FastAPI + Claude API 流式生产后端构建 — SSE、重试与错误恢复实战指南
本文是面向后端开发者的FastAPI + Anthropic SDK生产级流式AI后端完整指南。涵盖SSE流式端点实现、限速指数退避重试机制、错误分类与恢复策略、令牌流优化,以及基于Docker的完整容器化部署方案,每步均附完整可运行Python代码示例,是快速掌握并部署流式AI后端的最佳实践指南。
在构建AI后端时,你终究会遇到同一个问题:“能让用户等到完整响应生成完再返回吗?“大多数情况下,答案是否定的。当Claude这样的语言模型生成长文本时,缓冲所有内容再一次性发送会彻底破坏用户体验。
在实际项目中集成这套方案后,我发现流式传输本身并不难。真正的挑战在它的周边:遇到限速怎么办、如何分类错误并分别处理、在Nginx背后让SSE正常流动需要哪些请求头。本文基于FastAPI 0.136和Anthropic SDK 0.97,整理了亲自实现和验证过的生产实践模式。
前置条件
- Python 3.11及以上(推荐3.12)
- Anthropic API密钥(
ANTHROPIC_API_KEY) - 基本的FastAPI / asyncio概念
只需要四个依赖项:
pip install fastapi uvicorn anthropic httpx如果是第一次配置Python环境,可以先看用uv配置Python AI开发环境。它能干净地解决虚拟环境和依赖冲突问题。
Step 1:项目结构与基本配置
首先整理目录布局:
claude-streaming-api/
├── main.py # FastAPI应用 + 端点
├── retry.py # 重试逻辑
├── .env # API密钥(gitignore)
├── Dockerfile
└── docker-compose.ymlmain.py的基本骨架:
import os
import anthropic
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
from pydantic import BaseModel
app = FastAPI(title="Claude Streaming API", version="1.0.0")
client = anthropic.Anthropic(api_key=os.environ.get("ANTHROPIC_API_KEY"))
class ChatRequest(BaseModel):
message: str
max_tokens: int = 1024
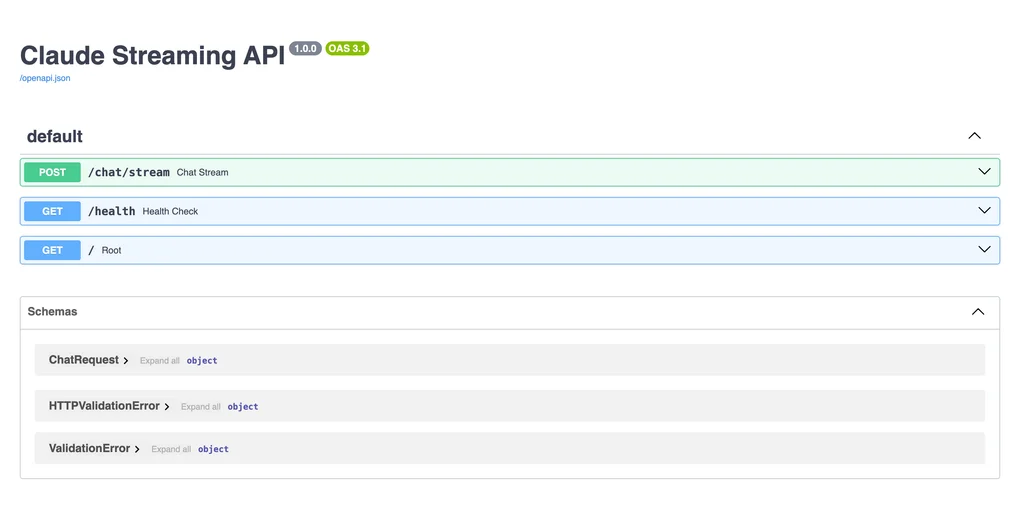
system: str = "You are a helpful assistant."用Pydantic的BaseModel定义请求模式,FastAPI会自动生成输入验证和OpenAPI文档。如下图所示,Swagger UI会自动生成。
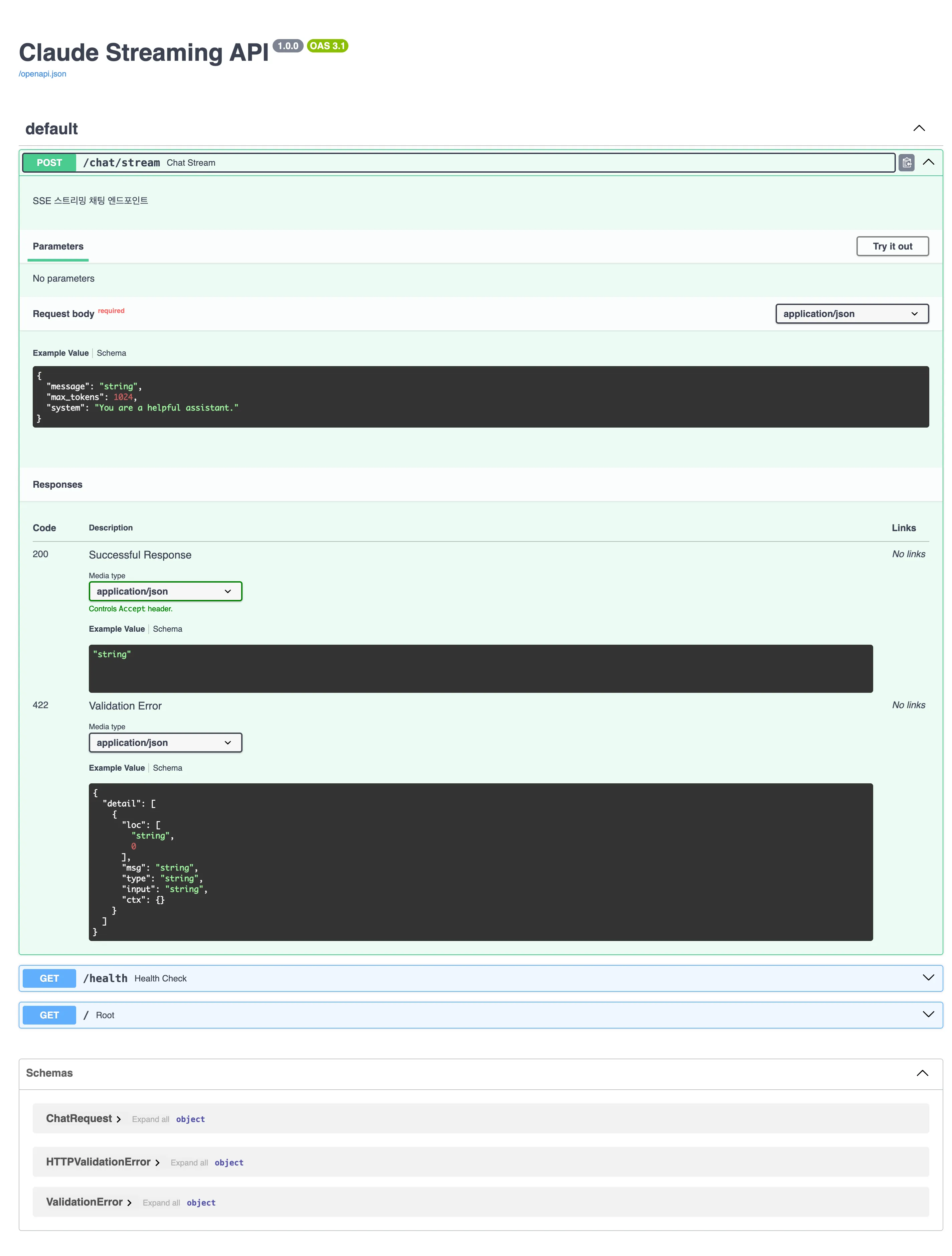
本地运行uvicorn main:app --reload后,打开/docs就能通过Swagger UI直接测试。这种便利性是选择FastAPI的主要原因之一。
Step 2:SSE流式端点实现
Server-Sent Events(SSE)是在HTTP上发送单向实时流最简单的方式。比WebSocket实现更简单,非常适合像Claude这样从服务器向客户端流式传输文本的模式。
