Langfuse v3 自托管完整指南 — 在本地基础设施上直接构建LLM追踪
从Langfuse v3 Docker Compose安装到Python SDK 4.x代码检测和RAG管道追踪,全程实战指南。在保持数据主权的同时,在自有基础设施上部署LLM可观测性。
将LLM智能体部署到生产环境后,总会遇到这样的时刻:你正在Langfuse仪表板中追踪”为什么会给出那个响应?“,然后看到了云服务账单。当月追踪量超过10万条后,Langfuse Cloud的Pro套餐开始变成真实的成本负担。于是我用Docker Compose搭建了自托管环境。这篇文章是我在这个过程中学到的东西。
Langfuse真正解决的问题
运营AI智能体后,很快就会意识到传统APM工具有多无用。Datadog和New Relic在HTTP延迟和错误率方面表现不错,但无法告诉你”这个RAG管道中检索步骤降低了多少整体响应质量”。提示词版本变更时响应质量如何变化,同样无法追踪。
我在AI智能体可观测性实践指南中将Langfuse与Braintrust和LangSmith进行了比较,自托管能力和开源许可是Langfuse最显著的差异化优势。这篇文章越过比较阶段,直接讲实际部署方法。
Langfuse提供的功能:
- 追踪瀑布图:每个智能体步骤耗时多少,瓶颈在哪里
- Token用量和成本追踪:GPT-4o、Claude Sonnet等各模型的累计费用
- 提示词版本管理:在代码库外管理提示词并进行A/B测试
- 数据集和评估:使用LLM作为评判者的自动质量评分流水线
- 用户会话追踪:跨轮次跟踪同一用户的对话流程
说实话,这些功能不需要从第一天就全部用上。我每天实际使用的只有追踪瀑布图和成本追踪两项。其余的可以等团队规模扩大或需要自动评估时再添加。
Langfuse v3架构 — 为什么变得如此复杂
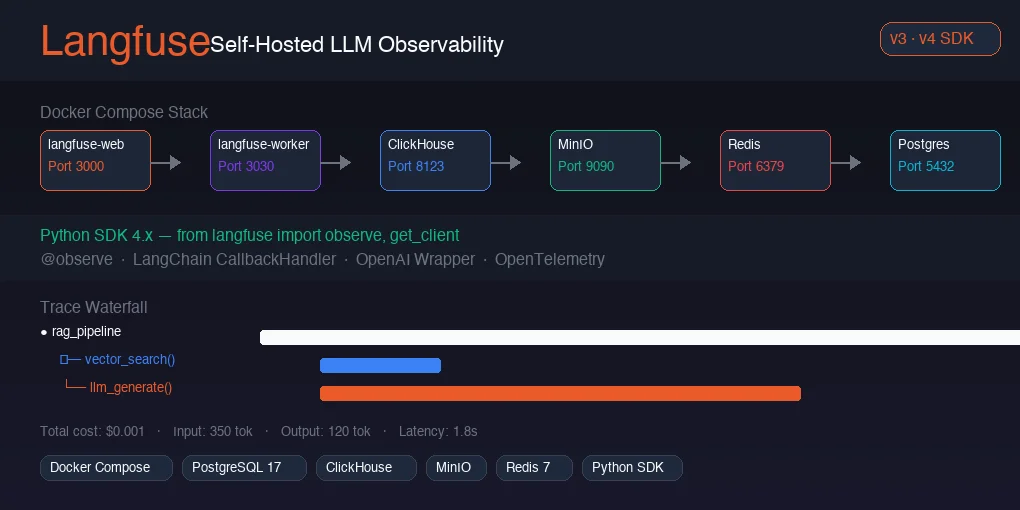
Langfuse v2只需要PostgreSQL。docker-compose.yml只有10行,5分钟就能启动。v3变了。下载官方docker-compose.yml,你会发现里面定义了6个服务。
服务组成(基于docker-compose.yml):
├── langfuse-web (3000端口 — UI + API)
├── langfuse-worker (3030端口 — 后台任务处理)
├── ClickHouse (8123, 9000 — OLAP分析数据库)
├── MinIO (9090 — S3兼容对象存储)
├── Redis 7 (6379 — 队列 + 缓存)
└── PostgreSQL 17 (5432 — 关系型数据库)为什么增加了这么多复杂度?v3的核心变化是将追踪存储从PostgreSQL分离到ClickHouse。在PostgreSQL上聚合数十万条追踪数据来计算”过去30天平均延迟趋势”需要数秒。ClickHouse是针对此类聚合查询优化的列式OLAP数据库,相同查询只需毫秒级完成。
我对这种架构复杂度有不满。对小团队或个人项目来说,管理6个容器是一种负担。Langfuse团队也意识到了这一点,持续讨论轻量级部署选项,但截至2026年5月,官方仅支持这种全栈配置。
Docker Compose安装步骤
前提条件:
- Docker Engine 20.x或更高版本
- Docker Compose v2(Compose V1已停止支持)
- 最低4GB RAM(推荐8GB)
- 20GB以上可用磁盘空间
第一步:下载docker-compose.yml
mkdir langfuse-local && cd langfuse-local
curl -sL https://raw.githubusercontent.com/langfuse/langfuse/main/docker-compose.yml \
-o docker-compose.yml第二步:配置环境变量
找到docker-compose.yml中的# CHANGEME注释并替换为实际值。至少需要修改以下三项:
cat > .env << 'EOF'
NEXTAUTH_SECRET=$(openssl rand -base64 32)
SALT=$(openssl rand -base64 16)
ENCRYPTION_KEY=$(openssl rand -hex 32)
DATABASE_URL=postgresql://langfuse:yourpassword@postgres:5432/langfuse
MINIO_ROOT_USER=langfuse
MINIO_ROOT_PASSWORD=yourminiopassword
CLICKHOUSE_PASSWORD=yourclickhousepassword
EOF第三步:启动服务
docker-compose up -d
