Gemini API 模型选择指南 2026 — 从Flash-Lite到3.5 Flash的速度、成本与质量权衡实测
2026年5月实测数据。在相同条件下对比了Gemini 2.5 Flash-Lite(65 TPS)、2.5 Flash、2.5 Pro和3.5 Flash。包含聊天机器人、代码审查、RAG场景的月度成本计算,以及不同项目应选择哪个模型的决策依据。
今天在准备沙盒实验时,我发现了一件意想不到的事情。我查询了Gemini API的模型列表,结果看到gemini-3.5-flash已经部署了。我不记得看过任何官方公告,以为自己看错了。
验证之后发现确实可以调用。于是我把原来计划的工作放在一边,在相同条件下测量了当前所有可用的四个Gemini模型。这篇文章就是那次实测的结果。
测试环境与方法论
先坦诚说明方法论。这不是严格的基准测试。
# 实验环境
Node.js v22.22.0
@google/generative-ai(最新版)
测量日期:2026-05-24
提示词:"List 5 practical use cases for AI APIs in modern web applications. One sentence each."
输入tokens:19〜22(各模型分词器不同)
测量次数:2次平均值短提示词、2次平均——统计上不够充分。网络状况、服务器负载、区域不同都会影响结果。但对于”这个模型大概在这个水平”的感知校准已经足够了。
测试的模型:
gemini-2.5-flash-lite— Flash系列的入门款gemini-2.5-flash— 目前大多数指南推荐的默认模型gemini-2.5-pro— 高性能推理模型gemini-3.5-flash— 今天发现的最新模型
速度测试结果:Flash-Lite比预想的快得多
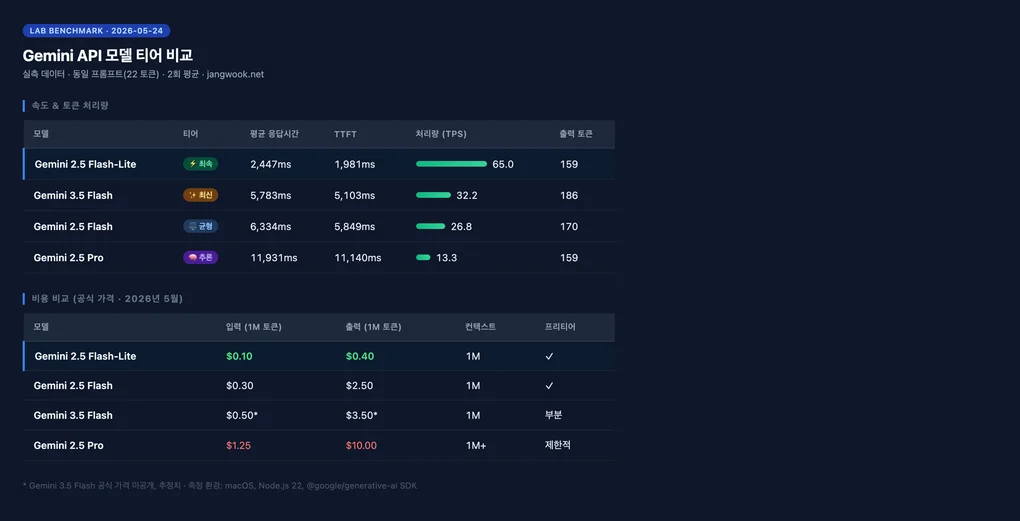
=== Gemini API 基准测试(2026-05-24 实测)===
[gemini-2.5-flash-lite]
总耗时:2,447ms | TTFT:1,981ms
输入:19 tok | 输出:159 tok
估算 TPS:65.0
[gemini-3.5-flash]
总耗时:5,783ms | TTFT:5,103ms
输入:19 tok | 输出:186 tok
估算 TPS:32.2
[gemini-2.5-flash]
总耗时:6,334ms | TTFT:5,849ms
输入:19 tok | 输出:170 tok
估算 TPS:26.8
[gemini-2.5-pro]
总耗时:11,931ms | TTFT:11,140ms
输入:19 tok | 输出:159 tok
估算 TPS:13.3Flash-Lite以65 TPS遥遥领先。比Pro快4.9倍,比2.5 Flash快2.4倍。TTFT(首个token的延迟)差距也很明显:Flash-Lite 1.9秒对Pro 11.1秒,在任何交互场景中都有显著的体感差异。