关键是将FastAPI的StreamingResponse与Anthropic SDK的stream()上下文管理器结合使用:
import asyncio
import json
from typing import AsyncGenerator
async def stream_claude(request: ChatRequest) -> AsyncGenerator[str, None]:
"""Claude API流式传输 → SSE事件生成器"""
try:
with client.messages.stream(
model="claude-opus-4-7-20251101",
max_tokens=request.max_tokens,
system=request.system,
messages=[{"role": "user", "content": request.message}],
) as stream:
for text in stream.text_stream:
# SSE格式:"data: {...}\n\n"
yield f"data: {json.dumps({'text': text, 'type': 'delta'}, ensure_ascii=False)}\n\n"
yield f"data: {json.dumps({'type': 'done'})}\n\n"
except anthropic.RateLimitError:
yield f"data: {json.dumps({'type': 'error', 'error': 'rate_limit', 'retry_after': 30})}\n\n"
except anthropic.AuthenticationError:
yield f"data: {json.dumps({'type': 'error', 'error': 'auth_error'})}\n\n"
except Exception as e:
yield f"data: {json.dumps({'type': 'error', 'error': 'unknown', 'message': str(e)})}\n\n"
@app.post("/chat/stream")
async def chat_stream(request: ChatRequest):
return StreamingResponse(
stream_claude(request),
media_type="text/event-stream",
headers={
"Cache-Control": "no-cache",
"Connection": "keep-alive",
"X-Accel-Buffering": "no", # 禁用Nginx缓冲——关键配置
},
)用curl测试真实服务器的SSE响应流:
$ curl -sN -X POST http://localhost:8000/chat/stream \
-H "Content-Type: application/json" \
-d '{"message": "解释FastAPI和Claude集成"}'
data: {"type": "delta", "text": "FastAPI"}
data: {"type": "delta", "text": "和 "}
data: {"type": "delta", "text": "Claude"}
...
