Anthropic为何切断OpenClaw — Claude订阅政策转变与开发者成本现实
2026年4月4日,Anthropic封锁了Claude Pro/Max订阅用于第三方代理工具的使用权限。加上Fast Mode 6倍计费,这次结构性转变需要用数据来分析。
4月4日,Anthropic悄悄修改了服务条款。变更内容很简单:Claude Pro或Max订阅用户无法再使用订阅额度来驱动OpenClaw等第三方代理框架。从那天起,必须使用按量付费的API直接计费。
我最先是在OpenClaw社区看到这个消息的。起初以为”又是条款文字整理”,但实际算了一下数字,才发现这是个比想象中更大的故事。我用Python写了一个成本计算脚本,逐一跑了几个真实场景。结论先说:不做任何优化直接使用的话,最高涨价10倍;合理设计的话,反而比之前更便宜。
这篇文章是基于数据的分析。与其讨论Anthropic的决定是否道德,不如关注实际意味着多少钱、不同优化策略下数字如何变化,以及如果我处于这种情况下会如何应对。
Anthropic为何封锁订阅访问
Anthropic的官方立场是:“容量是我们谨慎管理的资源。“坦白说,这个理由是站得住脚的。
用$200的Claude Max订阅通过OpenClaw运行自主代理会发生什么呢——代理不是人类,不需要休息。一个自主工作流每分钟可以触发数十次API调用,每天24小时不间断。一个人每天用Opus进行几小时对话是一种使用模式,服务器24小时持续调用Opus是完全不同的使用模式。据报道,Anthropic的内部计算显示,这些用户每月消耗价值$1,000〜$5,000的算力,却只付$200的订阅费。我用自己的计算验证了这些数字——并不夸张。
500个会话/天,每个会话2,000输入 + 500输出令牌,用Opus 4.7跑30天:$337.50。已经超过$200 Max订阅的1.7倍。如果会话更长或更频繁,这个比例会快速上升。
OpenClaw创始人Peter Steinberger立即强烈反对。他表示切换到API单价会”代价高昂到无法承受”,并公开提出Anthropic是否在将OpenClaw的核心功能内化到自家产品后再切断外部访问的疑虑。开发者社区中也出现了”那就换DeepSeek或其他模型”的声音。
直说吧:我很难说Anthropic的决定完全错了。将固定价格订阅无限制地应用于AI代理在结构上是不可持续的。这一点是对的。我认为处理方式欠妥的是:没有给现有用户足够的过渡时间,以及在同一时间窗口推出Fast Mode这个显著更贵的选项。“保护容量”的逻辑与”6倍溢价层”同时出现,这种组合很难让人信服。
Fast Mode:6倍计费及其隐藏机制
Fast Mode值得单独分析,因为它不仅仅是速度升级那么简单。
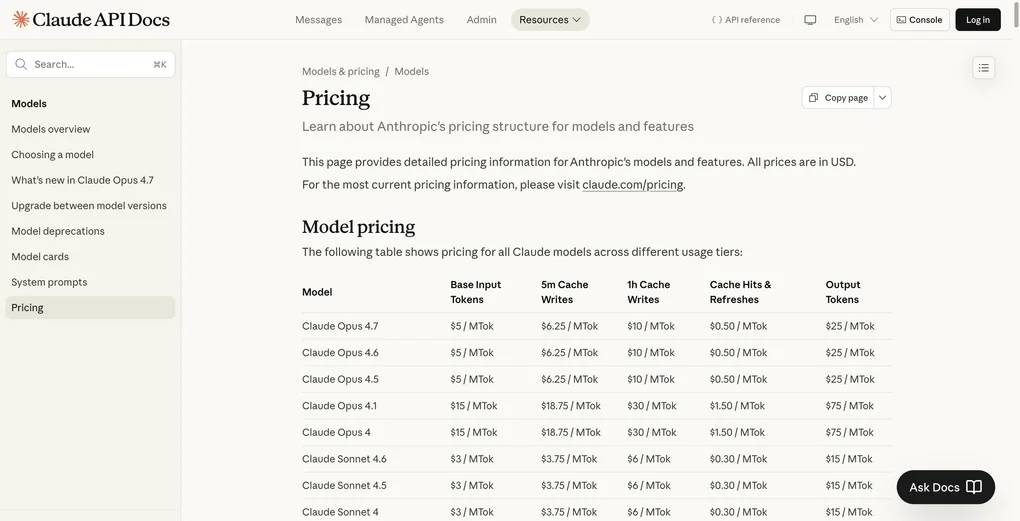
标准Claude Opus 4.7:每百万令牌输入$5,输出$25。Fast Mode:输入$30,输出$150——6倍。超过20万输入令牌后,输入价格升至$60。Anthropic称之为”高端速度功能的高端定价”。数字不需要太多评论。
更危险的部分是对话历史追溯计费。如果在对话进行到一半时开启Fast Mode,整个已积累的上下文都会按Fast Mode价格追溯计费。在一次长对话之后无意中开启Fast Mode,或者代码中的条件分支错误地触发了Fast Mode,账单就会以不可预测的方式飙升。
另一个重要限制:Fast Mode在AWS Bedrock、Google Vertex AI或Microsoft Azure Foundry上不可用,仅适用于Anthropic直接API。通过云平台集成运行Claude的组织根本无法使用此功能。
我的判断:Fast Mode是一个适用于特定场景的工具——当用户正在等待、延迟直接影响业务KPI的交互式UI。用于自动化代理时默认开启在经济上是不负责任的。
实际成本计算:按场景分析
我用Python脚本,基于platform.claude.com的官方价格表验证了以下数字。
场景1:重度OpenClaw用户(每天500个会话,原订阅$200/月)
假设:每个会话2,000输入 + 500输出令牌,30天