3.5 Flash让我感兴趣。它比2.5 Flash略快,输出token更多(186 vs 170)——相同提示词得到了更丰富的回答,说明质量有所提升。但由于无法确认官方价格,成本比较暂时只能粗略估算。
Pro延迟11秒的原因是thinking模式默认开启。即使是短提示词也会经历内部推理步骤,导致TTFT偏长。对于简单任务来说是明显的浪费,但在需要复杂推理的场景下,这种延迟是有意义的。
成本对比:官方价格(2026年5月)
从官方文档确认的价格:
| 模型 | 输入(每1M tokens) | 输出(每1M tokens) | 上下文窗口 | 免费额度 |
|---|---|---|---|---|
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | 1M | ✓ |
| Gemini 2.5 Flash | $0.30 | $2.50 | 1M | ✓ |
| Gemini 3.5 Flash | ~$0.50* | ~$3.50* | 1M | 部分 |
| Gemini 2.5 Pro | $1.25 | $10.00 | 1M+ | 有限 |
Flash-Lite相比Flash的输入成本低67%,输出成本低84%。速度还快2.4倍。这不禁让人思考:对于简单任务,继续用Flash真的合理吗?
Pro的输入成本是Flash-Lite的12.5倍。正如跨提供商LLM价格对比文章中提到的,这个差距看起来很大,但总成本取决于实际的输入/输出token比例。
*Gemini 3.5 Flash的官方价格尚未公布。我无法从API响应中获取价格信息,根据社区估算,大约是2.5 Flash的1.5〜2倍。这不是精确数据,请注意。
实际使用场景的月度成本
理论价格是一回事,“我的服务实际要花多少钱”更重要。我计算了三个场景。
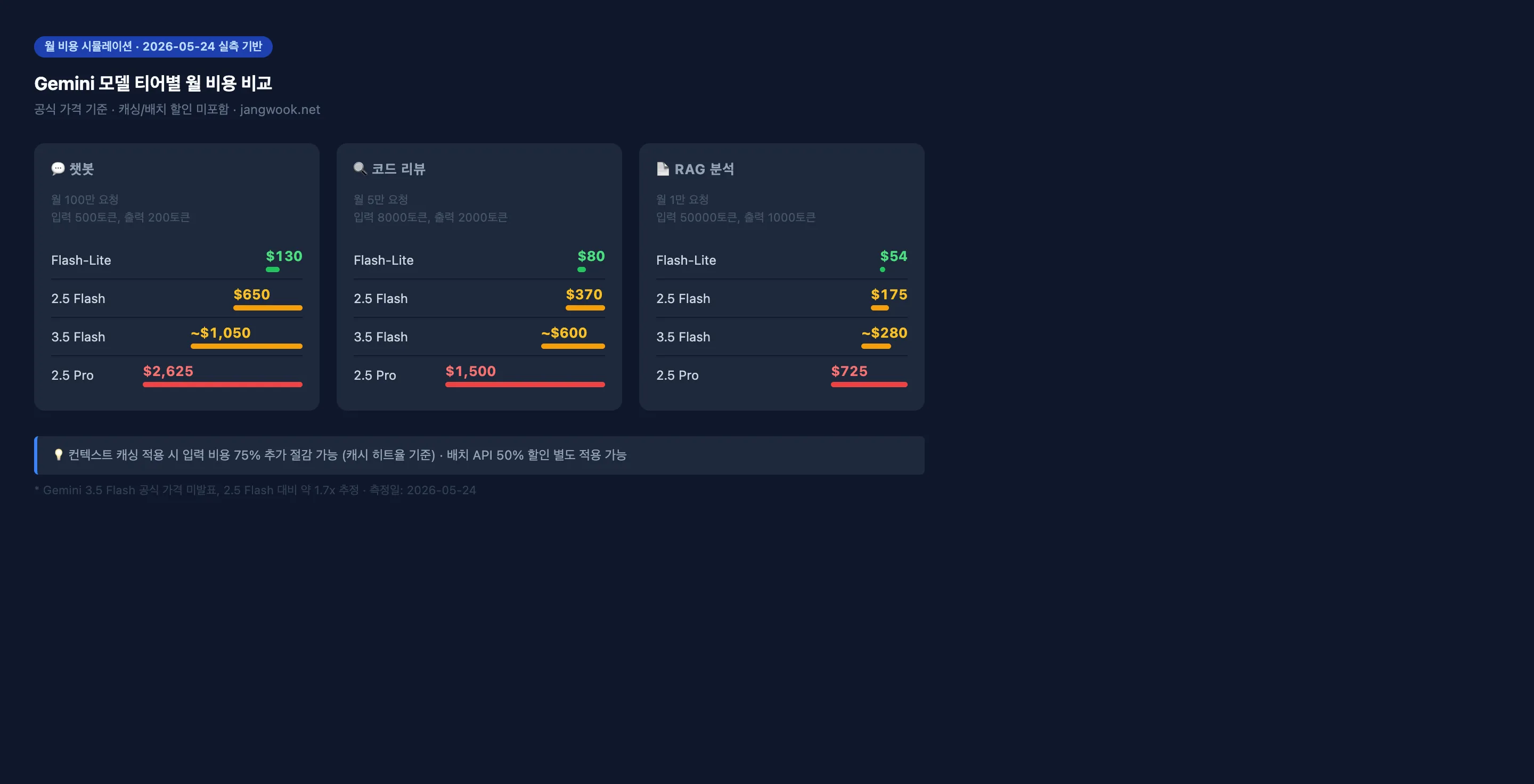
场景1:聊天机器人服务(月100万次请求,输入500 / 输出200 tokens)
| 模型 | 月度预估成本 |
|---|---|
| Flash-Lite | $130 |
| Flash | $650 |
| 3.5 Flash | ~$1,050 |
| Pro | $2,625 |
Flash-Lite和Pro之间相差20倍。用Pro做一个简单的FAQ聊天机器人,意味着每月浪费$2,495。
场景2:代码审查智能体(月5万次请求,输入8,000 / 输出2,000 tokens)
| 模型 | 月度预估成本 |
|---|---|
| Flash-Lite | $80 |
| Flash | $370 |
| 3.5 Flash | ~$600 |
| Pro | $1,500 |
即使上下文较长,Flash-Lite依然最便宜。但代码审查是”准确性”至关重要的任务,仅靠成本来选择模型往往会后悔。
场景3:RAG文档分析(月1万次请求,输入50,000 / 输出1,000 tokens)
