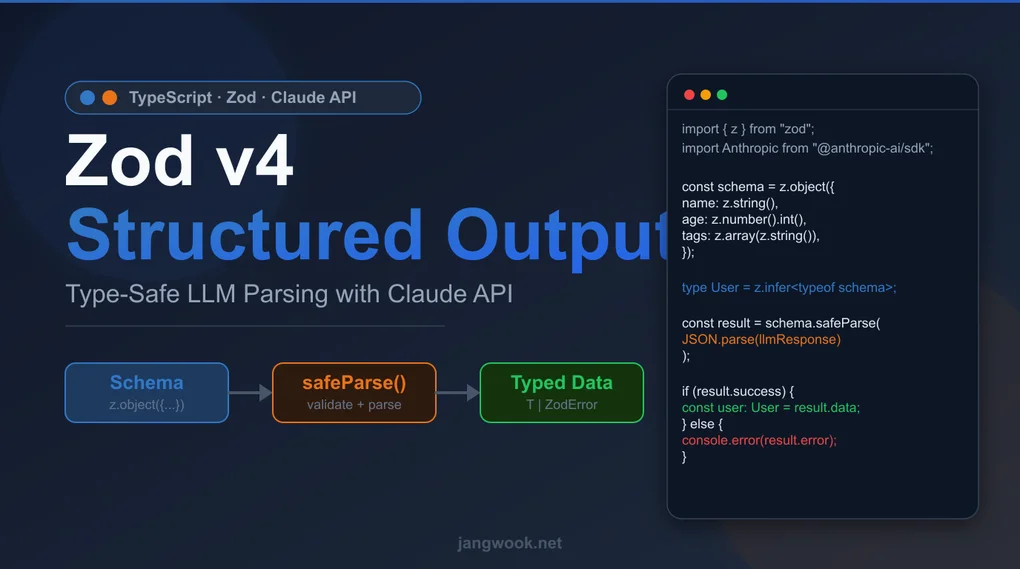
TypeScript Zod v4 + Claude API 结构化输出完全指南 — 类型安全的LLM响应解析实战
通过实际测试Zod v4的safeParse()和更新的schema API处理Claude API响应,构建类型安全的LLM输出解析方案。涵盖v3性能对比、z.string().check()新API、嵌套schema设计策略和生产级错误处理模式。
曾经有一次,我只用 JSON.parse() 处理 Claude API 返回的 JSON 字符串,结果在运行时碰到了错误。解析 content[0].text 取出的对象,并没有任何保证它包含预期字段。LLM 可能忽略提示词,或者把字段名稍微改一下,或者混淆类型。Zod v4 在类型层面解决了这个问题。
本文基于 Zod 4.4.3 和 @anthropic-ai/sdk 0.100.1,整理了安全解析 Claude API 响应的实战模式。我亲自跑了 100,000 次解析的基准测试,也用代码验证了 v3 之后 API 究竟发生了哪些变化。
Zod v4 与 v3 的实际差异
官方公告中的头条数字相当亮眼:字符串解析快 14 倍,数组快 7 倍,对象快 6.5 倍;包体积减少 57%;TypeScript 类型实例化最多减少 100 倍。但看起来数字好看,并不意味着要立刻迁移。
我亲自用过之后,感受到的变化有三点。
第一,错误信息更清晰了。v3 中通过 required_error 自定义消息的模式,被统一到了单一的 error 参数。同时,默认错误信息的格式也变了。v3 里是 "String must contain at least 1 character(s)",v4 里变成了 "Too small: expected string to have >=1 characters"。如果代码库里有直接对错误消息字符串做断言的测试,这些测试会挂掉。
第二,数字校验变严格了。Infinity 和 -Infinity 在 v3 中能通过 z.number(),v4 返回 success: false。超过 Number.MAX_SAFE_INTEGER 的整数在 z.number().int() 中也会被拒绝。如果代码里可能收到来自外部 API 或 LLM 响应的极端值,需要特别留意。
第三,API 设计更整洁了。v4 风格是用 z.email() 替代 z.string().email(),用 z.intersection(A, B) 替代 .and(),同时新增了 .check() 方法,用于内联自定义校验。
坦率地说,v4 并不总是比 v3 快。社区基准测试中,某些深度嵌套 schema 的场景下,v3 反而更快。头条数字基于常规模式,并不适用于所有代码。
v4 声称移除但实际仍存在的 API
官方文档说 .and() 方法已被移除,但在 4.4.3 中实测仍然存在且正常运行。迁移指南似乎跑在实际发布版本前面了。required_error 参数也类似,技术上还能用,但消息格式变了。看起来是悄悄 deprecated,而不是硬性删除。
制定迁移计划时,与其相信文档,不如在实际版本上亲自验证更稳妥。
安装与基本配置
npm install zod@^4.4.3
npm install @anthropic-ai/sdk@^0.100.1TypeScript 项目的 tsconfig.json 里需要开启 strict: true,Zod 的类型推断才能正常工作。
{
"compilerOptions": {
"strict": true,
"target": "ES2022",
"module": "ESNext",
"moduleResolution": "bundler"
}
}安装后,验证基本行为的最小代码如下:
import { z } from 'zod';
const UserSchema = z.object({
name: z.string().min(1),
email: z.email(), // v4 风格:替代 z.string().email()
age: z.number().int().min(0).max(150),
role: z.enum(['admin', 'user', 'viewer'])
});
type User = z.infer<typeof UserSchema>;
const result = UserSchema.safeParse({
name: 'Jangwook',
email: 'kim.jangwook@example.com',
age: 30,
role: 'admin'
});
if (result.success) {
console.log(result.data.name); // 类型:string
} else {
console.log(result.error.issues);
}运行结果符合预期:
success: true
parsed data: {"name":"Jangwook","email":"kim.jangwook@example.com","age":30,"role":"admin"}@zod/mini 是独立包
官方公告中包含了 @zod/mini,这是一个约 1.9KB gzip 的可 tree-shake 发行版,在前端包体积敏感时很有用。不过它的 API 接口和主 zod 包有差异。本文讨论的是服务端与 Claude API 的集成,因此以主包为准。
针对 LLM 响应设计 schema