Opus 4.7标准(无优化): $337.50/月
Opus 4.7 Fast Mode(6倍): $2,025.00/月
Opus 4.7 + 70%缓存命中率: $243.00/月
Sonnet 4.6 + 70%缓存命中率: $145.80/月
Haiku 4.5 + 70%缓存命中率: $48.60/月
与$200 Max计划相比倍数: 1.7x〜10.1x最差情况(Fast Mode无防护)是涨价10倍。但降级到Sonnet 4.6并将缓存命中率提高到70%,就能达到$145.80——比原来的$200 Max计划还便宜。使用Haiku同样优化后:$48.60。
场景2:中等规模开发者(每天50个会话——博客自动化、文档分析等)
Sonnet 4.6 无优化: $20.25/月
80%缓存命中率: $13.77/月
缓存 + Batch API: $6.88/月在这个规模下,订阅封锁实际上降低了成本。如果你用Claude Max主要是跑博客自动化,API直接计费要便宜得多。
场景3:按每日会话量估算成本(Sonnet 4.6,75%缓存,Batch API)
10个会话/天 → $1.42/月
50个会话/天 → $7.09/月
100个会话/天 → $14.18/月
500个会话/天 → $70.88/月
1000个会话/天 → $141.75/月这张表说明了一件事:如果你还不知道实际的每日会话量,首先需要做的就是埋点监控。凭借”请求很多”的模糊感觉来预测成本已经行不通了。
Claude API提示缓存优化模式有详细的实现方法。将缓存命中率提升到70〜80%是目前性价比最高的改变。
降低成本的3个实用策略
策略1:模型分层路由
最有影响力的单项改变:停止把所有任务都发送给Opus 4.7。一个根据任务类型选择合适模型的路由层可以在不明显影响质量的情况下降低40〜60%的成本。
def route_to_model(task_type: str) -> str:
"""根据复杂度路由到合适的模型层"""
routing = {
# 复杂推理、代码生成 — 值得使用Opus
"code_generation": "claude-opus-4-7",
"complex_reasoning": "claude-opus-4-7",
"multi_step_agent": "claude-opus-4-7",
# 中等复杂度 — Sonnet是正确选择
"summarization": "claude-sonnet-4-6",
"translation": "claude-sonnet-4-6",
"draft_review": "claude-sonnet-4-6",
# 简单分类和路由 — Haiku完全够用
"classification": "claude-haiku-4-5-20251001",
"routing": "claude-haiku-4-5-20251001",
"simple_extraction": "claude-haiku-4-5-20251001",
}
return routing.get(task_type, "claude-sonnet-4-6")策略2:积极使用提示缓存
系统提示、RAG文档等重复使用的上下文元素可以添加缓存标记,使输入令牌成本降低90%。5分钟的TTL意味着即使是高频工作流也有效。
如AI代理成本现实分析所述,代理成本超过人工成本最常发生在团队全面使用Opus且没有缓存的情况下。监控缓存命中率是成本可视化的第一步。
策略3:非实时工作负载使用Batch API
Batch API可以让所有成本降低50%。代价是结果在24小时内返回,而非立即返回。对于文档分析、翻译、夜间报告生成和分类批处理来说,这是直接可以采用的方法。
import anthropic
client = anthropic.Anthropic()
batch = client.messages.batches.create(
requests=[
{
"custom_id": f"task-{i}",
"params": {
"model": "claude-sonnet-4-6",