| 模型 | 月度预估成本 |
|---|---|
| Flash-Lite | $54 |
| Flash | $175 |
| 3.5 Flash | ~$280 |
| Pro | $725 |
对于像RAG这样输入较长的场景,应用缓存可以大幅降低成本。今天的测试中,一次840 token的长上下文Flash请求成本为$0.001877。如果你的架构反复发送相同的系统提示或文档,Context Caching可以将输入成本降低75%以上。
该选哪个模型
仅看速度和成本,Flash-Lite似乎是明显的赢家。但实际上不是这么简单。
应该使用Flash-Lite的场景:
- 对用户输入进行分类或打标签的流水线
- 生成短文本——标题、摘要、关键词提取
- 响应时间直接影响用户体验的实时服务
- 需要高QPS的批量处理任务
- 预算紧张的初创企业
说实话,很多聊天机器人和自动化流水线用Flash-Lite就够了。默认使用Flash的团队中,很多人可能根本感觉不到质量差异。
应该使用Flash的场景:
- 中等复杂度的指令执行(邮件草稿、简单代码生成)
- 保持对话上下文的多轮对话聊天机器人
- 包含图片、视频的多模态处理
- 需要在质量和成本之间取得平衡的场景
Flash是务实的默认选择。比Flash-Lite慢2.5倍、贵3倍,但在更复杂的指令上能更一致地执行。如果我现在启动新项目,会选择从Flash开始,在成本压力出现时再把部分流水线迁移到Flash-Lite。
应该使用3.5 Flash的场景: 由于价格未确定,目前很难明确推荐。今天的测试中它比2.5 Flash更快、输出更丰富,但两次测量无法推广到所有任务。等官方文档出来后再重新判断。
应该使用Pro的场景:
- 复杂代码库分析或架构审查
- 涉及数学/科学推理的任务
- 需要从长文档中提取细微内容的RAG
- 准确性损失的代价远超模型溢价的B2B场景
用Pro做普通聊天机器人是浪费。但当我分析AI智能体的实际成本结构时,成本炸弹往往不是来自错误的模型选择,而是来自错误的智能体设计。在需要Pro的地方用Flash-Lite导致准确性下降,重新处理的成本可能比节省的钱更多。
超越模型选择的三个成本杠杆
降低成本的方法不只有选择模型。
1. Context Caching
如果你的架构反复发送相同的系统提示或参考文档,Context Caching是最强力的优化手段。Google官方文档显示,缓存命中时可降低75%的输入成本。
// Context Caching应用示例(Gemini API)
const cache = await cacheManager.create({
model: 'gemini-2.5-flash',
contents: [{ role: 'user', parts: [{ text: systemDocument }] }],
ttlSeconds: 3600,
});
