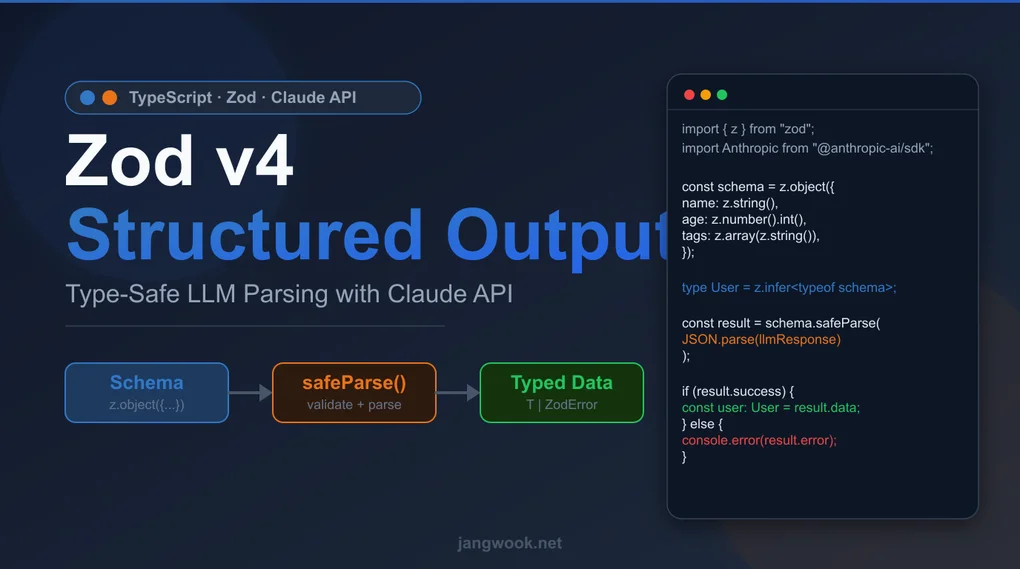
TypeScript Zod v4 + Claude API 構造化出力完全ガイド — 型安全なLLM応答パース実践
Zod v4のsafeParse()と変更されたスキーマAPIでClaude API応答を型安全にパースするパターンを実際に検証した。v3比の性能数値、z.string().check()新API、ネストスキーマ設計戦略をClaude API統合コードとともに整理する。
Claude APIから受け取ったJSON文字列をJSON.parse()だけで信用して使っていたら、ランタイムエラーに遭遇したことがある。content[0].textをパースして取り出したオブジェクトが期待したフィールドを持っているという保証はない。LLMはプロンプトを無視したり、フィールド名をわずかに変えたり、型を混在させたりする。Zod v4はその問題を型レベルで防いでくれる。
この記事では、Zod 4.4.3と@anthropic-ai/sdk 0.100.1を基準に、Claude API応答を安全にパースする実践パターンをまとめる。実際に100,000回パースのベンチマークを回してみて、v3から変わったAPIが実際にどう違うのかをコードで確認した。
Zod v4がv3と実際に何が違うのか
公式発表のヘッドライン数値は印象的だ。文字列パース14倍、配列7倍、オブジェクト6.5倍高速。バンドルサイズは57%削減。TypeScript型インスタンス化は最大100倍削減。ただ、数値が良さそうだからといってすぐにマイグレーションを決める必要はない。
実際に使ってみて、体感できる変化は3つある。
第一に、エラーメッセージがより明確になった。 v3でrequired_errorでカスタムメッセージを入れていたパターンが、単一のerrorパラメーターに統合された。デフォルトのエラーメッセージフォーマットも変わった。v3では"String must contain at least 1 character(s)"だったのが、v4では"Too small: expected string to have >=1 characters"に変わる。コードベースでエラーメッセージ文字列を直接テストしているなら壊れる。
第二に、数値バリデーションがより厳格になった。 Infinityと-Infinityはv3ではz.number()を通過していた。v4ではsuccess: falseを返す。Number.MAX_SAFE_INTEGERを超える整数もz.number().int()で拒否される。外部APIやLLM応答から極端な値が入ってくる可能性があるコードは注意が必要だ。
第三に、API設計が整理された。 z.string().email()の代わりにz.email()を使うのがv4スタイルだ。.and()の代わりにz.intersection(A, B)。そしてインラインカスタム検証のための.check()メソッドが新たに追加された。
正直に言えば、v4がv3より常に速いわけではない。コミュニティのベンチマークでは、複雑にネストされたスキーマの一部シナリオではv3の方が速いケースが出ていた。ヘッドライン数値は一般的なパターン基準で、すべてのコードに当てはまるわけではない。
v4で公式に削除されたとされているがまだ存在するAPI
.and()メソッドは公式ドキュメントでは削除されたと記載されている。しかし4.4.3で実際にテストすると、まだ存在して正常に動作する。マイグレーションガイドが実際のリリースより先行してしまっているようだ。required_errorパラメーターも同様だ。技術的には動作するが、メッセージフォーマットが変わっている。ハード削除ではなく、静かなdeprecated処理に見える。
マイグレーション計画を立てる際は、ドキュメントより実際のバージョンで確認するのが安全だ。
インストールと基本設定
npm install zod@^4.4.3
npm install @anthropic-ai/sdk@^0.100.1TypeScriptプロジェクトならtsconfig.jsonにstrict: trueが有効になっていないと、Zodの型推論が正しく動作しない。
{
"compilerOptions": {
"strict": true,
"target": "ES2022",
"module": "ESNext",
"moduleResolution": "bundler"
}
}インストール直後に基本動作を確認する最小コードだ。
import { z } from 'zod';
const UserSchema = z.object({
name: z.string().min(1),
email: z.email(), // v4スタイル: z.string().email()の代わり
age: z.number().int().min(0).max(150),
role: z.enum(['admin', 'user', 'viewer'])
});
type User = z.infer<typeof UserSchema>;
const result = UserSchema.safeParse({
name: 'Jangwook',
email: 'kim.jangwook@example.com',
age: 30,
role: 'admin'
});
if (result.success) {
console.log(result.data.name); // 型: string
} else {
console.log(result.error.issues);
}実行結果は想定通りだ。
success: true
parsed data: {"name":"Jangwook","email":"kim.jangwook@example.com","age":30,"role":"admin"}@zod/miniは別パッケージ