解析 LLM 响应的 schema 和普通表单数据的 schema,设计思路不同。核心区别在于防御性可选字段处理。
LLM 可能不会返回请求的所有字段,响应质量也不稳定,提示词一变结构就可能变。schema 设计要反映这个现实。
基础 LLM 响应 schema
import { z } from 'zod';
// 博客文章分析响应 schema
const BlogAnalysisSchema = z.object({
title: z.string().min(1).max(200),
summary: z.string().min(10),
tags: z.array(z.string()).min(1).max(10),
sentiment: z.enum(['positive', 'neutral', 'negative']),
readingTimeMinutes: z.number().int().min(1).max(60),
// LLM 不一定总会返回的可选字段
seoScore: z.number().min(0).max(1).optional(),
suggestedImprovements: z.array(z.string()).optional()
});
type BlogAnalysis = z.infer<typeof BlogAnalysisSchema>;含元数据的嵌套 schema
Claude API 返回结构化数据时,有时需要附带响应本身的元信息,比如置信度分数或模型信息。
const LLMResponseSchema = z.object({
// 实际内容
content: z.object({
title: z.string().min(1),
tags: z.array(z.string()),
body: z.string()
}),
// 响应元数据(可选)
metadata: z.object({
model: z.string(),
confidence: z.number().min(0).max(1),
processingTimeMs: z.number().int().positive()
}).optional()
});在我的实测中,带 .optional() 的嵌套对象行为符合预期。即使没有 metadata 字段,解析也能成功。
LLM response (with metadata) success: true
title: Zod v4: A Deep Dive into Schema Validation
confidence: 0.92
LLM response (no metadata) success: true用 z.string().check() 校验 LLM 响应格式
v4 新增的 .check() API 在特定场景下很有用:当 LLM 需要返回带特定前缀或格式的响应时。
// LLM 必须带 "RESULT:" 前缀的响应
const LLMResultSchema = z.string().check((ctx) => {
if (!ctx.value.startsWith('RESULT:')) {
ctx.issues.push({
code: 'custom',
message: 'LLM 响应必须以 "RESULT:" 开头',
input: ctx.value
});
}
});
const valid = LLMResultSchema.safeParse('RESULT: 分析完成');
const invalid = LLMResultSchema.safeParse('分析完成');
console.log(valid.success); // true
console.log(invalid.success); // false有一点需要注意:.check() 回调中,ctx.issues.push() 接受的 issue 对象的 TypeScript 自动补全做得不够好。code: 'custom'、message、input 字段是必须的,但编辑器里提示不太出来。第一次用的人容易犯错。
用 Zod 解析 Claude API 响应
Pattern 1:通过提示词请求 JSON 响应后解析
最简单的模式。在系统提示中指定 JSON 格式,对响应文本做 JSON.parse(),再用 Zod 校验。
import Anthropic from '@anthropic-ai/sdk';
import { z } from 'zod';
const client = new Anthropic();
// 定义期望的响应结构
const ArticleAnalysisSchema = z.object({
title: z.string().min(1),
mainTopics: z.array(z.string()).min(1).max(5),
difficulty: z.enum(['beginner', 'intermediate', 'advanced']),
estimatedReadTime: z.number().int().positive(),
hasCodeExamples: z.boolean()
});
type ArticleAnalysis = z.infer<typeof ArticleAnalysisSchema>;
async function analyzeArticle(content: string): Promise<ArticleAnalysis> {
const response = await client.messages.create({