# 检查状态(需要1〜2分钟达到healthy状态)
docker-compose ps成功启动后,访问http://localhost:3000会显示注册界面。第一个注册的账户成为管理员。
首次启动常见问题
ClickHouse初始化耗时最长。PostgreSQL和Redis通常在30秒内达到healthy状态,但ClickHouse首次启动时因为schema迁移可能需要超过1分钟。由于langfuse-worker等待depends_on: clickhouse: condition: service_healthy,这期间worker可能看起来在反复重启。不用担心。
如果3000端口已被占用,在docker-compose.yml中将langfuse-web的ports改为"3001:3000"即可。
使用Python SDK 4.x创建第一个追踪
Langfuse SDK最近从v3升级到v4。v4最大的变化是移除了langfuse.decorators模块。
pip install langfuse # 当前版本:4.5.1# v3 SDK(旧版本 — 已不再工作)
from langfuse.decorators import observe, langfuse_context # ❌
# v4 SDK(当前版本)
from langfuse import observe, get_client # ✓推荐使用环境变量方式配置:
export LANGFUSE_PUBLIC_KEY="pk-lf-your-public-key"
export LANGFUSE_SECRET_KEY="sk-lf-your-secret-key"
export LANGFUSE_HOST="http://localhost:3000" # 自托管基本追踪从单个@observe装饰器开始:
from langfuse import observe, get_client
@observe()
def call_llm(prompt: str) -> str:
response = "LLM响应文本"
client = get_client()
client.update_current_observation(
model="claude-sonnet-4-5",
usage_details={"input": 150, "output": 80},
cost_details={"input": 0.000225, "output": 0.00032}
)
return response
result = call_llm("今天天气怎么样?")追踪实际RAG管道
就像我在用PydanticAI构建类型安全智能体中探索的那样,为实际智能体代码添加Langfuse,能立即看清哪些步骤在产生费用。
from langfuse import observe, get_client
@observe(as_type="retriever")
def vector_search(query: str, top_k: int = 5) -> list[dict]:
"""向量数据库检索"""
client = get_client()
client.update_current_observation(
input={"query": query, "top_k": top_k},
metadata={"index": "blog_posts"}
)
results = [
{"id": f"doc_{i}", "content": f"文档 {i}", "score": 0.9 - i * 0.1}
for i in range(top_k)
]
client.update_current_observation(output=results)
return results
@observe(as_type="generation")
def llm_generate(query: str, context: list[dict]) -> str:
"""LLM响应生成"""
client = get_client()
client.update_current_observation(
model="claude-sonnet-4-5",
usage_details={"input": 450, "output": 150},
cost_details={"input": 0.000675, "output": 0.0006}
)
return "生成的响应"
@observe(name="rag_pipeline")
def run_rag(user_query: str) -> str:
"""整体RAG管道"""
docs = vector_search(user_query, top_k=3)
answer = llm_generate(user_query, docs)
return answer执行此代码后,Langfuse UI中会显示如下追踪瀑布图:
rag_pipeline ████████████████████ 1.8s