公式発表に@zod/miniが含まれていた。約1.9KB gzip基準のツリーシェイカブルな配布版だ。フロントエンドのバンドルサイズが重要な場合に有用だ。ただし、APIのインターフェースがメインのzodパッケージとは異なる。この記事ではClaude APIとのサーバーサイド統合を扱うため、メインパッケージ基準で説明する。
LLM応答に合わせたスキーマ設計
LLM応答をパースするスキーマは、一般的なフォームデータのスキーマとは設計の方向性が違う。核心的な違いは防御的なオプショナルフィールド処理だ。
LLMはリクエストしたフィールドをすべて返さない場合がある。応答品質が一定でなく、プロンプト変更で構造が変わることもある。この現実を反映したスキーマ設計が必要だ。
基本的なLLM応答スキーマ
import { z } from 'zod';
// ブログ投稿分析応答スキーマ
const BlogAnalysisSchema = z.object({
title: z.string().min(1).max(200),
summary: z.string().min(10),
tags: z.array(z.string()).min(1).max(10),
sentiment: z.enum(['positive', 'neutral', 'negative']),
readingTimeMinutes: z.number().int().min(1).max(60),
// LLMが常に返すとは限らないオプショナルフィールド
seoScore: z.number().min(0).max(1).optional(),
suggestedImprovements: z.array(z.string()).optional()
});
type BlogAnalysis = z.infer<typeof BlogAnalysisSchema>;メタデータを含むネストスキーマ
Claude APIが実際に構造化データを返す際、応答自体に関するメタ情報が必要なケースがある。信頼度スコアやモデル情報を一緒に受け取りたい場合だ。
const LLMResponseSchema = z.object({
// 実際のコンテンツ
content: z.object({
title: z.string().min(1),
tags: z.array(z.string()),
body: z.string()
}),
// 応答メタデータ(オプショナル)
metadata: z.object({
model: z.string(),
confidence: z.number().min(0).max(1),
processingTimeMs: z.number().int().positive()
}).optional()
});実際のテストで、.optional()が付いたネストオブジェクトは想定通りに動作した。metadataフィールドがなくてもパースが成功する。
LLM response (with metadata) success: true
title: Zod v4: A Deep Dive into Schema Validation
confidence: 0.92
LLM response (no metadata) success: truez.string().check()でLLM応答フォーマットを検証
v4で新たに追加された.check() APIが役立つケースがある。LLMが特定のプレフィックスやフォーマットを守る必要がある応答を返す場合だ。
// LLMが必ず"RESULT:"プレフィックスを付ける必要がある応答
const LLMResultSchema = z.string().check((ctx) => {
if (!ctx.value.startsWith('RESULT:')) {
ctx.issues.push({
code: 'custom',
message: 'LLM応答は"RESULT:"で始まらなければなりません',
input: ctx.value
});
}
});
const valid = LLMResultSchema.safeParse('RESULT: 分析完了');
const invalid = LLMResultSchema.safeParse('分析完了');
console.log(valid.success); // true
console.log(invalid.success); // false注意点がある。.check()コールバック内でctx.issues.push()に渡すissueオブジェクトの形に対するTypeScriptの自動補完が不足している。code: 'custom'とmessage、inputフィールドは必須なのに、エディターでのヒントがうまく出ない。初めて使う人がミスしやすい部分だ。
Claude API応答をZodでパースする
Pattern 1: プロンプトでJSON応答をリクエストしてパース
最もシンプルなパターンだ。システムプロンプトでJSON形式を指定し、応答テキストをJSON.parse()してからZodで検証する。
import Anthropic from '@anthropic-ai/sdk';
import { z } from 'zod';
const client = new Anthropic();
// 欲しい応答構造を定義
const ArticleAnalysisSchema = z.object({
title: z.string().min(1),
mainTopics: z.array(z.string()).min(1).max(5),
difficulty: z.enum(['beginner', 'intermediate', 'advanced']),
estimatedReadTime: z.number().int().positive(),
hasCodeExamples: z.boolean()
});