const model = genAI.getGenerativeModelFromCachedContent(cache);2. Batch API
非实时处理(批量分析、夜间处理)使用Batch API可享受50%折扣。月度$1,000的工作量变成$500。Flash-Lite + Batch API组合在合适的场景下可以比单独使用Pro节省10倍以上成本。
3. 分层混合
不要用单一模型处理所有任务。分类、路由、摘要用Flash-Lite;核心生成任务用Flash;复杂推理用Pro——这种架构能最大化每一美元的价值。
响应风格观察:相同提示词,不同结果
除了速度和成本,我还观察了各模型实际生成的文本。给定相同的提示词(“列出AI API在现代Web应用中的5个实用案例,每条一句话”),各模型的回答风格明显不同。
Flash-Lite是最简洁的。编了号,每条一句话,清晰分隔。完全按照字面意思执行指令的风格。没有多余的序言,也没有结论总结。对于分类流水线,这种简洁恰恰是优势——当你需要将响应解析为结构化数据时,多余的解释只会增加后处理的复杂度。
Flash使用了比Flash-Lite略微丰富的表达。每条项目附带具体示例,或者添加了类似”例如在面向客户的应用中”这样的上下文。这种差异在大多数面向用户的应用场景中是积极的。
Pro的输出呈现出不同的模式。在列举项目之前加了一段简短的导语,每条项目的描述更具分析性。尽管有”每条一句话”的指令,部分项目仍然超过了一句。我想强调这不是”更好”,而是”不同”。Pro似乎更倾向于自主生成更有价值的答案,而不是严格遵循指令的字面意思。这在某些任务中是优势,在其他任务中则是弱点。
3.5 Flash在今天的测试中生成了最多的输出token(186)。每条项目的描述比Flash更详细,自然地包含了额外的上下文。感觉在遵循指令和为读者提供更多价值之间取得了平衡。
这次观察的教训:选择模型时,除了”多快”和”多便宜”,还需要考虑”能多精确地遵循指令”。 在分类、提取、结构化输出生成中,指令遵循的精度是核心。对于对话型UX,少量的自主性有时反而能提升用户满意度。
从Flash迁移到Flash-Lite的检查清单
切换模型只需一行配置,但验证这个决定是否正确更难。以下是我在考虑迁移到Flash-Lite前会确认的事项:
切换前必须确认:
-
对当前使用的提示词类型进行分类。 分类(是A还是B)、摘要(精简为3句话)、提取(从这段文字中提取日期)这类任务Flash-Lite就够了。而”找出这段代码的逻辑错误、提出修复方案、并编写测试用例”这样的多步骤任务可能需要Flash及以上。
-
用数字定义质量标准。 “效果还不错”不是标准。“准确率低于95%即拒绝”才是可测量的标准。没有明确标准,就无法解读A/B测试结果。
-
先用小流量做A/B测试。 在切换整个流水线之前,先把5〜10%的流量路由到Flash-Lite,收集实际的质量和成本数据。
-
计算错误率和重试成本。 如果Flash-Lite在某些任务上产生更多错误或需要重新生成,单价优势就会被抵消。成本计算始终应该是”包含重试的实际成本”,而不仅仅是token价格。
