Anthropic이 OpenClaw를 끊은 이유 — Claude 구독 정책 전환과 개발자 비용 현실
2026년 4월 4일, Anthropic이 Claude Pro/Max 구독으로 서드파티 에이전트(OpenClaw 등)를 차단했다. Fast Mode 6배 과금과 새 토큰나이저 비용 충격까지 더해진 구조적 전환이 개발자 워크플로우에 미치는 영향을 비용 계산과 함께 분석한다.
4월 4일, Anthropic이 조용히 약관을 바꿨다. 변경 내용은 단순하다: Claude Pro나 Max 구독으로 OpenClaw 같은 서드파티 에이전트 프레임워크를 구동할 수 없다. 이제 API 직접 과금이다.
나는 이 소식을 OpenClaw 커뮤니티에서 먼저 봤다. 처음엔 “또 약관 문구 정비인가” 싶었는데, 실제로 어떤 의미인지 계산해보니 생각보다 큰 이야기였다. 직접 Python으로 비용 계산 스크립트를 짜서 시나리오별 수치를 뽑아봤다. 결론부터 말하면 — 최적화 없이 그냥 쓰면 최대 10배 인상, 설계를 제대로 바꾸면 오히려 저렴해진다는 것이다.
이 글은 수치 기반의 분석이다. “Anthropic이 나쁘다” 혹은 “이해할 수 있다”는 정성적 의견보다는, 지금 무슨 일이 일어난 건지, 숫자로 보면 얼마나 달라지는지, 그리고 나라면 어떻게 대응하겠는지를 정리했다.
Anthropic이 구독을 끊은 이유
Anthropic의 공식 입장은 “용량은 신중하게 관리하는 자원”이라는 것이다. 이 설명은 솔직히 충분히 납득이 간다.
$200짜리 Claude Max 구독을 들고 OpenClaw로 자율 에이전트를 돌리면 어떤 일이 벌어지냐면 — 에이전트는 사람이 아니어서 쉬지 않는다. 24시간, 분당 수십 번씩 API를 호출할 수 있다. 사람이 Opus를 하루 2시간 대화에 쓰는 게 아니라, 서버가 하루 24시간 Opus를 호출하는 구조다. Anthropic 측의 내부 계산으로는 “$200 구독 사용자가 $1,000〜$5,000 어치의 컴퓨팅 리소스를 쓴다”는 결론이 나왔다고 한다. 이게 과장인지 내 계산으로 직접 확인해봤는데 — 과장이 아니다.
500세션/일, 세션당 2,000 입력 + 500 출력 토큰을 Opus 4.7로 30일 돌리면 $337.50이다. $200 구독으로 커버하기엔 이미 1.7배를 초과한다. 에이전트가 더 길게 돌고 더 자주 호출된다면 비율은 금방 올라간다.
OpenClaw 창업자 Peter Steinberger는 이 결정에 즉각 반발했다. “API 단가로 전환하면 감당 불가능한 비용”이라고 밝혔고, Anthropic이 OpenClaw의 핵심 기능들을 자사 제품에 내재화한 뒤 외부 접근을 막은 것 아니냐는 의혹도 공개적으로 제기했다. 개발자 커뮤니티 일부에서는 “이러면 DeepSeek이나 다른 모델로 옮기겠다”는 반응이 나왔고, 실제로 대안 프레임워크 관련 GitHub 스타가 며칠 사이에 급등했다.
솔직히 말하면, 나는 Anthropic의 결정 자체가 완전히 틀렸다고 보기 어렵다. 구독 정액제를 AI 에이전트에 무한정 적용하는 건 구조적으로 지속 불가능하다. 그 부분은 맞다. 다만 기존 사용자에게 전환 준비 시간을 충분히 주지 않은 것, 그리고 Fast Mode라는 새로운 고비용 기능을 같은 시기에 도입하면서 혼란을 증폭시킨 타이밍은 좋지 않았다.
Fast Mode: 6배 과금의 구조와 숨겨진 함정
같은 시기에 Anthropic은 Fast Mode를 도입했다. 이게 단순히 “더 빠른 응답”이 아니라 완전히 다른 과금 구조라는 점을 짚어둬야 한다.