type ArticleAnalysis = z.infer<typeof ArticleAnalysisSchema>;
async function analyzeArticle(content: string): Promise<ArticleAnalysis> {
const response = await client.messages.create({
model: 'claude-sonnet-4-6',
max_tokens: 1024,
system: `あなたは技術ドキュメントアナライザーです。
必ず以下のJSON形式のみで応答してください:
{
"title": "ドキュメントタイトル",
"mainTopics": ["トピック1", "トピック2"],
"difficulty": "beginner" | "intermediate" | "advanced",
"estimatedReadTime": 数値(分),
"hasCodeExamples": true | false
}
JSON以外のテキストは含めないでください。`,
messages: [
{ role: 'user', content: `次のドキュメントを分析してください:\n\n${content}` }
]
});
// 応答テキストを抽出
const textContent = response.content.find(block => block.type === 'text');
if (!textContent || textContent.type !== 'text') {
throw new Error('テキスト応答がありません');
}
// JSONパース
let parsed: unknown;
try {
parsed = JSON.parse(textContent.text);
} catch {
throw new Error(`JSONパース失敗: ${textContent.text}`);
}
// Zod検証
const result = ArticleAnalysisSchema.safeParse(parsed);
if (!result.success) {
const errorSummary = result.error.issues
.map(issue => `${issue.path.join('.')}: ${issue.message}`)
.join(', ');
throw new Error(`スキーマ検証失敗: ${errorSummary}`);
}
return result.data;
}このパターンの弱点は、LLMがJSONブロックの前後にマークダウンのコードフェンスや説明テキストを付けるとJSON.parse()が失敗することだ。実用的な処理が必要になる。
function extractJsonFromResponse(text: string): string {
// ```json ... ``` ブロックからJSONを抽出
const codeBlockMatch = text.match(/```(?:json)?\s*([\s\S]*?)\s*```/);
if (codeBlockMatch) {
return codeBlockMatch[1];
}
// 中括弧で始まり終わる部分を抽出
const jsonMatch = text.match(/\{[\s\S]*\}/);
if (jsonMatch) {
return jsonMatch[0];
}
return text;
}Pattern 2: Tool Useで構造化出力を強制する
Claude Agent SDK Tool Use完全ガイドで扱っているように、tool_useを活用するとJSON形式を強制できる。LLMがツールを「呼び出す」形で構造化データを返すようにするパターンだ。
import Anthropic from '@anthropic-ai/sdk';
import { z } from 'zod';
const client = new Anthropic();
// ZodスキーマをTool定義の入力スキーマとして変換
const ArticleMetadataSchema = z.object({
title: z.string().describe('ドキュメントの核心的なタイトル'),
tags: z.array(z.string()).describe('関連タグ一覧(最大5個)'),
confidence: z.number().min(0).max(1).describe('分析信頼度(0〜1)')
});
// Anthropic Tool形式でスキーマを定義
// (zodToJsonSchemaライブラリなしで直接書く例)
const extractMetadataTool: Anthropic.Messages.Tool = {
name: 'extract_metadata',
description: 'ドキュメントからメタデータを抽出します',
input_schema: {
type: 'object',
properties: {
title: {
type: 'string',
description: 'ドキュメントの核心的なタイトル'
},
tags: {
type: 'array',
items: { type: 'string' },
description: '関連タグ一覧(最大5個)'
},
confidence: {
type: 'number',
minimum: 0,
maximum: 1,
description: '分析信頼度(0〜1)'
}
},
required: ['title', 'tags', 'confidence']
}
};
async function extractMetadata(content: string) {
const response = await client.messages.create({