model: 'claude-sonnet-4-6',
max_tokens: 1024,
system: `你是一个技术文档分析器。
必须仅以以下 JSON 格式响应:
{
"title": "文档标题",
"mainTopics": ["主题1", "主题2"],
"difficulty": "beginner" | "intermediate" | "advanced",
"estimatedReadTime": 数字(分钟),
"hasCodeExamples": true | false
}
不要在 JSON 之外包含任何文本。`,
messages: [
{ role: 'user', content: `请分析以下文档:\n\n${content}` }
]
});
// 提取响应文本
const textContent = response.content.find(block => block.type === 'text');
if (!textContent || textContent.type !== 'text') {
throw new Error('没有文本响应');
}
// JSON 解析
let parsed: unknown;
try {
parsed = JSON.parse(textContent.text);
} catch {
throw new Error(`JSON 解析失败: ${textContent.text}`);
}
// Zod 校验
const result = ArticleAnalysisSchema.safeParse(parsed);
if (!result.success) {
const errorSummary = result.error.issues
.map(issue => `${issue.path.join('.')}: ${issue.message}`)
.join(', ');
throw new Error(`schema 校验失败: ${errorSummary}`);
}
return result.data;
}这个模式的弱点是:当 LLM 在 JSON 前后加上 Markdown 代码围栏或说明文字时,JSON.parse() 会失败。需要实用的处理方式。
function extractJsonFromResponse(text: string): string {
// 从 ```json ... ``` 块中提取 JSON
const codeBlockMatch = text.match(/```(?:json)?\s*([\s\S]*?)\s*```/);
if (codeBlockMatch) {
return codeBlockMatch[1];
}
// 提取以大括号开始和结束的部分
const jsonMatch = text.match(/\{[\s\S]*\}/);
if (jsonMatch) {
return jsonMatch[0];
}
return text;
}Pattern 2:用 Tool Use 强制结构化输出
如 Claude Agent SDK Tool Use 完全指南 所述,利用 tool_use 可以强制要求 JSON 格式。让 LLM 以”调用工具”的形式返回结构化数据。
import Anthropic from '@anthropic-ai/sdk';
import { z } from 'zod';
const client = new Anthropic();
// 将 Zod schema 转换为 Tool 定义的输入 schema
const ArticleMetadataSchema = z.object({
title: z.string().describe('文档的核心标题'),
tags: z.array(z.string()).describe('相关标签列表(最多 5 个)'),
confidence: z.number().min(0).max(1).describe('分析置信度(0〜1)')
});
// 以 Anthropic Tool 格式定义 schema
// (不使用 zodToJsonSchema 库,直接手写的示例)
const extractMetadataTool: Anthropic.Messages.Tool = {
name: 'extract_metadata',
description: '从文档中提取元数据',
input_schema: {
type: 'object',
properties: {
title: {
type: 'string',
description: '文档的核心标题'
},
tags: {
type: 'array',
items: { type: 'string' },
description: '相关标签列表(最多 5 个)'
},
confidence: {
type: 'number',
minimum: 0,
maximum: 1,
description: '分析置信度(0〜1)'
}
},
required: ['title', 'tags', 'confidence']
}
};
async function extractMetadata(content: string) {
const response = await client.messages.create({
model: 'claude-sonnet-4-6',
max_tokens: 1024,