└─ vector_search() [retriever] ██ 0.2s
└─ llm_generate() [generation] █████████████████ 1.6s
model: claude-sonnet-4-5
input: 450 / output: 150 tokens
cost: $0.001275as_type参数是关键。标记为generation会自动聚合token用量并启用按模型的成本分析。retriever将检索延迟分离为独立指标。
v4 SDK主要变更和注意事项
SDK v4升级时我踩了坑。一个在约50处使用from langfuse.decorators import observe的项目,安装v4后全部出现ModuleNotFoundError。
| 项目 | v3(旧版) | v4(当前版) |
|---|---|---|
| observe导入 | from langfuse.decorators import observe | from langfuse import observe |
| 上下文更新 | langfuse_context.update_current_observation | get_client().update_current_observation |
| OTel集成 | 需要单独配置 | 原生支持 |
v4最重要的架构变化是原生OpenTelemetry集成。之前SDK使用自定义HTTP客户端发送数据,v4实现了OTel SpanExporter接口,与OpenTelemetry生态系统完全兼容。LangfuseOtelSpanAttributes等新类的出现正是为此。
迁移主要通过查找替换完成:
find . -name "*.py" -exec sed -i \
's/from langfuse.decorators import observe, langfuse_context/from langfuse import observe, get_client/g' {} +提示词版本管理与数据集
Langfuse超越简单追踪工具的地方有两个:提示词版本管理和基于数据集的评估。
from langfuse import get_client
client = get_client()
prompt = client.get_prompt("blog-title-generator", version=3)
compiled = prompt.compile(
topic="LLM可观测性",
tone="实用",
audience="开发者"
)这样管理提示词,“为什么用版本2提示词那天响应质量下降了?“这个问题在Langfuse UI中就能立即得到答案。
如果你已经直接构建了MCP服务器,为其LLM调用添加Langfuse追踪是自然的下一步。MCP服务器往往有较长的工具调用链,追踪瀑布图在这里价值尤为突出。
自托管的局限性与实际判断
有些情况下我不推荐自托管。直接说明:
适合自托管的情况:
- 追踪数据包含敏感个人信息(医疗、金融)
- 月追踪量超过10万条,Cloud费用构成实际负担
- 已经在运营基于Kubernetes的基础设施
直接使用Cloud更合适的情况:
- 团队3人以下,没有基础设施管理资源
- 月追踪量不超过5万条(Langfuse Cloud免费层范围内)
- 不想自己管理备份、扩容和更新
说实话,ClickHouse消耗2GB以上内存对我运营的规模来说还是感觉浪费。
故障排除常见问题
Q. docker-compose up后langfuse-web持续重启
ClickHouse或Redis初始化尚未完成。等待1〜2分钟通常可以解决。如果不行,通过docker-compose logs langfuse-web查看错误信息。
Q. 追踪数据没有出现在Langfuse UI中
最常见的原因是SDK的异步flush完成前进程就退出了。在脚本结尾明确调用get_client().flush(),或在异步环境中调用await get_client().async_flush()。
总结 — 何时引入LLM可观测性
根据我的经验,LLM追踪不是在第一次部署前引入的,而是收到第一个令人困惑的响应之后才引入的。那个时刻到来时,如果Langfuse已经在运行,5分钟内就能找到根本原因。没有的话,就要花几个小时翻日志文件。
Langfuse 4.5.1 SDK从pip install langfuse和单个@observe装饰器开始。自托管栈变重了,但ClickHouse带来的聚合查询性能完全弥补了这种复杂度。
建议在Langfuse Cloud免费层达到上限之前,提前准备好Docker Compose配置文件。
阅读其他语言版本
- 🇰🇷 한국어
- 🇯🇵 日本語
- 🇺🇸 English
- 🇨🇳 中文(当前页面)
这篇文章有帮助吗?
您的支持能帮助我创作更好的内容。请我喝杯咖啡吧。