model: 'claude-sonnet-4-6',
max_tokens: 1024,
tools: [extractMetadataTool],
tool_choice: { type: 'auto' },
messages: [
{
role: 'user',
content: `次の内容からメタデータを抽出してください:\n\n${content}`
}
]
});
// tool_useブロックを探す
const toolUseBlock = response.content.find(
block => block.type === 'tool_use' && block.name === 'extract_metadata'
);
if (!toolUseBlock || toolUseBlock.type !== 'tool_use') {
throw new Error('ツールが呼び出されませんでした');
}
// tool_useのinputはunknown型 — Zodで検証
const result = ArticleMetadataSchema.safeParse(toolUseBlock.input);
if (!result.success) {
throw new Error(
`tool_use入力検証失敗: ${JSON.stringify(result.error.format())}`
);
}
return result.data;
}Tool UseパターンがPattern 1より安定している理由がある。ClaudeはツールのinputにJSONを直接構造化して返す。マークダウンのコードフェンスや説明テキストが割り込む余地がない。SDKが内部的にJSONパースまで処理してくれるので、JSON.parse()の失敗を別途処理する必要がない。
ただし、Tool UseでもZod検証はスキップしてはいけない。toolUseBlock.inputの型はunknownだ。Claudeが誤った型を返した場合、型エラーがランタイムまで隠れていて爆発する。
プロダクションエラー処理パターン
LLM応答パースでのエラーは2つのレイヤーで発生する。JSONパース段階とZod検証段階だ。2つのレイヤーを分けて処理することでデバッグが楽になる。
エラーレイヤーの分離
type ParseResult<T> =
| { success: true; data: T }
| { success: false; stage: 'json' | 'schema'; error: string; raw?: string };
function parseLLMResponse<T>(
text: string,
schema: z.ZodType<T>
): ParseResult<T> {
// レイヤー1: JSONパース
let parsed: unknown;
try {
const jsonText = extractJsonFromResponse(text);
parsed = JSON.parse(jsonText);
} catch (err) {
return {
success: false,
stage: 'json',
error: err instanceof Error ? err.message : String(err),
raw: text
};
}
// レイヤー2: Zodスキーマ検証
const result = schema.safeParse(parsed);
if (!result.success) {
return {
success: false,
stage: 'schema',
error: formatZodError(result.error),
raw: text
};
}
return { success: true, data: result.data };
}
function formatZodError(error: z.ZodError): string {
return error.issues
.map(issue => {
const path = issue.path.length > 0
? `[${issue.path.join('.')}]`
: '[root]';
return `${path} ${issue.message}`;
})
.join('; ');
}error.format()で構造化されたエラーを返す
v4でもerror.format()が存在する。フィールドごとにエラーを構造化して返してくれる。
const result = BlogAnalysisSchema.safeParse(badData);
if (!result.success) {
const formatted = result.error.format();
// 返却例:
// {
// _errors: [],
// title: { _errors: ['Too small: expected string to have >=1 characters'] },
// tags: { _errors: ['Too small: expected array to have >=1 items'] }
// }
// 特定フィールドのエラーだけ取り出す
const titleErrors = formatted.title?._errors ?? [];
const tagsErrors = formatted.tags?._errors ?? [];
}クライアントにエラーを返したりログに残したりする際にフィールドごとに整理された形が必要ならerror.format()が便利だ。単純にエラー一覧だけ必要ならerror.issues配列を直接使う方がシンプルだ。
リトライロジックとフォールバック
LLM応答パースが失敗したときにリトライするパターンがある。プロンプトにエラーメッセージを含めてLLMに修正を依頼する方式だ。
async function analyzeWithRetry(