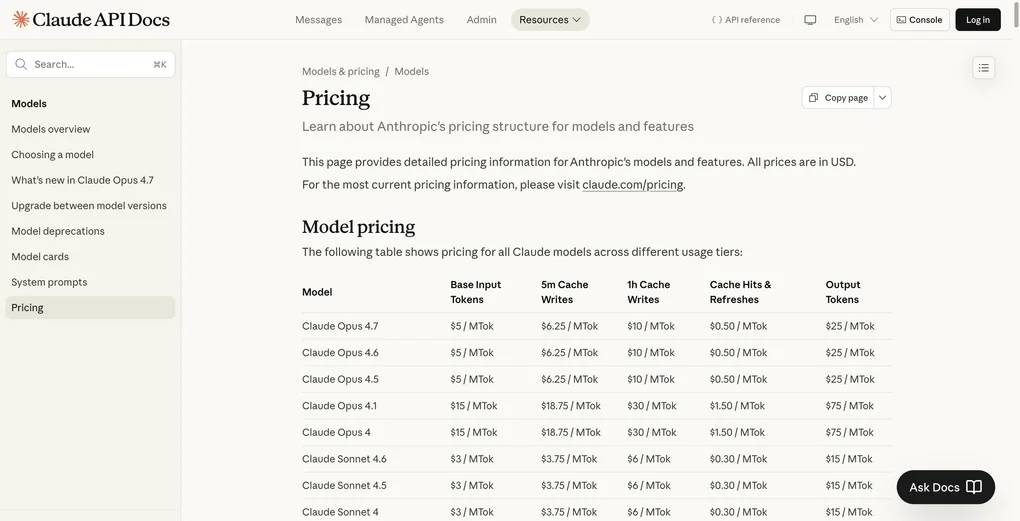
표준 Claude Opus 4.7 가격은 입력 $5, 출력 $25 (100만 토큰 기준)이다. Fast Mode를 켜면 입력 $30, 출력 $150으로 뛴다. 6배다. 200K 입력 토큰을 초과하면 입력이 $60으로 다시 올라간다. 공식 문서는 이를 “프리미엄 속도 기능에 대한 프리미엄 가격”이라고 설명하는데, 숫자 앞에서 설명은 큰 의미가 없다.
더 까다로운 부분은 세션 소급 적용 문제다. Fast Mode를 대화 중간에 켜면 이미 쌓인 컨텍스트 전체가 Fast Mode 단가로 소급 적용된다. 긴 대화를 이어가다가 실수로 Fast Mode를 켜거나, 코드에서 조건 분기가 잘못 설정되어 Fast Mode가 켜지면 청구서가 예측 불가능하게 튄다. 이걸 “hidden mechanics that turn forecast accuracy into fantasy”라고 표현한 분석이 있는데 정확하다.
또 하나의 제약: Fast Mode는 AWS Bedrock, Google Vertex AI, Microsoft Azure Foundry에서 사용 불가다. Anthropic 직접 API에서만 쓸 수 있다. 클라우드 콘솔에서 통합 관리하는 기업이라면 이 기능을 아예 못 쓴다는 뜻이기도 하다.
내 판단으로는, Fast Mode는 아주 특수한 상황 — 사용자가 기다리는 인터랙티브 UI에서 레이턴시가 비즈니스 KPI에 직접 연결될 때 — 에만 쓸 기능이다. 자동화 에이전트에 기본으로 켜두는 것은 재정적으로 위험하다.
실제 비용 계산: 케이스별 시나리오
직접 Python 스크립트를 짜서 공식 가격표를 기반으로 시나리오를 검증했다. 모든 수치는 platform.claude.com의 공식 가격 기준이다.
케이스 1: 헤비 OpenClaw 사용자 (500세션/일, 기존 구독 $200/월)
가정: 1세션당 입력 2,000토큰 + 출력 500토큰, 30일
Opus 4.7 표준 (최적화 없음): $337.50/월
Opus 4.7 Fast Mode (6배): $2,025.00/월
Opus 4.7 + 70% 캐시 적중: $243.00/월
Sonnet 4.6 + 70% 캐시: $145.80/월
Haiku 4.5 + 70% 캐시: $48.60/월
기존 Max 플랜 대비 배율: 1.7x ~ 10.1x최악의 경우(Fast Mode 무방비)는 10배 인상이다. 하지만 Sonnet 4.6으로 모델을 내리고 캐시 적중률을 70%로 끌어올리면 $145.80으로, 원래 $200 Max 플랜보다 오히려 저렴해진다. Haiku를 쓰면 $48.60이다.
케이스 2: 중간 규모 개발자 (일일 50세션, 블로그 자동화, 문서 분석 등)
Sonnet 4.6 최적화 없음: $20.25/월
80% 캐시 적중: $13.77/월
캐시 + Batch API: $6.88/월이 규모에서는 구독 차단이 오히려 비용이 내려간다. $200 Max 플랜으로 블로그 자동화 정도만 돌렸다면 API 직접 과금이 훨씬 합리적이다.