tools: [extractMetadataTool],
tool_choice: { type: 'auto' },
messages: [
{
role: 'user',
content: `请从以下内容中提取元数据:\n\n${content}`
}
]
});
// 找到 tool_use 块
const toolUseBlock = response.content.find(
block => block.type === 'tool_use' && block.name === 'extract_metadata'
);
if (!toolUseBlock || toolUseBlock.type !== 'tool_use') {
throw new Error('工具未被调用');
}
// tool_use 的 input 是 unknown 类型 — 用 Zod 校验
const result = ArticleMetadataSchema.safeParse(toolUseBlock.input);
if (!result.success) {
throw new Error(
`tool_use 输入校验失败: ${JSON.stringify(result.error.format())}`
);
}
return result.data;
}Tool Use 模式比 Pattern 1 更稳定的原因在于:Claude 直接将 JSON 结构化写入工具 input,没有 Markdown 代码围栏或说明文字插入的空间。SDK 内部处理了 JSON 解析,无需单独处理 JSON.parse() 失败的情况。
不过,Tool Use 也不能跳过 Zod 校验。toolUseBlock.input 的类型是 unknown。如果 Claude 返回了错误的类型,类型错误会一直藏到运行时才爆出来。
生产级错误处理模式
LLM 响应解析的错误发生在两个层面:JSON 解析阶段和 Zod 校验阶段。分层处理才方便调试。
错误层分离
type ParseResult<T> =
| { success: true; data: T }
| { success: false; stage: 'json' | 'schema'; error: string; raw?: string };
function parseLLMResponse<T>(
text: string,
schema: z.ZodType<T>
): ParseResult<T> {
// 第 1 层:JSON 解析
let parsed: unknown;
try {
const jsonText = extractJsonFromResponse(text);
parsed = JSON.parse(jsonText);
} catch (err) {
return {
success: false,
stage: 'json',
error: err instanceof Error ? err.message : String(err),
raw: text
};
}
// 第 2 层:Zod schema 校验
const result = schema.safeParse(parsed);
if (!result.success) {
return {
success: false,
stage: 'schema',
error: formatZodError(result.error),
raw: text
};
}
return { success: true, data: result.data };
}
function formatZodError(error: z.ZodError): string {
return error.issues
.map(issue => {
const path = issue.path.length > 0
? `[${issue.path.join('.')}]`
: '[root]';
return `${path} ${issue.message}`;
})
.join('; ');
}用 error.format() 返回结构化错误
v4 中 error.format() 仍然存在,可以按字段结构化返回错误。
const result = BlogAnalysisSchema.safeParse(badData);
if (!result.success) {
const formatted = result.error.format();
// 返回示例:
// {
// _errors: [],
// title: { _errors: ['Too small: expected string to have >=1 characters'] },
// tags: { _errors: ['Too small: expected array to have >=1 items'] }
// }
// 只取特定字段的错误
const titleErrors = formatted.title?._errors ?? [];
const tagsErrors = formatted.tags?._errors ?? [];
}向客户端返回错误或写日志时,如果需要按字段整理,error.format() 很方便。如果只需要错误列表,直接用 error.issues 数组更简单。
重试逻辑与降级
LLM 响应解析失败时,有一种重试模式:把错误信息放进提示词,让 LLM 修正后重试。
async function analyzeWithRetry(