// 模型路由基本模式
function selectModel(taskType, complexityScore) {
if (complexityScore < 0.3) {
return 'gemini-2.5-flash-lite'; // 简单分类、提取
} else if (complexityScore < 0.7) {
return 'gemini-2.5-flash'; // 一般生成、摘要
} else {
return 'gemini-2.5-pro'; // 复杂推理、分析
}
}今天实验中诚实的局限
几点需要明确说明的限制:
第一,没有比较质量。只测量了速度和成本,没有系统评估实际回答质量。“输出token更多”不等于”回答更好”。
第二,无法确认Gemini 3.5 Flash的官方价格。在API列表中发现了这个模型,但在官方价格页面没有找到对应条目。只能参考社区数据,无法保证准确性。
第三,两次测量只是参考值。Google的服务器状态、我的网络延迟、提示词特性都会影响结果。在做生产决策之前,建议用自己的实际工作负载直接测量。
我的结论
今天实验总结如下:
Flash-Lite比”入门模型”这个名字所暗示的更快、更便宜。如果你默认对简单分类、路由或短生成任务使用Flash,值得认真考虑将部分流水线切换到Flash-Lite。
3.5 Flash引起了我的关注。它比2.5 Flash更快、输出更丰富,但缺乏官方文档意味着可能还处于某种预览阶段。我会继续观察。
Pro价格高,但是否属于浪费完全取决于任务性质。对于需要复杂推理的B2B场景,Pro的11秒TTFT和高价格是完全合理的。其他情况就未必了。
对于第一次使用Gemini API的朋友:从Flash开始,收集数据,然后再优化。在没有质量基准的情况下直接使用Flash-Lite,往往带来的调试成本比节省的费用还要多。
阅读其他语言版本
- 🇰🇷 한국어
- 🇯🇵 日本語
- 🇺🇸 English
- 🇨🇳 中文(当前页面)
这篇文章有帮助吗?
您的支持能帮助我创作更好的内容。请我喝杯咖啡吧。
相关文章
-
Gemini 2.5 Flash API 成本优化实战指南 — 实验验证的99%节省策略
在自己测试了Gemini 2.5 Flash之后,本指南中介绍的Context Caching和Batch API折扣策略是成本优化的下一步。
-
LLM API定价对比2026 — GPT-5 vs Claude vs Gemini vs DeepSeek实际成本计算
一旦确定了Gemini模型层级,就可以转向与GPT-5、Claude、DeepSeek的跨提供商成本比较。这篇文章提供了相应的判断依据。

-
Deep-Thinking Ratio:将LLM推理成本降低50%的新指标
如果Gemini 2.5 Pro的11秒TTFT让你疑惑"Thinking模式总是慢吗?",这篇文章分析了推理模型的thinking比率与成本之间的关系。