content: string,
schema: z.ZodType<unknown>,
maxRetries = 2
): Promise<unknown> {
let lastError = '';
for (let attempt = 0; attempt <= maxRetries; attempt++) {
const systemPrompt = attempt === 0
? BASE_SYSTEM_PROMPT
: `${BASE_SYSTEM_PROMPT}\n\n前の応答で次のエラーが発生しました: ${lastError}\n正確に要求したJSON形式のみで応答してください。`;
const response = await client.messages.create({
model: 'claude-sonnet-4-6',
max_tokens: 1024,
system: systemPrompt,
messages: [{ role: 'user', content }]
});
const textBlock = response.content.find(b => b.type === 'text');
if (!textBlock || textBlock.type !== 'text') continue;
const parseResult = parseLLMResponse(textBlock.text, schema);
if (parseResult.success) return parseResult.data;
lastError = parseResult.error;
console.warn(`Attempt ${attempt + 1} failed: ${lastError}`);
}
throw new Error(`${maxRetries + 1}回試行後パース失敗: ${lastError}`);
}リトライ回数を増やしすぎるとAPI費用が上がる。2回以下が現実的だ。
パフォーマンス: Zod v4の実際の速度は
Apple Siliconで直接ベンチマークを回した。4フィールドのオブジェクトスキーマを基準に100,000回safeParse()を繰り返した。
const UserSchema = z.object({
name: z.string().min(1),
email: z.email(),
age: z.number().int().min(0).max(150),
role: z.enum(['admin', 'user', 'viewer'])
});
const testData = {
name: 'Jangwook',
email: 'kim.jangwook@example.com',
age: 30,
role: 'admin'
};
const iterations = 100_000;
const start = performance.now();
for (let i = 0; i < iterations; i++) {
UserSchema.safeParse(testData);
}
const duration = performance.now() - start;
const parsesPerSecond = Math.round(iterations / (duration / 1000));
console.log(`duration: ${duration.toFixed(2)}ms`);
console.log(`parses/second: ${parsesPerSecond.toLocaleString()}`);結果は次の通りだった。
iterations: 100,000
duration: 45.78ms
parses/second: 2,184,4811秒あたり218万回パース。Claude API応答を処理する用途としては過剰だ。APIレスポンスタイム自体が数百ミリ秒から数秒単位なので、Zodのパース速度がボトルネックになることはない。
この数値が意味を持つのはバッチ処理の場面だ。数百万件のログやイベントデータをZodで検証するパイプラインなら、v4の速度向上がはっきりと体感できる。LLM応答パース単独の用途では、v3からv4に移行するパフォーマンス上の理由は大きくない。
新規プロジェクトならZod v4を選ぶ。既存のv3コードベースを今すぐマイグレーションする理由は大きくない。v4がプロダクションに使えるだけ十分に成熟したという判断ではあるが、v3のコードが問題なく動いているなら急ぐ必要はない。
環境ごとのパフォーマンス差
Apple Silicon Mシリーズで測定した数値だ。AWSやGCPのLinux x86インスタンスでは異なる結果が出る。CI環境でパフォーマンスを保証する必要があるなら直接測定すべきだ。公式の数値をそのまま信用するのは勧めない。
実践統合例: ブログ投稿メタデータ抽出ツール
ここまで説明したパターンを組み合わせた、実際に使えるサンプルだ。
import Anthropic from '@anthropic-ai/sdk';
import { z } from 'zod';
const client = new Anthropic();
// ブログ投稿メタデータスキーマ
const PostMetadataSchema = z.object({
title: z.string().min(1).max(100),
description: z.string().min(50).max(200),
tags: z.array(z.string().min(1)).min(1).max(5),
difficulty: z.enum(['beginner', 'intermediate', 'advanced']),
estimatedReadingTime: z.number().int().min(1).max(60),
hasCodeExamples: z.boolean(),