"max_tokens": 1024,
"messages": [{"role": "user", "content": doc}]
}
}
for i, doc in enumerate(documents_to_process)
]
)
print(f"批次ID: {batch.id}")这三种策略组合在一起——模型路由 + 70〜80%缓存 + 批处理非实时任务——可以将大多数自动化代理工作负载控制在原来$200固定计划的成本水平或以下。
企业用户的情况更加复杂
企业账户结构也在同期发生了变化。以前企业合同允许使用量上限有一定弹性。从2026年起,“您无法禁用使用计费”成为官方政策。每个席位$20基本费用,所有使用量按标准API费率在此基础上计费。
这意味着:大型团队无法在没有实时使用量监控的情况下以可预测的固定月度Claude成本运营。不对代理使用量进行逐团队、逐项目的可视化,就是在盲目飞行。有记录显示代理进入错误重试循环,在有人注意到之前就消耗了数百万令牌。
是时候切换到竞争模型了吗
这是最实际的问题。
DeepSeek V4-Flash的输入定价约为Claude Sonnet 4.6的十分之一或更低。MIT许可证,开源。在编码基准测试中表现出竞争力。缺点是:中国公司带来的数据主权问题,SLA水平无法与Anthropic相比,延迟稳定性可能较差。
GPT-5.5定价与Claude Opus 4.7相近,但在SWE-bench等编码基准测试中逊于Opus 4.7。没有强烈的经济理由切换。
我的建议:核心代理保留Claude API,高量简单任务使用Haiku或DeepSeek混合。LLM API价格比较中已经按场景做了详细计算,可以参照自己的工作负载模式进行比较。
Anthropic Managed Agents是认真的替代方案吗
同期以公开测试版发布的Managed Agents按每会话$0.08/小时计费,另加令牌费用。算一算:平均20分钟的会话,每个会话$0.027。500个会话/天 × 30天 = 15,000个会话 = 仅会话费就$400/月,然后还有令牌费用。换来的是Anthropic处理状态管理、工具调用、错误恢复和会话重启。
自己运营代理基础设施的隐性成本——DevOps时间、监控工具、错误告警、会话状态存储——折算成每小时,$0.08/小时可能没那么贵。如果你的团队每月花20〜30小时维护代理基础设施,Managed Agents可能在总拥有成本上更划算。
我认为Managed Agents适合”想快速验证代理工作流的团队”,而不适合已经在运行复杂自定义代理的团队,后者切换需要大量重构。最现实的方案可能是混合模式。
现在该做什么
Anthropic的决定不是非黑即白的错误。将固定订阅无限制地应用于AI代理在结构上是不可持续的。这一点是对的。
处理方式留下了很多遗憾:没有给现有用户充分的过渡时间,同时推出Fast Mode溢价层进一步放大了混乱。
立即行动(本周内):
- 如果在用第三方代理框架驱动Claude Max,立即切换到API直接计费体系
- 检查代码库中是否有默认开启Fast Mode的地方并关闭它
- 在Anthropic控制台的使用情况标签中查看实际的月度令牌消耗量
短期行动(本月内):
- 添加模型路由层:按任务复杂度分别使用Opus/Sonnet/Haiku
- 为系统提示和重复上下文添加
cache_control标记 - 设置缓存命中率日志记录,目标70%以上
中期行动(下个季度内):
- 将非实时批处理工作迁移到Batch API
- 测试Managed Agents测试版,与自有基础设施成本进行比较
- 用实际工作负载对竞争模型(DeepSeek、Gemini Flash)进行基准测试
这次政策变化令人不快是事实。但它也强制解答了一个本应更早被问到的问题:为什么每个代理任务都用Opus?这真的是正确的选择吗?能把这次变化作为基础设施审计时机的开发者,最终会处于更好的位置。
阅读其他语言版本
- 🇰🇷 한국어
- 🇯🇵 日本語
- 🇺🇸 English
- 🇨🇳 中文(当前页面)
这篇文章有帮助吗?
您的支持能帮助我创作更好的内容。请我喝杯咖啡吧。