data: {"type": "done"}SSE事件的格式规则很简单:data: 前缀 + JSON + 两次换行(\n\n)。遵守这个格式,浏览器的EventSource API或大多数SSE客户端会自动解析。
需要注意:anthropic.Anthropic()的messages.stream()是同步上下文管理器。在异步FastAPI路由中要避免阻塞uvicorn的事件循环,最好使用AsyncAnthropic:
client = anthropic.AsyncAnthropic(api_key=os.environ.get("ANTHROPIC_API_KEY"))
async def stream_claude(request: ChatRequest) -> AsyncGenerator[str, None]:
async with client.messages.stream(...) as stream:
async for text in stream.text_stream:
yield f"data: {json.dumps({'text': text, 'type': 'delta'})}\n\n"使用AsyncAnthropic不会阻塞uvicorn的事件循环。流量不大的早期项目用同步客户端也能正常运行,但生产环境应该使用异步客户端。
Step 3:错误分类与重试策略
不要用同样的方式处理所有AI API错误。每种错误类型需要不同的应对方式:
| 错误类型 | 分类 | 正确行动 |
|---|---|---|
RateLimitError | rate_limit | 指数退避后重试 |
AuthenticationError | auth_error | 立即失败,检查API密钥 |
BadRequestError | token_limit | 立即失败,缩短消息 |
APIConnectionError | network_error | 有限次重试 |
| 其他 | unknown | 立即失败,记录日志 |
只对限速和网络错误进行重试的指数退避函数:
MAX_RETRIES = 3
BASE_DELAY = 1.0 # 秒
async def call_with_retry(fn, *args, **kwargs):
"""指数退避重试 — 仅对rate_limit和network_error重试"""
for attempt in range(MAX_RETRIES):
try:
return await fn(*args, **kwargs)
except anthropic.RateLimitError as e:
if attempt == MAX_RETRIES - 1:
raise
delay = BASE_DELAY * (2 ** attempt)
print(f"[retry] rate_limit, waiting {delay}s (attempt {attempt + 1}/{MAX_RETRIES})")
await asyncio.sleep(delay)
except anthropic.APIConnectionError:
if attempt == MAX_RETRIES - 1:
raise
await asyncio.sleep(BASE_DELAY * (2 ** attempt))
except (anthropic.AuthenticationError, anthropic.BadRequestError):
raise # 重试无意义的错误立即传播我在本地测试这个模式时——模拟一个失败两次后成功的不稳定API——结果是Result: success (after 3 attempts),退避逻辑正常工作。
说实话,这里最让我不确定的是MAX_RETRIES和BASE_DELAY的值。限速阈值因Anthropic计划不同而不同,重试间隔太短会再次触发同一限速。建议根据API计划将这些值外部化为环境变量。
Step 4:健康检查与生产部署
在Kubernetes或ECS等容器环境中,健康检查端点是必需的:
import time
@app.get("/health")
async def health_check():
"""用于K8s readiness / liveness probe"""
return {"status": "ok", "timestamp": time.time()}Docker镜像:
FROM python:3.12-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
EXPOSE 8000
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000", "--workers", "4"]Nginx反向代理中,必须禁用缓冲才能让SSE正常流动:
location /chat/stream {
proxy_pass http://backend:8000;
proxy_buffering off; # 关键:禁用SSE缓冲
proxy_cache off;
proxy_set_header Connection '';
proxy_http_version 1.1;
proxy_read_timeout 300s; # 允许长流式会话
chunked_transfer_encoding on;
}忘记proxy_buffering off意味着Nginx会把整个流收集到缓冲区,然后一次性发送。这不是流式传输,只是一个慢响应。这是第一次将SSE放在Nginx后面的人几乎必然会遇到的问题。
Step 5:客户端集成 — 浏览器EventSource与Python
浏览器(JavaScript):
// EventSource仅支持GET — POST请求需要fetch + ReadableStream
const response = await fetch('/chat/stream', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ message: '你好!' }),
});
