面)
这篇文章有帮助吗?
您的支持能帮助我创作更好的内容。请我喝杯咖啡吧。