content: string,
schema: z.ZodType<unknown>,
maxRetries = 2
): Promise<unknown> {
let lastError = '';
for (let attempt = 0; attempt <= maxRetries; attempt++) {
const systemPrompt = attempt === 0
? BASE_SYSTEM_PROMPT
: `${BASE_SYSTEM_PROMPT}\n\n上次响应出现以下错误:${lastError}\n请严格按照要求的 JSON 格式响应。`;
const response = await client.messages.create({
model: 'claude-sonnet-4-6',
max_tokens: 1024,
system: systemPrompt,
messages: [{ role: 'user', content }]
});
const textBlock = response.content.find(b => b.type === 'text');
if (!textBlock || textBlock.type !== 'text') continue;
const parseResult = parseLLMResponse(textBlock.text, schema);
if (parseResult.success) return parseResult.data;
lastError = parseResult.error;
console.warn(`Attempt ${attempt + 1} failed: ${lastError}`);
}
throw new Error(`${maxRetries + 1} 次尝试后解析失败: ${lastError}`);
}重试次数太多会推高 API 成本。2 次以下比较现实。
性能:Zod v4 的实际速度
我在 Apple Silicon 上亲自跑了基准测试。基于 4 个字段的对象 schema,重复执行 100,000 次 safeParse()。
const UserSchema = z.object({
name: z.string().min(1),
email: z.email(),
age: z.number().int().min(0).max(150),
role: z.enum(['admin', 'user', 'viewer'])
});
const testData = {
name: 'Jangwook',
email: 'kim.jangwook@example.com',
age: 30,
role: 'admin'
};
const iterations = 100_000;
const start = performance.now();
for (let i = 0; i < iterations; i++) {
UserSchema.safeParse(testData);
}
const duration = performance.now() - start;
const parsesPerSecond = Math.round(iterations / (duration / 1000));
console.log(`duration: ${duration.toFixed(2)}ms`);
console.log(`parses/second: ${parsesPerSecond.toLocaleString()}`);结果如下:
iterations: 100,000
duration: 45.78ms
parses/second: 2,184,481每秒解析 218 万次。对于处理 Claude API 响应来说完全是过剩的。API 响应本身就需要几百毫秒到数秒,Zod 的解析速度不会成为瓶颈。
这个数字真正有意义的场景是批量处理:对数百万条日志或事件数据用 Zod 做校验的管道,v4 的速度提升会有明显体感。单纯用于 LLM 响应解析,从 v3 升到 v4 的性能理由并不充分。
我现在的判断是:新项目选 Zod v4,已有 v3 代码库没有立刻迁移的必要。v4 已经足够成熟可以用于生产,但 v3 代码跑得好好的,不必着急。
不同环境下的性能差异
上面的数字是在 Apple Silicon M 系列上测的。在 AWS 或 GCP 的 Linux x86 实例上会有所不同。如果需要在 CI 环境保证性能,必须自己实测,不建议直接照搬官方数字。
实战整合示例:博客文章元数据提取器
把前面讲的模式组合起来,一个实际可用的示例如下。
import Anthropic from '@anthropic-ai/sdk';
import { z } from 'zod';
const client = new Anthropic();
// 博客文章元数据 schema
const PostMetadataSchema = z.object({
title: z.string().min(1).max(100),
description: z.string().min(50).max(200),
tags: z.array(z.string().min(1)).min(1).max(5),
difficulty: z.enum(['beginner', 'intermediate', 'advanced']),
estimatedReadingTime: z.number().int().min(1).max(60),