케이스 3: 일일 세션 볼륨에 따른 비용 추정 (Sonnet 4.6, 75% 캐시, Batch)
10 세션/일 → $1.42/월
50 세션/일 → $7.09/월
100 세션/일 → $14.18/월
500 세션/일 → $70.88/월
1,000 세션/일 → $141.75/월이 숫자를 보면 한 가지가 명확해진다. 에이전트 사용 패턴이 실제로 어느 수준인지 측정해본 적이 없다면, 지금 당장 로깅부터 해야 한다. 막연히 “매달 요청이 많다”는 감각으로 비용을 예측하는 시대는 끝났다.
Claude API 프롬프트 캐싱 최적화 패턴에서 캐시 적중률을 70〜80%로 끌어올리는 실제 구현 방법을 확인할 수 있다. 이번 정책 전환에서 캐싱은 단순한 최적화가 아니라 생존 전략이다.
비용을 낮추는 3가지 실질적 전략
전략 1: 모델 티어 분리 (라우팅 레이어 추가)
에이전트 워크플로우를 Task 유형에 따라 분리하는 게 첫 번째다. 모든 태스크를 Opus 4.7로 보내는 게 비용 폭탄의 주원인이다.
def route_to_model(task_type: str) -> str:
"""모델 라우팅 — 태스크 복잡도에 따라 분리"""
routing = {
# 복잡한 추론, 코드 생성 → Opus
"code_generation": "claude-opus-4-7",
"complex_reasoning": "claude-opus-4-7",
"multi_step_agent": "claude-opus-4-7",
# 중간 복잡도 → Sonnet
"summarization": "claude-sonnet-4-6",
"translation": "claude-sonnet-4-6",
"draft_review": "claude-sonnet-4-6",
# 단순 분류, 라우팅 → Haiku
"classification": "claude-haiku-4-5-20251001",
"routing": "claude-haiku-4-5-20251001",
"simple_extraction": "claude-haiku-4-5-20251001",
}
return routing.get(task_type, "claude-sonnet-4-6")코드 생성이나 복잡한 멀티스텝 에이전트는 Opus가 맞다. 하지만 문서 요약, 번역, 라우팅 판단 같은 태스크는 Sonnet이나 Haiku로 충분하다. 라우팅 레이어 하나를 추가하는 것만으로 전체 비용을 40〜60% 줄이는 경우를 많이 봤다.
전략 2: 프롬프트 캐싱 적극 활용
시스템 프롬프트나 자주 반복되는 컨텍스트는 캐시 마커를 달면 입력 토큰 비용이 90% 줄어든다. 캐시 TTL은 5분이므로 짧은 세션에서도 효과가 있다.
import anthropic
client = anthropic.Anthropic()
# 시스템 프롬프트 캐싱 — 반복 호출 시 비용 90% 절감
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
system=[
{
"type": "text",
"text": "당신은 코드 리뷰 전문가입니다...",
"cache_control": {"type": "ephemeral"} # 캐시 마커
}
],
messages=[{"role": "user", "content": user_request}]
)
# cache_creation_input_tokens vs cache_read_input_tokens로 적중률 확인
usage = response.usage
cache_hit_rate = usage.cache_read_input_tokens / (
usage.cache_creation_input_tokens + usage.cache_read_input_tokens + 1
)
print(f"캐시 적중률: {cache_hit_rate:.1%}")AI 에이전트 비용 현실 분석에서 다뤘던 것처럼, 에이전트 비용이 인건비를 넘는 시나리오는 캐싱 없이 Opus를 전방위로 쓸 때 현실이 된다. 캐싱 적중률을 로깅해서 추적하는 것 자체가 비용 가시화의 첫 단계다.
전략 3: Batch API로 비실시간 워크로드 분리
실시간 응답이 필요 없는 작업 — 문서 분석, 번역, 분류 배치, 야간 리포트 생성 — 은 Batch API를 쓰면 모든 비용이 50% 내려간다. 배치 결과는 일반적으로 24시간 내에 반환된다.
import anthropic
client = anthropic.Anthropic()
# 배치 요청 생성 — 50% 비용 절감
batch = client.messages.batches.create(
requests=[
{
"custom_id": f"task-{i}",
"params": {
"model": "claude-sonnet-4-6",
"max_tokens": 1024,
"messages": [{"role": "user", "content": doc}]
}
}
for i, doc in enumerate(documents_to_process)
]
)
print(f"배치 ID: {batch.id}")
print(f"처리 상태: {batch.processing_status}")이 세 가지를 조합하면 — 라우팅 + 70〜80% 캐시 + 배치 처리 — 대부분의 자동화 에이전트 워크로드를 기존 $200 Max 플랜 수준이나 그 이하로 운영할 수 있다.