targetAudience: z.string().min(10).max(100)
});
type PostMetadata = z.infer<typeof PostMetadataSchema>;
async function extractPostMetadata(
markdownContent: string
): Promise<PostMetadata> {
const response = await client.messages.create({
model: 'claude-sonnet-4-6',
max_tokens: 1024,
system: `技術ブログ投稿を分析して、メタデータをJSONで返してください。
必ず以下の形式を守ること:
{
"title": "投稿の核心タイトル(100文字以下)",
"description": "SEO用の説明(50〜200文字)",
"tags": ["タグ1", "タグ2"],
"difficulty": "beginner" | "intermediate" | "advanced",
"estimatedReadingTime": 数値(分),
"hasCodeExamples": true | false,
"targetAudience": "対象読者の説明(10〜100文字)"
}`,
messages: [
{
role: 'user',
content: `次のマークダウンコンテンツを分析してください:\n\n${markdownContent}`
}
]
});
const textBlock = response.content.find(b => b.type === 'text');
if (!textBlock || textBlock.type !== 'text') {
throw new Error('テキスト応答がありません');
}
const parseResult = parseLLMResponse(textBlock.text, PostMetadataSchema);
if (!parseResult.success) {
throw new Error(
`メタデータ抽出失敗 [${parseResult.stage}]: ${parseResult.error}`
);
}
return parseResult.data;
}TypeScriptで自分だけのMCPサーバーを作るでMCPツールを実装するときも、このパターンがそのまま使える。ツールハンドラー関数でLLMを呼び出し、応答をZodで検証してから構造化された結果を返せばいい。
Vitest 4でAIエージェントをテストするで扱ったように、この関数を単体テストする際はclient.messages.create()をモッキングしてsafeParse()の結果をアサートすればいい。Zodスキーマがあればテストフィクスチャをスキーマ基準で作れるので便利だ。
v3からv4へのマイグレーションチェックリスト
Infinity、-Infinity値をz.number()で検証していたコードを確認required_error、invalid_type_errorパラメーター →errorに統合- エラーメッセージ文字列をテストで直接比較しているコードを修正
z.string().email()→z.email()に段階的に変更(旧バージョンも動くがv4スタイルへ).and()→z.intersection(A, B)に変更(まだ動くが公式サポート終了予定)- コミュニティのcodemod
zod-v3-to-v4の活用を検討(大規模コードベース向け)
マイグレーションが負担なら、z.number()関連のbreaking changeだけ先に確認するだけで十分だ。それ以外は段階的に対応できる。
まとめ
Zod v4はLLM応答パースに使える。safeParse()の型安全性、ネストスキーマのサポート、統合されたエラーAPIがClaude APIとうまく噛み合う。パフォーマンス向上はLLM応答パース用途では体感しにくいが、TypeScriptコンパイル速度の改善は大規模プロジェクトで実質的な差を生む。
不便な点を一つ挙げるなら、.check() APIのTypeScriptサポートがまだ完全ではないことだ。カスタムissueをctx.issues.push()で追加する際、自動補完なしで書かなければならない。この部分は今後の改善が必要だ。
新規プロジェクトならZod v4を使い、既存のv3コードベースならbreaking changeの一覧を確認してから段階的にマイグレーションするのをお勧めする。
他の言語で読む
- 🇰🇷 한국어
- 🇯🇵 日本語(現在のページ)
- 🇺🇸 English
- 🇨🇳 中文
この記事は役に立ちましたか?
より良いコンテンツを作成するための力になります。コーヒー一杯で応援してください。
関連記事
-
TypeScriptで自分だけのMCPサーバーを作る — @modelcontextprotocol/sdk 実践チュートリアル
MCPサーバーでツール入力値を検証するとき、Zod v4スキーマが直接使われる。この記事のsafeParseパターンがMCPツールハンドラー内でそのまま動く。

-
Vitest 4でAIエージェントをテストする — LLM呼び出しモック、ストリーミングレスポンステストの実践パターン
Zodスキーマでパースしたレスポンスを単体テストするとき、Vitest 4のモッキングパターンが必要になる。Claude APIレスポンスをモッキングしてsafeParse結果をアサートする方法がこの記事と繋がる。
-
Claude Agent SDK 実践ガイド — Tool UseでAIエージェントが実際に行動するようにする方法
Tool Use レスポンスのinputフィールドを安全にパースするにはZodスキーマが必須だ。tool_useブロックのJSON入力をタイプセーフに処理するパターンをこの記事と一緒に見ると完成する。