hasCodeExamples: z.boolean(),
targetAudience: z.string().min(10).max(100)
});
type PostMetadata = z.infer<typeof PostMetadataSchema>;
async function extractPostMetadata(
markdownContent: string
): Promise<PostMetadata> {
const response = await client.messages.create({
model: 'claude-sonnet-4-6',
max_tokens: 1024,
system: `分析技术博客文章,以 JSON 格式返回元数据。
必须严格遵守以下格式:
{
"title": "文章核心标题(100 字以下)",
"description": "SEO 描述(50〜200 字)",
"tags": ["标签1", "标签2"],
"difficulty": "beginner" | "intermediate" | "advanced",
"estimatedReadingTime": 数字(分钟),
"hasCodeExamples": true | false,
"targetAudience": "目标读者说明(10〜100 字)"
}`,
messages: [
{
role: 'user',
content: `请分析以下 Markdown 内容:\n\n${markdownContent}`
}
]
});
const textBlock = response.content.find(b => b.type === 'text');
if (!textBlock || textBlock.type !== 'text') {
throw new Error('没有文本响应');
}
const parseResult = parseLLMResponse(textBlock.text, PostMetadataSchema);
if (!parseResult.success) {
throw new Error(
`元数据提取失败 [${parseResult.stage}]: ${parseResult.error}`
);
}
return parseResult.data;
}在 用 TypeScript 打造自己的 MCP 服务器 中实现 MCP 工具时,这个模式同样适用。在工具处理函数里调用 LLM,用 Zod 校验响应,然后返回结构化结果即可。
如 用 Vitest 4 测试 AI Agent 中所述,对这个函数做单元测试时,mock 掉 client.messages.create(),然后断言 safeParse() 的结果就好。有了 Zod schema,可以按 schema 来生成测试 fixture,非常方便。
从 v3 迁移到 v4 的检查清单
- 检查用
z.number()校验Infinity、-Infinity值的代码 required_error、invalid_type_error参数 → 统一为error- 修改测试中直接比对错误消息字符串的代码
z.string().email()→ 逐步改为z.email()(旧写法仍能用,但推荐 v4 风格).and()→z.intersection(A, B)(目前仍能用,但官方支持即将终止)- 考虑使用社区 codemod
zod-v3-to-v4(适合大型代码库)
如果迁移压力比较大,先只排查 z.number() 相关的 breaking change 就够了。其余可以逐步处理。
总结
Zod v4 用于 LLM 响应解析是值得的。safeParse() 的类型安全性、嵌套 schema 支持,以及统一的错误 API,与 Claude API 配合得很好。性能提升在 LLM 响应解析这个场景下体感不明显,但 TypeScript 编译速度的改善在大型项目里会产生实质性差异。
如果要挑一个不方便的地方,就是 .check() API 的 TypeScript 支持还不完整。用 ctx.issues.push() 写入自定义 issue 时,没有自动补全,只能靠手写。这部分还需要改进。
新项目推荐选 Zod v4;已有 v3 代码库的话,先确认 breaking change 列表,再逐步迁移。
阅读其他语言版本
- 🇰🇷 한국어
- 🇯🇵 日本語
- 🇺🇸 English
- 🇨🇳 中文(当前页面)
这篇文章有帮助吗?
您的支持能帮助我创作更好的内容。请我喝杯咖啡吧。
相关文章
-
用TypeScript构建自己的MCP服务器 — @modelcontextprotocol/sdk实战教程
在 MCP 服务器中验证工具输入值时,Zod v4 模式直接可用。这篇文章的 safeParse 模式在 MCP 工具处理程序中直接运行。

-
用 Vitest 4 测试 AI 代理 — LLM 调用模拟、流式响应测试实战模式
对通过 Zod 模式解析的 LLM 响应进行单元测试时,需要 Vitest 4 的模拟模式。模拟 Claude API 响应并断言 safeParse 结果与这篇文章直接相关。
-
Claude Agent SDK 实战指南 — 用Tool Use让AI代理真正执行任务
安全解析 Tool Use 响应的 input 字段需要 Zod 模式。将这篇文章与 Tool Use 指南一起阅读,就完成了类型安全处理 tool_use 块 JSON 输入的完整模式。