경쟁 모델로 갈아탈 이유가 생겼나
이게 솔직히 가장 현실적인 질문이다. Anthropic이 구독 구조를 손대고 Fast Mode 6배 과금을 도입한 시점에서, 다른 모델로 이동하는 게 합리적인지 진지하게 고민해봐야 한다.
DeepSeek V4-Flash는 입력 기준으로 Claude Sonnet 4.6의 약 10분의 1 이하 가격이다. MIT 라이선스로 오픈 소스다. 코딩 벤치마크에서 경쟁력 있는 성능을 보인다. 단점은 중국 기업이라는 데이터 주권 이슈, SLA 수준, 그리고 레이턴시가 Anthropic에 비해 불안정할 수 있다는 점이다.
GPT-5.5는 Claude Opus 4.7과 가격이 비슷하다. SWE-bench 같은 코딩 벤치마크에서는 Opus 4.7에 밀린다. 굳이 갈아탈 경제적 이유가 없다.
Gemini 3.1 Flash는 가격 경쟁력이 있고 Google 인프라의 신뢰성을 갖는다. 한국어 처리 품질은 개선됐지만 복잡한 코드 추론에서 Opus 4.7보다 아직 한 단계 아래다.
내 권장안은 핵심 에이전트는 Claude API 유지, 볼륨이 많은 단순 태스크는 Haiku 또는 DeepSeek 혼용이다. 이미 LLM API 가격 비교에서 시나리오별로 상세 계산을 해뒀으니, 자신의 워크로드 패턴에 맞춰 비교해보길 권한다.
엔터프라이즈 사용자의 상황은 더 복잡하다
엔터프라이즈 계정 구조도 같은 시기에 바뀌었다. 기존에는 엔터프라이즈 계약으로 정해진 요금을 내면 일정 범위 내에서 사용량 상한이 유연했다. 2026년부터는 “결제를 비활성화할 수 없습니다”가 공식 정책이 됐다. 좌석당 $20 기본료에 모든 사용량이 표준 API 단가로 청구된다.
이게 어떤 의미냐면 — 대기업 IT팀이 부서별 Claude 사용량을 예산 범위 안에서 관리하기가 훨씬 어려워졌다는 것이다. 과거에는 월정액으로 예측 가능한 지출이 가능했다면, 이제는 에이전트 사용량 모니터링 없이는 분기 비용 예측이 불가능하다. 내가 이것을 “재정적 가시성 위기”라고 부르는 건 과장이 아니다.
실제로 OpenTelemetry를 통한 LLM 파이프라인 관측 가능성이 중요해진 것도 이 맥락에서다. 토큰 소비량, 모델별 비용, 캐시 적중률을 실시간으로 모니터링하지 않으면 청구서가 도착하기 전까지 비용을 알 수 없다. 에이전트가 다운됐을 때 수백만 토큰을 낭비하는 재시도 루프가 발생한 사례도 있었다.
엔터프라이즈 관점에서 지금 가장 중요한 것은 사용량 가시화 도구를 먼저 구축하는 것이다. Anthropic 콘솔의 Usage 탭은 기본 제공되지만, 팀별/프로젝트별로 세분화하려면 API 키를 분리하거나 별도 로깅 레이어를 추가해야 한다.
Anthropic Managed Agents는 진지한 대안인가
같은 시기에 공개 베타로 출시된 Managed Agents가 있다. 세션당 $0.08/시간 과금이다. 이게 얼마나 합리적이냐면 계산해보자.
에이전트 세션이 평균 20분이라면 세션당 $0.027이다. 500세션/일 × 30일 = 15,000세션이면 세션 비용만 $400이다. 여기에 토큰 비용은 별도다. 단, Managed Agents는 상태 관리, 툴 호출, 오류 복구, 세션 재시작 같은 인프라를 Anthropic이 처리해준다.
직접 에이전트 인프라를 운영할 때 드는 숨겨진 비용 — DevOps 시간, 모니터링 도구, 오류 알림, 세션 상태 저장 — 을 시간당 환산하면 $0.08/시간이 생각보다 비싸지 않을 수 있다. 개발자 인건비로 환산하면 시간당 최소 수만 원이고, 에이전트 인프라 운영에 월 20〜30시간을 쓴다면 Managed Agents로 완전히 떠넘기는 게 오히려 저렴할 수 있다.