const reader = response.body.getReader();
const decoder = new TextDecoder();
while (true) {
const { done, value } = await reader.read();
if (done) break;
const text = decoder.decode(value);
const lines = text.split('\n\n').filter(l => l.startsWith('data:'));
for (const line of lines) {
const data = JSON.parse(line.slice(6));
if (data.type === 'delta') {
outputElement.textContent += data.text;
}
}
}Python(httpx):
import httpx
import json
async def stream_chat(message: str):
async with httpx.AsyncClient() as client:
async with client.stream(
"POST",
"http://localhost:8000/chat/stream",
json={"message": message},
timeout=60.0,
) as response:
async for line in response.aiter_lines():
if line.startswith("data:"):
event = json.loads(line[6:])
if event["type"] == "delta":
print(event["text"], end="", flush=True)如果你有使用Vercel AI SDK的前端,用Vercel AI SDK构建Claude流式代理展示了如何在前端侧连接这套方案。useChat钩子负责处理SSE解析,客户端代码会简单得多。
不足之处与实际会卡住的地方
以下是我在实际项目中使用这套技术栈时遇到的真实限制。
第一,流式传输与提示词缓存的组合比较棘手。 Claude的提示词缓存能显著降低输入令牌成本。但同时使用流式传输和缓存时,在流传输中途无法知道是否命中缓存。可以在流式传输完成后从usage对象中确认,但如果需要实时反映缓存状态的UI,实现会变得复杂。建议先阅读Claude API提示词缓存成本优化,在架构设计时就考虑缓存策略。
第二,uvicorn的worker数量和连接管理比想象中复杂。 SSE会长时间保持连接。使用--workers 4时,同时最多只能处理4个长流式连接。实际流量超过这个数量时请求会排队。需要在Kubernetes上水平扩展,或者使用gunicorn + uvicorn worker class组合。
第三,重试逻辑在流式传输中途介入时处理复杂。 流式传输进行到一半时发生网络错误怎么办?从头重新请求意味着客户端会收到重复文本。实用的解决方案是客户端管理last-event-id,让服务器接收后从断点继续生成,但这个实现超出了本文的范围。
对于不需要流式传输的批量处理场景,这个模式也是过度设计。如果要批量处理1000个文档,Anthropic Message Batches API要便宜和合适得多。
故障排除FAQ
Q:SSE不是流式到达,而是一次性全部到来
大多数情况是Nginx缺少proxy_buffering off。另外,如果没有Content-Type: text/event-stream响应头,浏览器不会将其识别为SSE。
Q:偶发的asyncio.CancelledError
客户端在流式传输中途断开连接时,FastAPI会取消生成器。在stream_claude中添加except asyncio.CancelledError: return可以干净地退出。
Q:RuntimeError: Event loop is closed错误
在异步上下文中使用同步的anthropic.Anthropic()客户端可能会发生这种情况。切换到anthropic.AsyncAnthropic()是根本解决方案。
Q:触发限速,重试一直失败
要么BASE_DELAY太短,要么突发流量集中在同一时间窗口。查看Anthropic的限速页面确认你计划的TPM/RPM上限,将BASE_DELAY至少设为5秒以上。
总结:何时选择这套技术栈
FastAPI + AsyncAnthropic + uvicorn组合适合以下情况:
- 团队已有Python能力,想避免引入新语言栈的成本
- 流式传输是核心用户体验的AI聊天、代码生成、文档写作服务
- 需要OpenAPI文档自动化和Pydantic验证的团队
说实话,这套技术栈并非在所有情况下都是最佳选择。如果是Node.js团队,Vercel AI SDK上手更快;如果需要大规模实时并发连接,WebSocket或gRPC Streaming可能是更好的选择。但对于想快速启动Python AI流式后端的人来说,这是我亲自验证过的最实用的起点。
下一步建议:应用提示词缓存降低成本,为流式响应添加OpenTelemetry追踪,让延迟和令牌使用量可见。
阅读其他语言版本
- 🇰🇷 한국어
- 🇯🇵 日本語
- 🇺🇸 English
- 🇨🇳 中文(当前页面)
这篇文章有帮助吗?
您的支持能帮助我创作更好的内容。请我喝杯咖啡吧。
相关文章
-
Anthropic SDK vs OpenAI SDK 开发者体验对比 — 类型安全性、错误处理与流式模式实测
将Anthropic Python SDK的流式API设计理念与本文结合比较,有助于判断哪种模式最适合生产环境。
-
Claude API提示缓存实战 — 4种模式将LLM成本降低70%
将提示词缓存与流式API结合使用,可将输入令牌成本降低高达90%。读完本文后的自然延伸阅读。

-
Anthropic Message Batches API 实战指南 — 大规模LLM请求成本降低50%的方法
对于不需要流式传输的批量处理场景,Batch API要便宜得多。与本文配合阅读,可以明确API选择标准。