다만 OpenClaw처럼 코드 수준의 자유도는 없다. 완전한 에이전트 프레임워크 대체제라기보다는 표준화된 에이전트 런타임에 가깝다. 나는 Managed Agents가 “에이전트 인프라를 빠르게 검증하고 싶은 팀”에게 적합하고, 이미 복잡한 커스텀 에이전트를 운영 중인 팀은 상당한 리팩토링 없이 전환하기 어렵다고 본다.
가장 현실적인 시나리오는 하이브리드다. 단순하고 표준화된 에이전트 태스크는 Managed Agents로 위임하고, 비즈니스 로직이 복잡한 핵심 에이전트는 API 직접 호출로 유지하는 것이다. 두 방식을 병행할 수 있도록 Anthropic 측에서도 설계했다는 인상을 받는다.
지금 당장 해야 할 것들
Anthropic의 이번 결정을 나쁘게만 보기는 어렵다. 구독 정액제를 AI 에이전트에 무한정 적용하는 건 구조적으로 지속 불가능하다. 그 점은 맞다.
아쉬운 것은 전환의 방식이다. 기존 사용자에게 충분한 유예 기간이 없었고, Fast Mode라는 고비용 기능을 동시에 풀면서 혼란을 증폭시켰다. “용량 보호”라는 논리와 “Fast Mode 6배 과금 도입”이 같은 달에 일어난 것은 우연이 아닐 것이다.
지금 실질적으로 해야 할 행동 목록:
즉시 (이번 주 안):
- OpenClaw나 서드파티 에이전트로 Claude Max를 구동하고 있다면 즉시 API 직접 과금 체계로 전환한다
- Fast Mode가 코드 어딘가에서 기본으로 켜져 있는지 확인하고 끈다
- 현재 월 토큰 소비량을 측정한다 — Anthropic 콘솔의 Usage 탭에서 확인 가능
단기 (이번 달 안):
- 모델 라우팅 레이어를 추가한다: 복잡도에 따라 Opus/Sonnet/Haiku를 분리한다
- 시스템 프롬프트와 반복 컨텍스트에 캐시 마커(
cache_control)를 추가한다 - 캐시 적중률 로깅을 설정하고 70% 이상을 목표로 한다
중기 (다음 분기 안):
- 실시간 응답이 필요 없는 배치 작업을 Batch API로 분리한다
- Managed Agents 베타를 테스트하고 자체 인프라 비용과 비교한다
- 경쟁 모델(DeepSeek, Gemini Flash)의 단순 태스크 품질을 자신의 워크로드로 벤치마크한다
이번 정책 전환이 불편한 건 사실이다. 하지만 결과적으로 “아무 생각 없이 Opus를 모든 곳에 쏟아붓던” 개발 패턴을 강제로 바로잡는 효과도 있다. 비용 의식 없는 에이전트 설계는 어차피 언젠가 문제가 됐을 테니까. 이번 기회에 에이전트 비용 구조를 한 번 제대로 들여다보는 것이, 불편하지만 나쁜 일만은 아닐 것이다.
다른 언어로 읽기
- 🇰🇷 한국어 (현재 페이지)
- 🇯🇵 日本語
- 🇺🇸 English
- 🇨🇳 中文
글이 도움이 되셨나요?
더 나은 콘텐츠를 작성하는 데 힘이 됩니다. 커피 한 잔으로 응원해주세요.
관련 글
-
Claude API Prompt Caching 실전 — LLM 비용 70% 절감하는 4가지 패턴
구독 차단 이후 API 비용을 줄이려면 프롬프트 캐싱이 핵심이다. 이 글에서 소개한 70% 캐시 최적화 패턴을 실제 수치와 함께 확인할 수 있다.

-
AI 에이전트 비용 vs 인건비의 현실: 8체 운용자의 솔직한 분석
AI 에이전트 비용이 인건비를 실제로 넘는 경우가 있다는 분석. 이번 Anthropic 정책 전환과 맞물려 에이전트 ROI를 다시 계산해야 할 이유가 된다.

-
LLM API 가격 비교 2026 — GPT-5 vs Claude vs Gemini vs DeepSeek 실제 비용 계산
GPT-5, Claude, Gemini, DeepSeek 가격을 시나리오별로 비교한 실측 데이터. Anthropic 구독이 막힌 지금, 경쟁 모델로의 전환 비용을 계산하는 데 직접 참고할 수 있다.
